[논문리뷰] - Learning Deep Features for Discriminative Localization, CVPR 2016
이미지 분야에서 자주 쓰이는 딥러닝 네트워크의 순위를 매기면 항상 상위권에 위치한 모델이 바로 Convolution Neural Network(CNN)입니다. 이 CNN 구조가 나온 이후로 다양한 모델에 적용되면서 이미지 딥러닝 분야는 꾸준히 발전하고 있습니다. 그 이유는 CNN이 이미지의 지역적 특징을 잘 포착하기 때문입니다.

오늘 포스팅은 CNN을 이용하여 지역적 특징을 잘 포착하는지 여부에 대해 해석(시각화)이 가능한 방법 를 제시한 논문을 리뷰하도록 하겠습니다. 이 글은 Learning Deep Features for Discriminative Localization 논문 을 참고하여 정리하였음을 먼저 밝힙니다. 논문 그대로를 리뷰하기보다는 생각을 정리하는 목적으로 제작하고 있기 때문에 실제 내용과 다른점이 존재할 수 있습니다. 혹시 제가 잘못 알고 있는 점이나 보안할 점이 있다면 댓글 부탁드립니다.
Short Summary
이 논문의 큰 특징 3가지는 아래와 같습니다.
- Global Average Pooling(GAP) 를 적용하여 해석(시각화)가 가능한 구조를 제시합니다.
- Feature Map에서 객체의 위치를 추출하는 방법인 Class Activation Mapping(CAM) 을 제시합니다.
- 다양할 실험을 통해 논문에서 주장하는 구조와 객체 추출 방법이 객체 인식에 좋은 성능을 갖고 있음을 증명합니다.
모델 구조
일반적인 분류 모델 구조
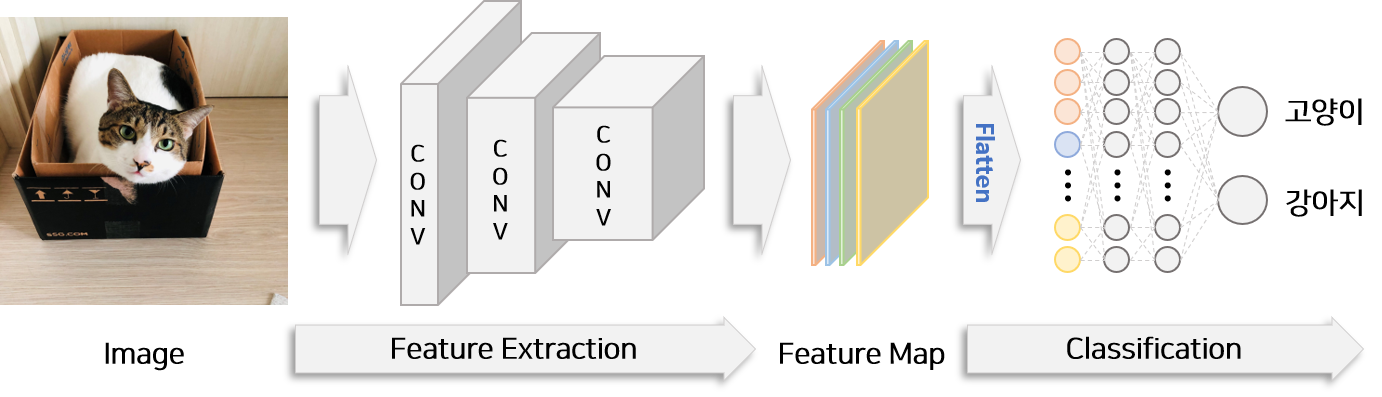
일반적인 이미지 분류 모델의 구조를 간단하게 위 그림에서 표현하였습니다. 모델의 구조는 크게 특징을 추출하는 Feature Extraction 단계와 추출된 특징을 이용하여 이미지를 분류하는 Classification 단계로 구분됩니다. Feature Extraction을 통해 생성된 Feature Map은 3차원 벡터(채널,가로,세로)이므로 이를 2차원 벡터(채널,특징)로 변경하는 Flatten 단계를 수행하여 Classification 단계의 Input으로 활용합니다. Classification 단계는 여러층의 Fully Connected Layer(FC Layer)로 구성되어 있으며 마지막 FC Layer에서 이미지를 분류합니다. Feature Extraction 단계에서 추출한 Feature Map은 여러층의 FC Layer를 통과할 때 위치정보가 소실되므로 이 구조는 객체의 위치정보를 추출할 수 없습니다.
객체 위치 추출이 가능한 모델 구조
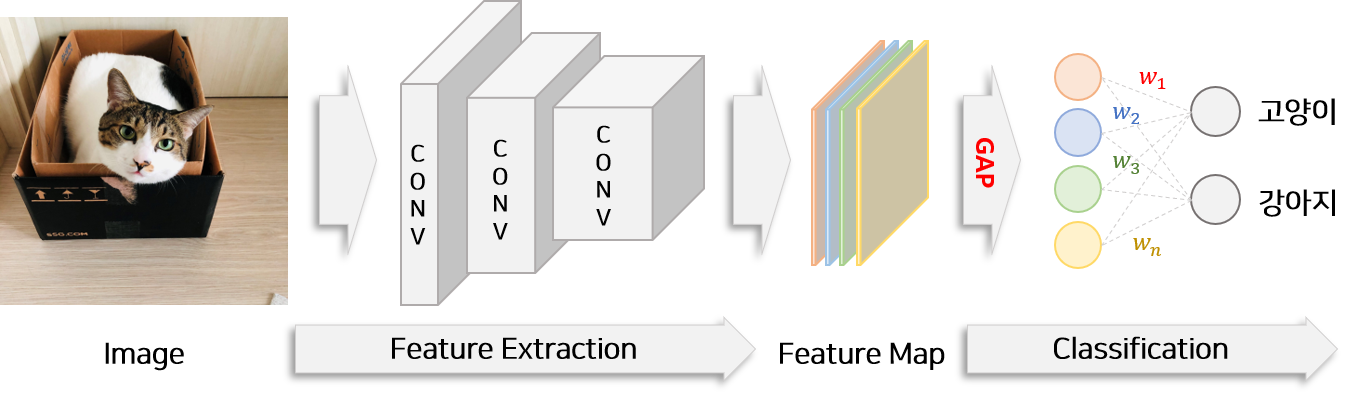
카테고리 정보만을 학습하여 모델이 객체의 위치 추출 능력을 갖추기 위하여 본 논문에서는 Flatten 단계에서 Global Average Pooling(GAP) 방법을 사용해야 한다고 주장합니다. Global Average Pooling(GAP)은 각 Feature Map($f_k(x,y)$)의 가로 세로 값을 모두 더하여 1개의 특징변수($F_k$)로 변환하는 것을 의미합니다. 예를들어 위 그림에서는 총 4개의 Feature Map이 존재하므로 총 4개의 특징변수가 생성됩니다. 또한 Fully Connected Layer의 수를 줄이고 마지막 Classification Layer 하나만을 이용하여 모델을 구성합니다.
$f_k(x,y)$ : Feature Map k의 가로($x$), 세로($y$)에 해당하는 값
$F_k$ : 특징변수 $k$
$k$ : Feature Map의 index
$x, y$ : Feature Map의 가로, 세로 좌표
$w_k^c$ 특징변수 $k$가 클래스 $c$에 기여하는 weight
이 특징변수($F_k$)와 FC Layer의 Weight($w_k^c$)를 곱하여 더하면 각 클래스의 점수($S_c$)를 계산할 수 있습니다. 각 특징변수에 곱해진 Weight는 각 Feature Map이 해당 클래스에 얼마나 기여하는 지를 나타냅니다. 마지막으로 클래스 점수에 SoftMax 함수를 취하면 각 클래스로 분류될 확률($P_c$)을 계산할 수 있습니다.
Class Activation Mapping(CAM)
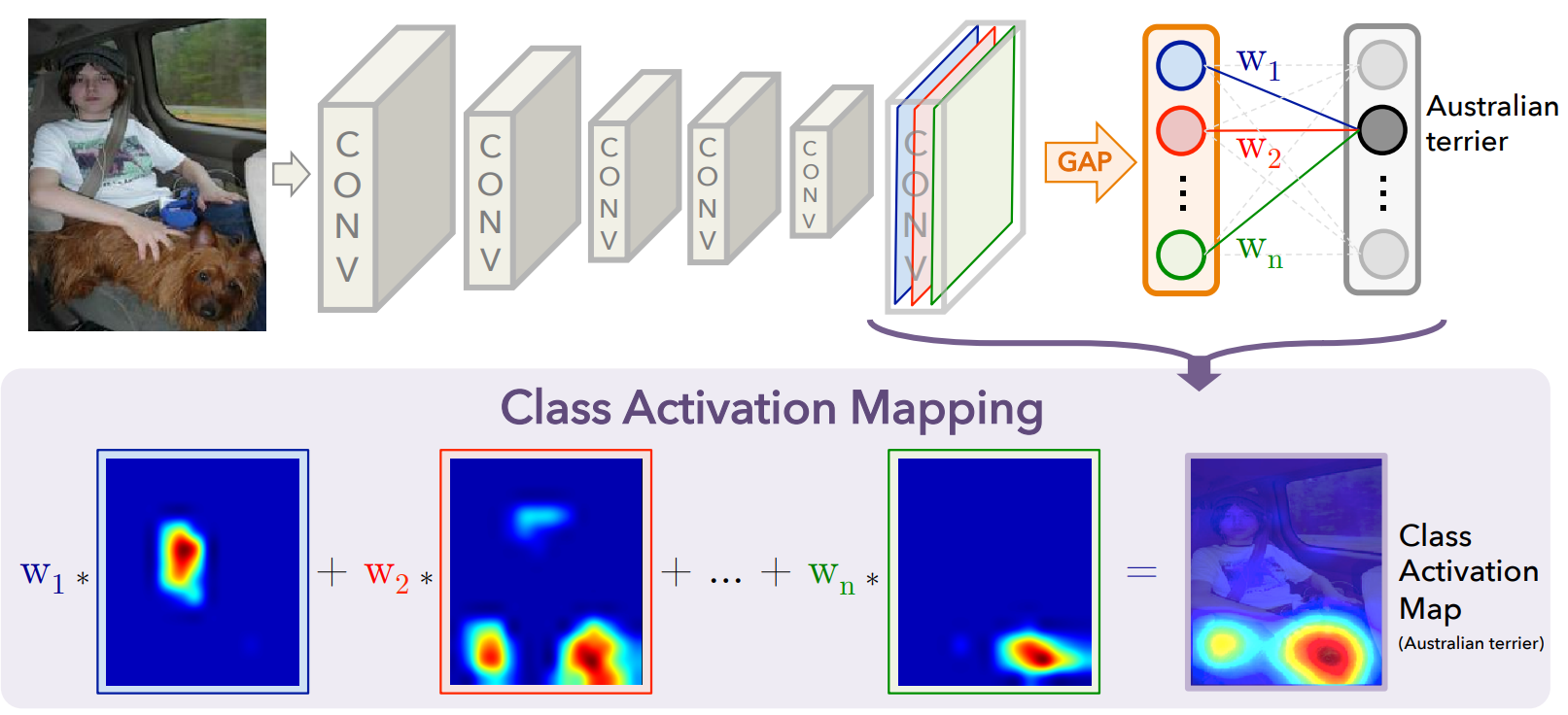
위 식을 응용하면 각 클래스로 분류될 확률에 영향을 미친 객체의 좌표($x,y$)를 추출할 수 있습니다.
$M_c(x,y)$ : 클래스 $c$에 대하여 좌표 $x$, $y$에 대한 영향력(Activation Value)
각 Feature Map($f_k(x,y)$)과 Feature Map이 특정 클래스 $c$로 분류될 가중치($w_k^c$)를 곱하여 합하면 좌표 별($x,y$) 특정 클래스에 대한 영향력(Class Activation)인 $M_c(x,y)$를 계산할 수 있습니다. 이를 Class Activation Mapping(CAM)이라고 부릅니다. 각 클래스에 대해 CAM을 적용하면 이미지에서 클래스에 영향을 주는 좌표을 추출할 수 있습니다.

고양이 줄리 사진을 모델로 분류하면 ‘이집트 고양이’일 확률이 0.98, ‘타이거 상어’일 확률이 0.01 입니다. 고양이 줄리 사진을 ‘이집트 고양이’ 클래스에 대한 CAM과 ‘타이거 상어’ 클래스에 대한 CAM을 만들어 시각화하면 위 그림과 같습니다. ‘이집트 고양이’에 대한 객체의 좌표를 잘 찾는 반면 ‘타이거 상어’ 클래스에 대한 개체의 좌표는 또렷히 표시되지 않습니다. 즉 CAM 시각화를 통해 알 수 있는 사실은 본 논문에서 제안한 구조는 각 클래스에 대해 객체의 좌표를 추출할 수 있으며 객체가 뚜렷이 추출된 클래스를 분류하는 기능을 갖고 있다는 것 입니다.
Global Average Pooling(GAP)
[이전 논문(CVPR 2015)] 에서 Global Max Pooling(GMP) 가 제시 되었습니다. Global Max Pooling(GMP)은 각 Feature Map 에서 가장 값이 큰 값을 추출하는 방법입니다. GMP, GAP 두 방법을 적용했을 때 분류(Classification) 정확도 비슷합니다. 하지만 Feature Map에서 하나의 뚜렷한 특징을 찾아내는 GMP를 적용했을 때와 전체적으로 뚜렷한 특징이 있는지를 확인할 수 있는 GAP를 적용했을 때 객체 추출(Localization) 능력은 크게 차이가 난다고 논문에서 실험적으로 증명합니다.
실험 및 결과
[1] Weakly-supervised Object Localization
실험내용
본 논문에서는 ILSVRC 2014 Benchmark 데이터에서 모델의 성능을 평가하기 위하여 총 2가지 실험을 진행합니다.
- 논문에서 제시한 구조를 적용할 때 기존 모델의 분류(Classification) 정확도가 하락하는지 여부를 확인합니다.
- 분류문제를 학습한 모델의 CAM을 활용하여 Bounding Box를 만들고 객체를 추출(Localization) 정확도를 확인합니다.
실험모델로 성능이 검증된 모델 AlexNet, VGGnet, GoogLeNet의 구조를 변경하여 활용합니다. 모델이름 끝에 GAP 가 표시된 것이 논문에서 제시한 실험모델입니다. GAP(Global Average Pooling)를 적용한 모델과 GMP(Global Max Pooling) 적용한 모델도 함꼐 비교하며 Pooling 방법에 대한 성능을 비교실험으로 확인합니다.
실험결과
1.1) 분류 실험(Classification)
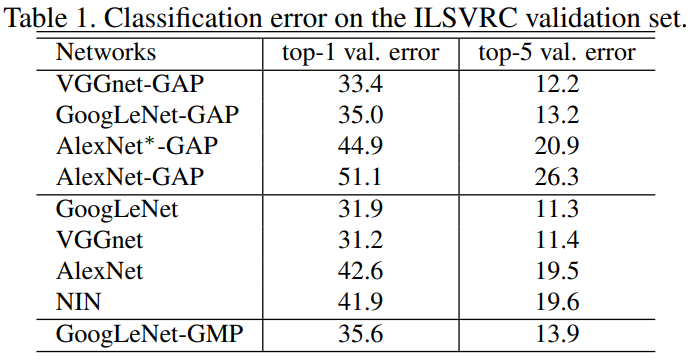 논문에서 제시한 구조를 사용했을 때 각 분류 모델의 정확도가 1%~2% 미미하게 하락하는 것을 확인할 수 있습니다.
논문에서 제시한 구조를 사용했을 때 각 분류 모델의 정확도가 1%~2% 미미하게 하락하는 것을 확인할 수 있습니다.
1.2) 객체 추출 실험(Localization)
객체 추출 평가점수는 Ground Truth Bounding Box와 모델에서 추출된 Bounding Box의 IOU(Intersection over Union)를 통해 계산됩니다. 실험모델은 CAM을 통해 각 좌표의 값을 추출할 수 있습니다. 따라서 특정 Threshold를 정하고 Threshold를 넘는 좌표 중 연결된 부분이 모두 포함될 수 있도록 Bounding Box를 만들어 객체 추출 실험에 활용합니다.
 실험결과 제시한 모델은 다양한 Fully-supervised 방법보다 낮은 성능을 보이고 있습니다.
다만 제시한 모델은 Bounding Box 없이 학습했다는 점을 고려하면 좋은 성능을 보이고 있다고 평가할 수 있습니다.
게다가 휴리스틱 방법을 통해 더 높은 성능을 획득한 것을 통해 다양한 후처리 방법을 통해 실험모델의 성능을 끌어올릴 수 있는 여지가 있습니다.
실험결과 제시한 모델은 다양한 Fully-supervised 방법보다 낮은 성능을 보이고 있습니다.
다만 제시한 모델은 Bounding Box 없이 학습했다는 점을 고려하면 좋은 성능을 보이고 있다고 평가할 수 있습니다.
게다가 휴리스틱 방법을 통해 더 높은 성능을 획득한 것을 통해 다양한 후처리 방법을 통해 실험모델의 성능을 끌어올릴 수 있는 여지가 있습니다.
[2] Pattern Discovery
실험내용
이미지에서 물체를 추출하는 것 이외에 행위와 같은 모호한 패턴에 대한 개념도 잘 추출하는지에 대해 실험을 진행합니다.
- 다양한 객체가 포함된 20개의 카테고리 이미지를 학습하고 각 카테고리로 부터 비슷한 객체가 추출되는지를 확인합니다.
- 추상적인 설명과 이미지로부터 패턴을 추출할 수 있는지 여부를 확인합니다.
- CAM 방법을 이용하여 텍스트를 포착할 수 있는지 여부를 확인합니다.
- 질문과 대답을 이용하여 학습한 후 CAM을 통해 시각화 하였을 때 대답이 있는 부분을 잘 포착하는지 확인합니다.
실험결과
2.1) Discovering informative objects in the scenes
 비슷한 카테고리를 갖고 있는 이미지에서는 비슷한 객체가 주로 추출됩니다.
예를 들어 화장실 이미지에서 실험모델의 분류확률이 높은 객체 TOP6를 나열하면 실크, 욕탕 등이 일관적으로 주로 추출됩니다.
비슷한 카테고리를 갖고 있는 이미지에서는 비슷한 객체가 주로 추출됩니다.
예를 들어 화장실 이미지에서 실험모델의 분류확률이 높은 객체 TOP6를 나열하면 실크, 욕탕 등이 일관적으로 주로 추출됩니다.
2.2) Concept localization in weakly labeled images
 추상적인 설명이 제공된 이미지로 학습한 모델도 해당 정보가 포함된 위치를 잘 포착합니다.
추상적인 설명이 제공된 이미지로 학습한 모델도 해당 정보가 포함된 위치를 잘 포착합니다.
2.3) Weakly supervised text detector
 글자가 있는 이미지를 Positive, 글자가 없는 이미지를 Negative로 설정하고 학습시켰을 때 CAM 방법을 이용하여 이미지로부터 글자를 추출할 수 있는지를 확인하는 실험입니다.
Bounding Box를 이용하지 않았음에도 글자 부분을 잘 포착하는 것을 확인할 수 있습니다.
글자가 있는 이미지를 Positive, 글자가 없는 이미지를 Negative로 설정하고 학습시켰을 때 CAM 방법을 이용하여 이미지로부터 글자를 추출할 수 있는지를 확인하는 실험입니다.
Bounding Box를 이용하지 않았음에도 글자 부분을 잘 포착하는 것을 확인할 수 있습니다.
2.4) Interpreting visual question answering

질문과 이미지를 넣고 대답을 예측하도록 모델을 학습한 뒤 CAM 방법을 이용하여 이미지로부터 대답에 해당하는 물체의 위치를 추출할 수 있는지를 확인하는 실험입니다.
대답에 해당하는 물체의 위치를 잘 포착하는 것을 확인할 수 있습니다.
결론 및 개인적인 생각
간단한 구조 변경으로 다양한 TASk(Classification, Localization)를 수행할 수 있는 방법을 제시한 효과적인 논문입니다. 다양한 실험을 통해 논문에서 주장한 구조의 장점을 명료하게 파악할 수 있으며, 부가적으로 CNN(Convolution Neural Network)의 작동 방식을 직관적으로 이해할 수 있었습니다. ResNet의 경우 논문에서 제안한 구조로 구성되어 있어 이미 학습된 모델을 이용하여 실험해 볼 수 있어서 CAM을 바로 활용할 수 있는 장점을 갖고 있습니다.
구현
ResNet은 Global Average Pooling 구조가 반영된 이미지 분류기 입니다. Pytorch 기본 라이브러리에서 ImageNet을 이용하여 Pre-trained ResNet을 제공하고 있으므로 추가 학습 없이 바로 CAM(Class Activation Mapping)을 적용할 수 있습니다. [TUTORIAL 파일] 은 해당 링크에서 다운받을 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
import torch
from torchvision import datasets, models, transforms
import torch.nn.functional as F
from PIL import Image
from matplotlib import pyplot as plt
import urllib.request
import ast
import numpy as np
import cv2
## 이미지 경로 설정
img_path = 'cat.jpg'
## Resnet은 ImageNet에서 Training 되었으므로 image Net의 class 정보를 가져옵니다.
classes_url = 'https://gist.githubusercontent.com/yrevar/942d3a0ac09ec9e5eb3a/raw/238f720ff059c1f82f368259d1ca4ffa5dd8f9f5/imagenet1000_clsidx_to_labels.txt'
## class 정보 불러오기
with urllib.request.urlopen(classes_url) as handler:
data = handler.read().decode()
classes = ast.literal_eval(data)
## Resnet 불러오기
model_ft = models.resnet18(pretrained=True)
model_ft.eval()
## Imagenet Transformation 참조
## https://github.com/pytorch/examples/blob/42e5b996718797e45c46a25c55b031e6768f8440/imagenet/main.py#L89-L101
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
preprocess = transforms.Compose([
## Resize는 사용하지 않고 원본을 추출
transforms.Resize((224,224)),
transforms.ToTensor(),
normalize
])
## 그림을 불러옵니다.
raw_img = Image.open(img_path)
## 이미지를 전처리 및 변형
img_input = preprocess(raw_img)
## 모델 결과 추출
output = model_ft(img_input.unsqueeze(0))
## 클래스 추출
softmaxValue = F.softmax(output)
class_id=int(softmaxValue.argmax().numpy())
## Resnet 구조 참고
## https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
def get_activation_info(self, x):
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x
## Feature Map 추출
feature_maps = get_activation_info(model_ft, img_input.unsqueeze(0)).squeeze().detach().numpy()
## Weights 추출
activation_weights = list(model_ft.parameters())[-2].data.numpy()
## numpy로 이미지 변경
numpy_img = np.asarray(raw_img)
def show_CAM(numpy_img, feature_maps, activation_weights, classes, class_id):
## CAM 추출
cam_img = np.matmul(activation_weights[class_id], feature_maps.reshape(feature_maps.shape[0], -1)).reshape(feature_maps.shape[1:])
cam_img = cam_img - np.min(cam_img)
cam_img = cam_img/np.max(cam_img)
cam_img = np.uint8(255 * cam_img)
## Heat Map으로 변경
heatmap = cv2.applyColorMap(cv2.resize(255-cam_img, (numpy_img.shape[1], numpy_img.shape[0])), cv2.COLORMAP_JET)
## 합치기
result = numpy_img * 0.5 + heatmap * 0.3
result = np.uint8(result)
fig=plt.figure(figsize=(16, 8))
## 원본 이미지
ax1 = fig.add_subplot(1, 2, 1)
ax1.imshow(numpy_img)
## CAM 이미지
ax2 = fig.add_subplot(1, 2, 2)
ax2.imshow(result)
plt.suptitle("[{}] CAM Image".format(classes[class_id]), fontsize=30)
plt.show()
show_CAM(numpy_img, feature_maps, activation_weights, classes, class_id)

Reference
- [PAPER] Learning Deep Features for Discriminative Localization, CVPR 2016
- [BLOG] Learning Deep Features for Discriminative Localization, Youngerous
- [GITHUB] Sample code for the Class Activation Mapping, zhoubolei