[코드리뷰] - Unsupervised Learning of Video Representations using LSTMs, ICML 2015
비디오는 여러개의 이미지 프레임으로 이루어진 sequence 데이터 입니다. 따라서 비디오 데이터는 한개의 이미지로 이루어진 데이터보다 큰 차원을 다루므로 학습에 많은 비용이 필요하며 한정적인 labeled 데이터만으로 학습하기 어렵습니다. 이를 해결하기 위하여 unlabeled 데이터를 활용하여 일련의 데이터를 학습하는 unsupervised 방법이 필요합니다.
AutoEncoder는 원본데이터를 특징백터(feature)로 압축하고 복원(reconstruction)하는 방법으로 학습하기 때문에 labeled 데이터 없이 학습이 가능한 unsupervised 방법입니다.
오늘 포스팅할 논문은 AutoEncoder에 LSTM 구조를 추가하여 sequence 데이터를 Self-Supervised 방법으로 학습하는 LSTM AutoEncoder 입니다.
이 글은 Unsupervised Learning of Video Representations using LSTMs 논문 을 참고하여 정리하였음을 먼저 밝힙니다. 논문을 간단하게 리뷰하고 pytorch 라이브러리를 이용하여 코드를 구현한 후 자세하게 설명드리겠습니다. 혹시 제가 잘못 알고 있는 점이나 보안할 점이 있다면 댓글 부탁드립니다.
Short Summary
이 논문의 큰 특징 3가지는 아래와 같습니다.
- 비디오와 같은 sequence 데이터를 학습할 수 있는 Self-Supervised 방법을 제시합니다.
- 비디오 데이터로부터 이미지의 모습과 이미지의 이동 방향 등의 정보를 담고 있는 feature 벡터를 추출할 수 있습니다.
- 이미지 복원(reconstruction) 문제와 이미지를 예측(prediction) 문제를 함께 수행하여 sequence 데이터를 효율적으로 활용하는 구조를 제시합니다.
모델 구조
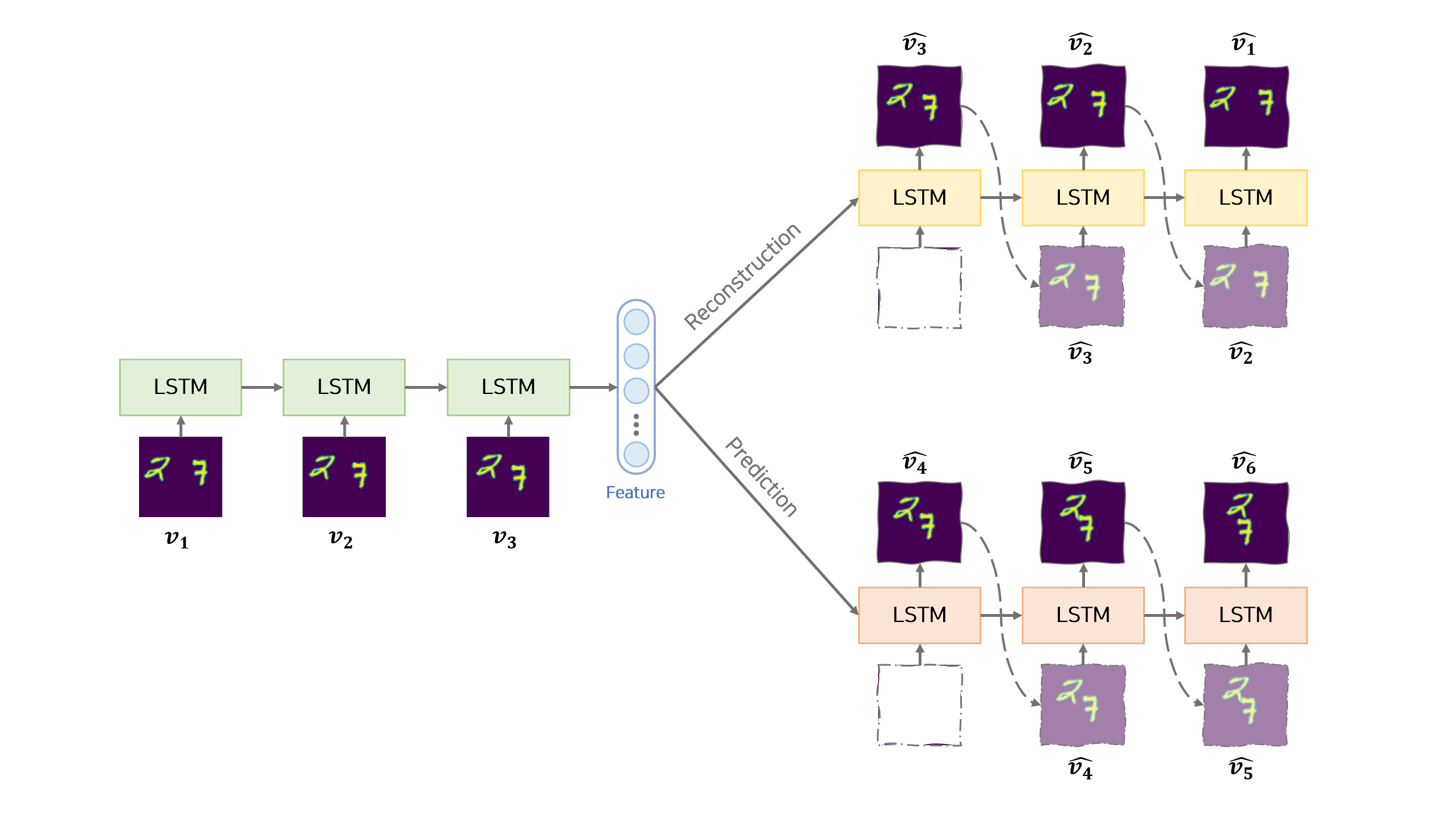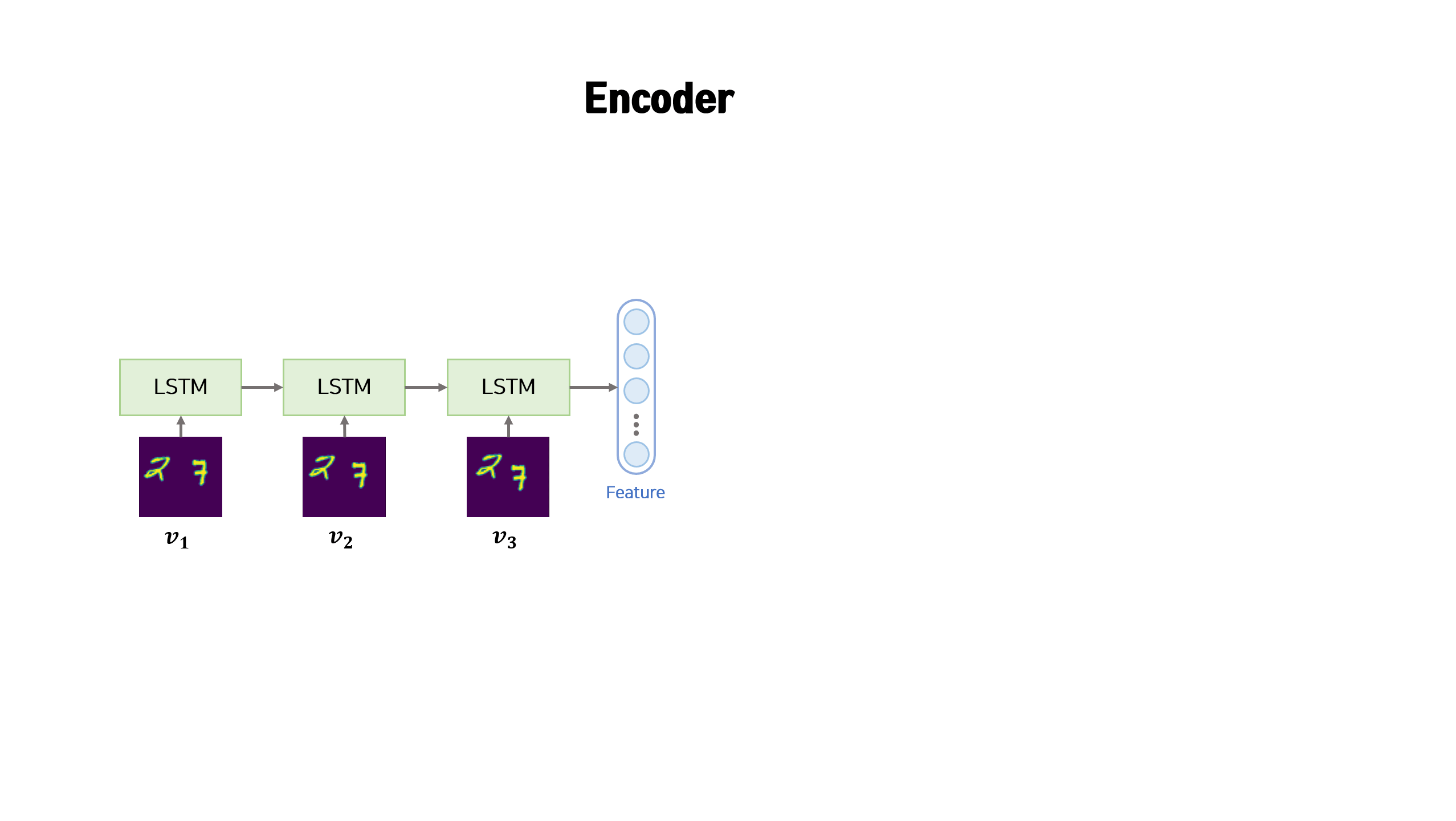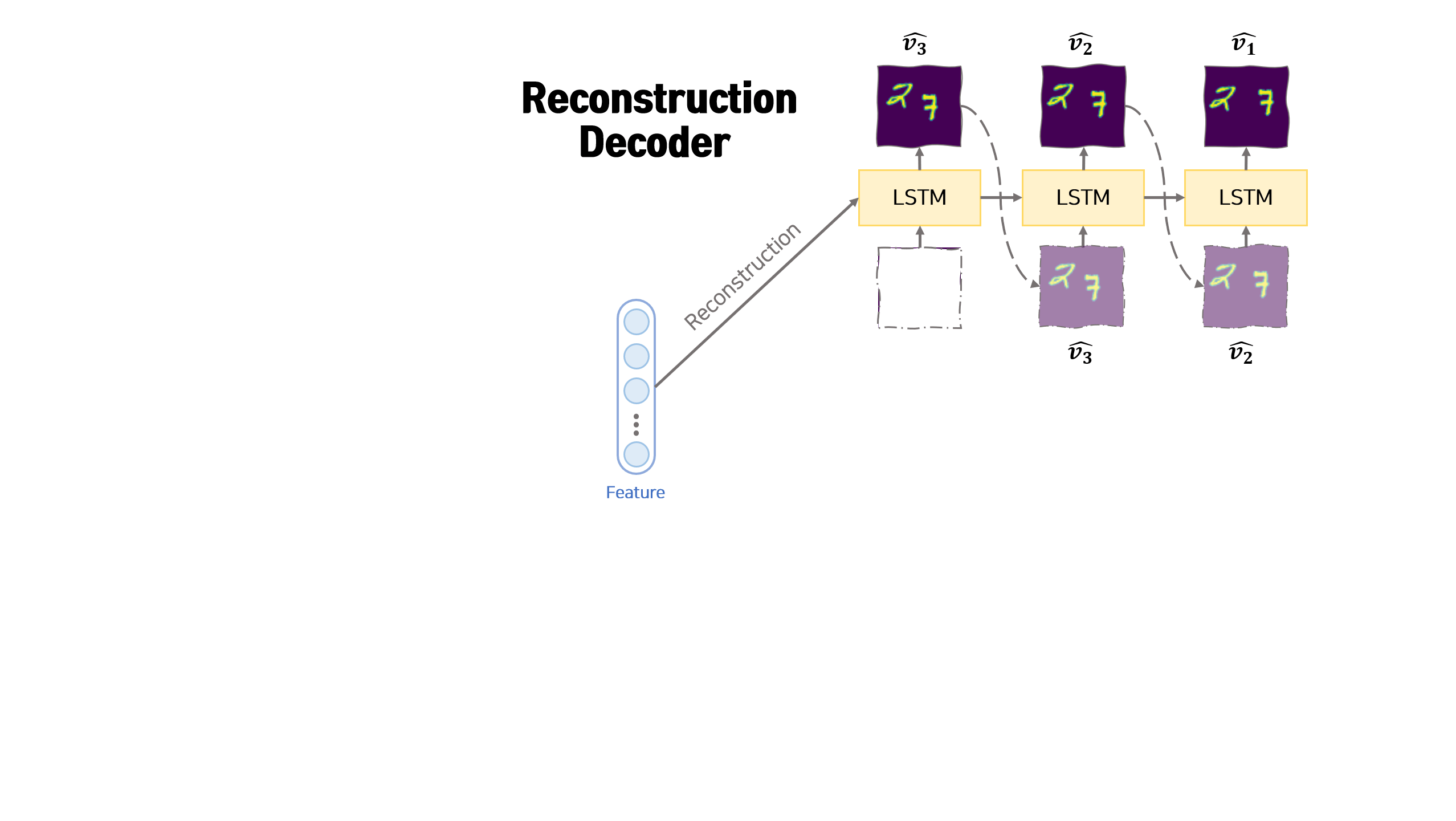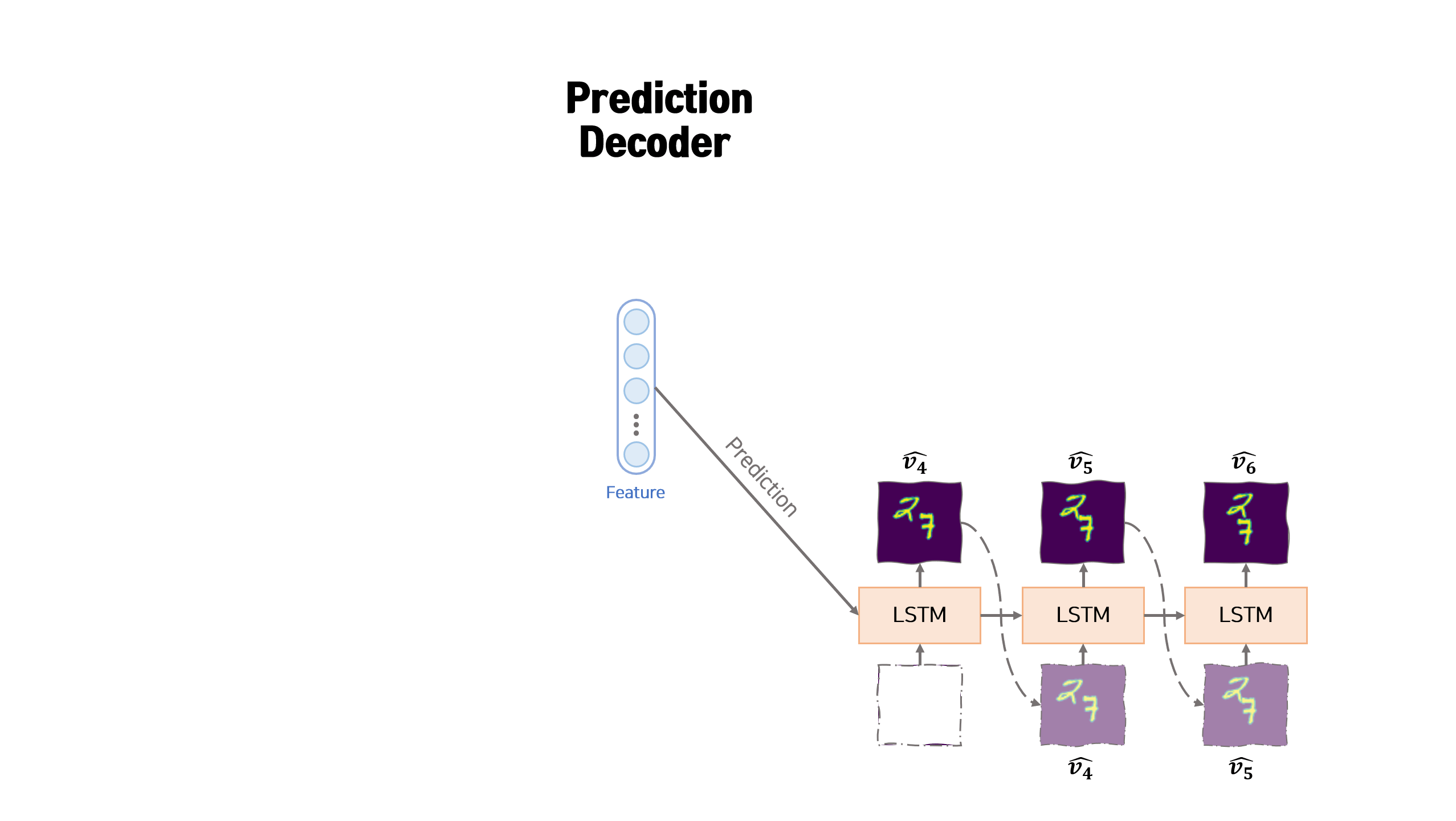
모델은 Encoder, Reconstruction Decoder, Predict Decoder 로 구성됩니다. Encoder에서 이미지 sequence를 압축하고 Reconstruction Decoder에서 이미지 sequence를 복원하는 방식으로 AutoEncoder의 학습방법과 유사합니다. Prediction Decoder는 Encoder에서 압축된 feature를 이용하여 이후에 나올 이미지 sequence를 생성하는 방식으로 학습합니다.
[1] Encoder
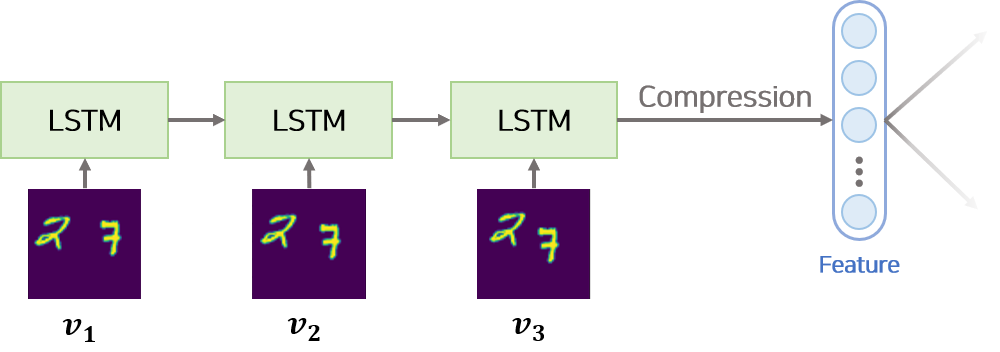
Encoder는 sequence 데이터를 압축하는 LSTM 모듈입니다. sequence 데이터는 차례대로 LSTM 모듈의 input으로 사용되어 feature 벡터로 변환됩니다. feature 벡터는 sequence 데이터를 압축한 형태로 이미지의 모습과 이미지의 이동방향 등의 정보가 포함되어 있습니다.
[2] Reconstruction Decoder
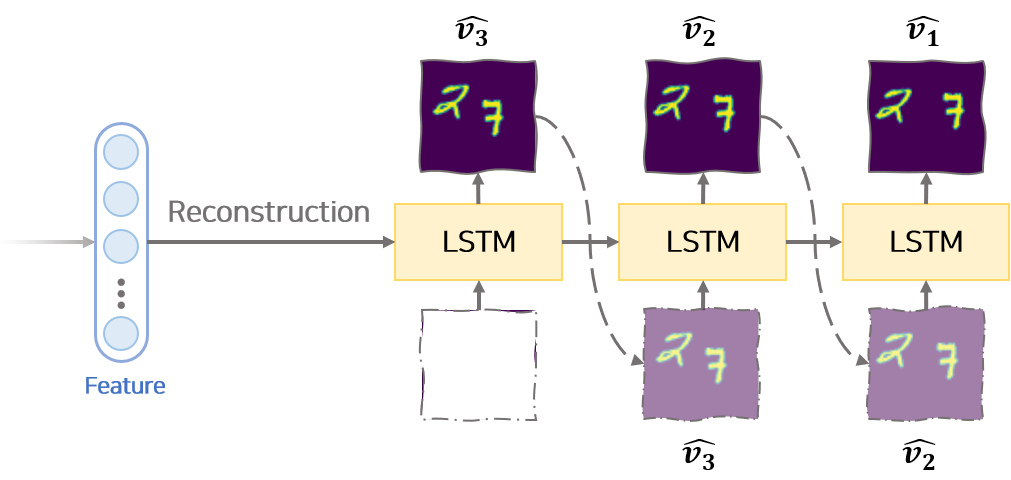
Reconstruction Decoder는 Encoder에서 생성된 feature 벡터를 이용하여 input sequence 데이터를 복원하는 LSTM 모듈입니다. 복원 순서는 input sequence의 반대 방향으로 진행합니다. 즉 input sequence가 $v_1, v_2, …, v_n$ 순서라면 Reconstruction Decoder에서는 $v_n, v_{n-1}, …, v_1$ 순으로 복원합니다.
복원 순서를 input sequence의 반대방향으로 하는 것이 생성 상관관계를 줄이는 역할을 하여 모델이 잘 학습되도록 한다고 논문에서 주장합니다.
복원 과정의 첫번째 hidden 벡터는 앞서 Encoder에서 만든 feature 벡터입니다. 복원 과정의 매 $t$ 시점에서 사용하는 hidden 벡터는 이전 시점 $t-1$에서 Reconstruction Deocder에서 생성된 hidden 벡터 $h_{t-1}^r$ 입니다. 복원 과정의 첫번째 input은 0으로 구성된 임시 벡터를 사용합니다. 복원 과정의 매 $t$ 시점에서 사용하는 input은 이전 시점 $t-1$에서 Reconstruction Deocder에서 생성된 이미지인 $\hat{v}^r_{t-1}$ 입니다.
[3] Prediction Decoder
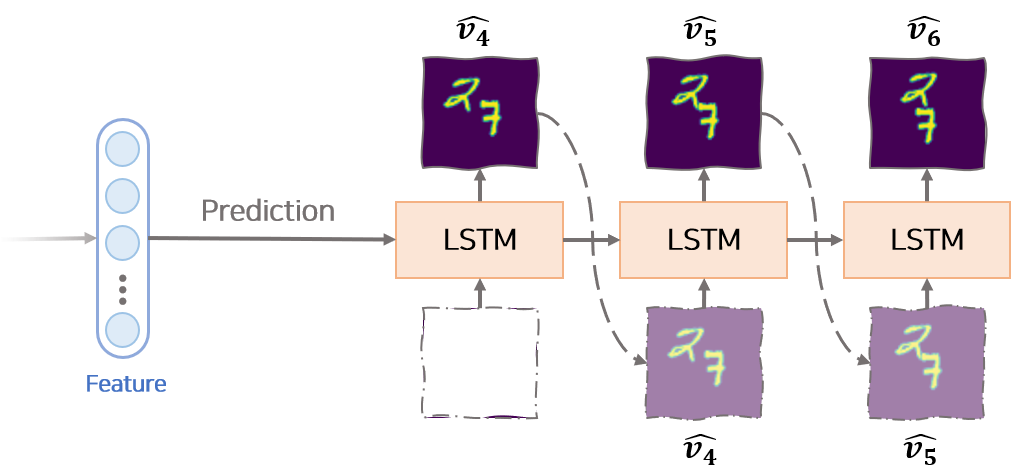
Prediction Decoder는 Encoder에서 생성된 feature 벡터를 이용하여 input sequence 이후 나올 미래의 이미지 sequence를 생성하는 LSTM 모듈입니다. input sequence가 $v_1, v_2, …, v_n$ 이라면 Prediction Decoder에서는 $k$개의 sequence, 즉 $v_{n+1}, v_{n+2}, …, v_{n+k}$ 를 생성합니다.
생성 과정의 첫번째 hidden 벡터는 앞서 Encoder에서 만든 feature 벡터입니다. 생성 과정의 매 $t$ 시점에서 사용하는 hidden 벡터는 이전 시점 $t-1$에서 Prediction Decoder에서 생성된 hidden 벡터 $h_{t-1}^p$ 입니다. 생성 과정의 첫번째 input은 0으로 구성된 임시 벡터를 사용합니다. 생성 과정의 매 $t$ 시점에서 사용하는 input은 이전 시점 $t-1$에서 Prediction Decoder에서 생성된 이미지인 $\hat{v}^p_{t-1}$ 입니다.
모델 구조적 장점
LSTM AutoEncoder는 reconstruction task와 prediction task를 함께 학습함으로써 각각의 task만을 학습할 경우 발생하는 단점을 극복할 수 있습니다.
reconstruction task만을 수행하여 모델을 학습할 경우 모델은 input의 사소한 정보까지 보존하여 Feature 벡터를 생성합니다. 즉 사소한 정보가 저장될 수 없게 Feature 벡터의 크기를 작게 설정하지 않으면 과적합(overfitting)이 발생하는 단점이 존재합니다.
prediction task만을 수행하여 모델을 학습할 경우 모델은 input의 최근 sequence 정보만을 이용하여 학습합니다. 일반적으로 prediction에 필요한 정보는 예측하기 전 시점에 가까울수록 상관관계가 높기 때문입니다. 따라서 과거 시점의 정보를 활용하지 못하는 단점이 존재합니다.
두가지 task를 함께 학습함으로써 모델이 모든 정보를 저장하지 않고 중요정보(이미지 모습, 이동방향 등)를 feature에 저장하도록 유도할 수 있습니다. 또한 Sequence 데이터의 모든 시점 정보를 활용하여 학습함으로써 모델이 쉽게 학습할 수 있도록 돕는 역할을 합니다.
코드 구현
주의
튜토리얼은 pytorch, numpy, torchvision, easydict, tqdm, matplotlib, celluloid, tqdm 라이브러리가 필요합니다. 2020.10.11 기준 최신 버전의 라이브러리를 이용하여 구현하였고 이후 업데이트 버전에 따른 변경은 고려하고 있지 않습니다. Jupyter로 구현한 코드를 기반으로 글을 작성하고 있습니다. 따라서 tqdm 라이브러리를 python 코드로 옮길때 주의가 필요합니다.
데이터

튜토리얼에서 사용하는 데이터는 Moving MNIST 입니다. 이 데이터는 9000개의 학습 비디오 데이터와 1000개의 평가 비디오 데이터로 구성되어 있습니다. 비디오는 20개의 이미지 frame으로 구성되어 있습니다. 각 이미지는 64×64 픽셀, 1개의 channel로 구성되어 있고 이미지 내에 두개의 숫자가 임의의 좌표에 위치해 있습니다. 각 비디오는 두개의 임의의 숫자가 원을 그리며 각각 다른 속도로 움직이고 있습니다.

해당 데이터는 직접 다운로드 할 수 있고, 데이터 제공 모듈을 이용하여 다운받을 수 있습니다.
편의상 데이터 제공 모듈을 활용합니다.
데이터 제공 모듈을 [MovingMNIST GITHUB] 에서 다운 받고 압축을 풀어 작업하고 있는 폴더에 MovingMNIST.py를 위치시킵니다.
1. 라이브러리 Import
1
2
3
4
5
6
7
8
9
10
11
import os
import matplotlib.pyplot as plt
import numpy as np
import torch
from torch import nn
from torchvision import transforms, datasets
import easydict
from tqdm.notebook import tqdm
from tqdm.notebook import trange
import torch.utils.data as data
from celluloid import Camera
모델을 구현하는데 필요한 라이브러리를 Import 합니다. Import 에러가 발생하면 해당 라이브러리를 설치한 후 진행해야 합니다.
2. 데이터 불러오기
1
2
3
4
5
6
7
from MovingMNIST import MovingMNIST
## Train Data를 불러오기
train_set = MovingMNIST(root='.data/mnist', train=True, download=True, transform=transforms.ToTensor(), target_transform=transforms.ToTensor())
## Test Data를 불러오기
test_set = MovingMNIST(root='.data/mnist', train=False, download=True, transform=transforms.ToTensor(), target_transform=transforms.ToTensor())
데이터 모듈 MovingMNIST.py 을 Import 하고 데이터 모듈을 이용하여 데이터를 다운받습니다.
옵션으로 transform, target_transform을 설정하여 다운 받은 파일을 불러올 때 전처리를 할 수 있습니다.
숫자열로 구성된 이미지 데이터를 pytorch의 tensor로 변형하기 위하여 transforms.ToTensor() 를 옵션으로 넣어줍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
## 데이터 시각화
def imshow(past_data, title='없음'):
num_img = len(past_data)
fig = fig=plt.figure(figsize=(4*num_img, 4))
for idx in range(1, num_img+1):
ax = fig.add_subplot(1, num_img+1, idx)
ax.imshow(past_data[idx-1])
plt.suptitle(title, fontsize=30)
## 데이터는 Tuple 형태로 되어 있음.
## past_data 10개, future_data 10개로 구성
future_data, past_data = train_set[0]
imshow(past_data, title='input')

데이터 모듈은 tuple 형태로 데이터를 제공합니다. 데이터는 가운데 시점을 기준으로 과거 sequence 데이터와 미래 sequence 데이터로 구성됩니다. 데이터 모듈로부터 데이터를 로드하고 시각화하여 데이터가 잘 다운로드 되었는지 확인합니다.
3. 모델 구성하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class Encoder(nn.Module):
def __init__(self, input_size=4096, hidden_size=1024, num_layers=2):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True,
dropout=0.1, bidirectional=False)
def forward(self, x):
# x: tensor of shape (batch_size, seq_length, hidden_size)
outputs, (hidden, cell) = self.lstm(x)
return (hidden, cell)
class Decoder(nn.Module):
def __init__(self, input_size=4096, hidden_size=1024, output_size=4096, num_layers=2):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True,
dropout=0.1, bidirectional=False)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden):
# x: tensor of shape (batch_size, seq_length, hidden_size)
output, (hidden, cell) = self.lstm(x, hidden)
prediction = self.fc(output)
return prediction, (hidden, cell)
논문에서 제시한 모델은 Encoder와 Decoder 모듈로 구성됩니다.
Deocder는 쓰임세에 따라 Reconstruction Decoder와 Prediction Decoder로 나뉩니다.
pytorch 라이브러리에서 LSTM, Fully connected Layer를 제공하고 있기 때문에 해당 모듈을 이용하여 Decoder와 Encoder를 구성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
class Seq2Seq(nn.Module):
def __init__(self, args):
super().__init__()
hidden_size = args.hidden_size
input_size = args.input_size
output_size = args.output_size
num_layers = args.num_layers
self.encoder = Encoder(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
)
self.reconstruct_decoder = Decoder(
input_size=input_size,
output_size=output_size,
hidden_size=hidden_size,
num_layers=num_layers,
)
self.predict_decoder = Decoder(
input_size=input_size,
output_size=output_size,
hidden_size=hidden_size,
num_layers=num_layers,
)
self.criterion = nn.MSELoss()
## Loss 출력
def forward(self, src, trg):
# src: tensor of shape (batch_size, seq_length, hidden_size)
# trg: tensor of shape (batch_size, seq_length, hidden_size)
batch_size, sequence_length, img_size = src.size()
## Encoder 넣기
encoder_hidden = self.encoder(src)
## Prediction Loss 계산
predict_output = []
temp_input = torch.zeros((batch_size,1,img_size), dtype=torch.float).to(src.device)
hidden = encoder_hidden
for t in range(sequence_length):
temp_input, hidden = self.predict_decoder(temp_input, hidden)
predict_output.append(temp_input)
predict_output = torch.cat(predict_output, dim=1)
predict_loss = self.criterion(predict_output, trg)
## Reconstruction Loss 계산
inv_idx = torch.arange(sequence_length - 1, -1, -1).long()
reconstruct_output = []
temp_input = torch.zeros((batch_size,1,img_size), dtype=torch.float).to(src.device)
hidden = encoder_hidden
for t in range(sequence_length):
temp_input, hidden = self.reconstruct_decoder(temp_input, hidden)
reconstruct_output.append(temp_input)
reconstruct_output = torch.cat(reconstruct_output, dim=1)
reconstruct_loss = self.criterion(reconstruct_output, src[:, inv_idx, :])
return reconstruct_loss, predict_loss
## 이미지 생성(Prediction)
def generate(self, src):
batch_size, sequence_length, img_size = src.size()
## Encoder 넣기
hidden = self.encoder(src)
outputs = []
temp_input = torch.zeros((batch_size,1,img_size), dtype=torch.float).to(src.device)
for t in range(sequence_length):
temp_input, hidden = self.predict_decoder(temp_input, hidden)
outputs.append(temp_input)
return torch.cat(outputs, dim=1)
## 이미지 복구(Reconstruction)
def reconstruct(self, src):
batch_size, sequence_length, img_size = src.size()
## Encoder 넣기
hidden = self.encoder(src)
outputs = []
temp_input = torch.zeros((batch_size,1,img_size), dtype=torch.float).to(src.device)
for t in range(sequence_length):
temp_input, hidden = self.reconstruct_decoder(temp_input, hidden)
outputs.append(temp_input)
return torch.cat(outputs, dim=1)
앞서 구성한 Encoder, Decoder 모듈을 이용하여 Seq2Seq를 구성합니다.
Seq2Seq 모듈에 3가지 함수을 구현하였습니다.
def forward 는 과거 sequence 이미지와 미래 sequence 이미지를 받아 Loss를 계산하는 함수입니다.
def generate 는 과거 sequence 이미지를 이용하여 미래 sequence 이미지를 생성하는 함수입니다.
def reconstruct 는 과거 sequence 이미지를 Encoder를 이용하여 feature 벡터로 압축한 후 다시 복구하는 함수입니다.
Loss를 계산하기 위한 함수로 Mean Squared Loss Function을 사용하였습니다. 논문에서는 Binary Entropy Loss를 사용하였으나 개인적으로 실험을 했을 때 MSE를 사용한 모델이 이미지를 더 명확하게 추출합니다. Decoder의 input으로 이전 시점 Decoder에서 생성한 output을 사용하지 않고 원본데이터를 넣는 Teacher Forcing 방법을 이용하여 학습할 수 있습니다. 개인적으로 실험했을 때 Teacher Forcing을 이용하여 학습하였을 때 모델이 이미지를 흐리게 생성하는 경향이 있어 위 모델은 Teacher Forcing을 사용하지 않았습니다. Teacher Forcing 과 관련된 자세한 사항은 [관련문서] 를 참고 부탁드립니다.
4. 학습 구성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
def run(args, model, train_loader, test_loader):
# optimizer 설정
optimizer = torch.optim.Adam(model.parameters(), lr=args.learning_rate)
## 반복 횟수 Setting
epochs = tqdm(range(args.max_iter//len(train_loader)+1))
## 학습하기
count = 0
for epoch in epochs:
model.train()
optimizer.zero_grad()
train_iterator = tqdm(enumerate(train_loader), total=len(train_loader), desc="training")
for i, batch_data in train_iterator:
if count > args.max_iter:
return model
count += 1
future_data, past_data = batch_data
## 데이터 GPU 설정 및 사이즈 조절
batch_size = past_data.size(0)
example_size = past_data.size(1)
past_data = past_data.view(batch_size, example_size, -1).float().to(args.device)
future_data = future_data.view(batch_size, example_size, -1).float().to(args.device)
reconstruct_loss, predict_loss = model(past_data, future_data)
## Composite Loss
loss = reconstruct_loss + predict_loss
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_iterator.set_postfix({
"train_loss": float(loss),
})
model.eval()
eval_loss = 0
test_iterator = tqdm(enumerate(test_loader), total=len(test_loader), desc="testing")
with torch.no_grad():
for i, batch_data in test_iterator:
future_data, past_data = batch_data
## 데이터 GPU 설정 및 사이즈 조절
batch_size = past_data.size(0)
example_size = past_data.size(1)
past_data = past_data.view(batch_size, example_size, -1).float().to(args.device)
future_data = future_data.view(batch_size, example_size, -1).float().to(args.device)
reconstruct_loss, predict_loss = model(past_data, future_data)
## Composite Loss
loss = reconstruct_loss + predict_loss
eval_loss += loss.mean().item()
test_iterator.set_postfix({
"eval_loss": float(loss),
})
eval_loss = eval_loss / len(test_loader)
print("Evaluation Score : [{}]".format(eval_loss))
return model
모델을 안정적이게 학습하기 위하여 SGD optimizer 대신 Adam optimizer 을 사용합니다.
총 반복할 횟수(max iteration)를 설정하고 반복횟수를 만족할 때까지 계속 학습을 진행합니다.
5. 모델 & 학습 파라미터 설정
1
2
3
4
5
6
7
8
9
10
11
## 설정 폴더
args = easydict.EasyDict({
"batch_size": 128, ## 배치 사이즈 설정
"device": torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu'), ## GPU 사용 여부 설정
"input_size": 4096, ## 입력 차원 설정
"hidden_size": 2048, ## Hidden 차원 설정
"output_size": 4096, ## 출력 차원 설정
"num_layers": 2, ## LSTM layer 갯수 설정
"learning_rate" : 0.0005, ## learning rate 설정
"max_iter" : 10000, ## 총 반복 횟수 설정
})
모델과 학습 하이퍼파라미터를 설정합니다. 논문에서 설정한 것과 같도록 hidden 차원은 2048로 설정합니다. LSTM layer 갯수를 2개로 고정합니다.
논문에서 정확한 반복횟수를 언급하지 않습니다. 따라서 10000번을 설정합니다. 2080ti GPU로 학습하는데 약 1시간 정도 소요됩니다. 자원이 넉넉하지 않다면 early stop을 이용하여 모델의 학습 종료 조건을 설정하는 것을 추천드립니다.
6. 학습하기
1
2
3
4
5
6
7
8
9
## Data Loader 형태로 변환
train_loader = torch.utils.data.DataLoader(
dataset=train_set,
batch_size=args.batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(
dataset=test_set,
batch_size=args.batch_size,
shuffle=False)
데이터를 배치 형태로 불러오기 위하여 pytorch 라이브러리에서 제공하는 DataLoader를 이용합니다.
옵션으로 shuffle True로 설정해야 섞인 데이터를 이용하여 학습이 가능합니다.
1
2
3
4
5
6
7
8
9
10
11
12
## 모델 구성
model = Seq2Seq(args)
model.to(args.device)
## 모델 학습
model = run(args, model, train_loader, test_loader)
save_path = 'result'
if not os.path.isdir(save_path):
os.mkdir(save_path)
model_path = os.path.join(save_path, 'model.bin')
torch.save(model.state_dict(), model_path)
 설정한 옵션으로 모델을 학습합니다.
학습이 완료되면 학습된 모델을 pytorch 라이브러리를 이용하여 저장합니다.
설정한 옵션으로 모델을 학습합니다.
학습이 완료되면 학습된 모델을 pytorch 라이브러리를 이용하여 저장합니다.
7. 결과 출력
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
from celluloid import Camera
## 에니메이션 데이터 시각화
def animation_show(original_data, generated_data, title, save_path):
fig = plt.figure(figsize=(8, 4))
camera = Camera(fig)
for i in range(len(original_data)):
ax=fig.add_subplot(121)
ax.imshow(original_data[i])
ax.set_title('original')
ax2=fig.add_subplot(122)
ax2.imshow(generated_data[i])
ax2.set_title('generated')
plt.suptitle(title, fontsize=20)
camera.snap()
animation = camera.animate(500, blit=True)
# .gif 파일로 저장하면 끝!
animation.save(
save_path,
dpi=300,
savefig_kwargs={
'frameon': False,
'pad_inches': 'tight'
}
)
## 결과 출력
future_data, past_data = test_set[1]
model.eval()
with torch.no_grad():
future_data = future_data.to(args.device).view(1, 10, -1).float()
past_data = past_data.to(args.device).view(1, 10, -1).float()
outputs = model.generate(past_data)
original_data = future_data.reshape(-1, 64, 64).cpu().squeeze().numpy()
generated_data = outputs.reshape(-1, 64, 64).cpu().squeeze().numpy()
animation_show(original_data, generated_data, "Prediction", 'prediction.gif')
결과를 출력하기 위해서 모델의 generate 함수를 사용합니다.
generate 함수는 과거 이미지 sequence를 이용하여 미래 이미지 sequence를 생성하는 함수입니다.
함수를 통해 생성된 generated_data 와 original_data를 시각화하고 얼마나 비슷한 이미지를 생성하는지를 비교합니다.
학습 결과를 이미지로 보기 보다는 에니메이션을 통해 확인하기 위하여 celluloid 라이브러리를 활용합니다.
에니메이션의 자세한 사용방법은 [블로그] 에서 참고하시기 바랍니다.
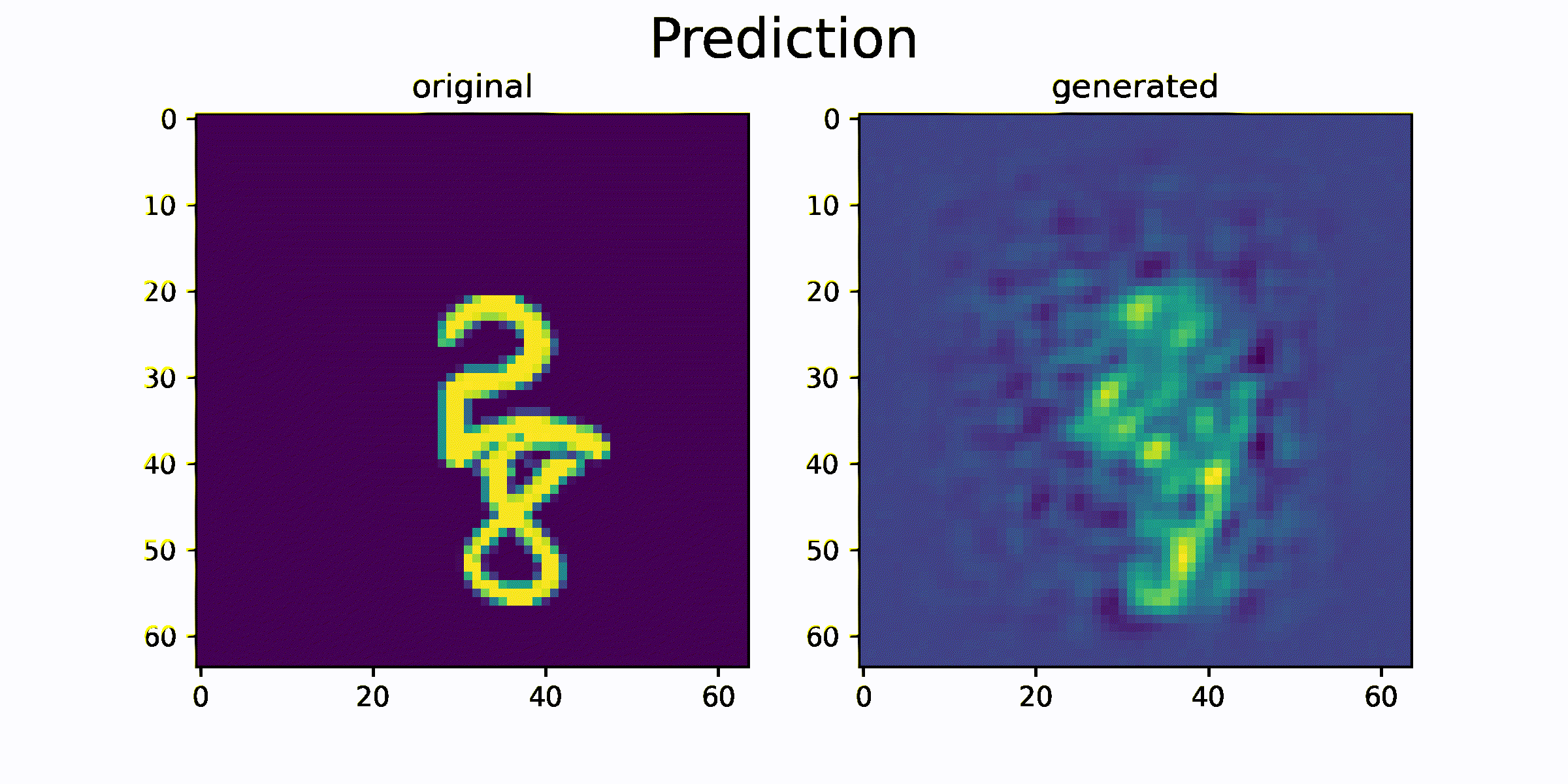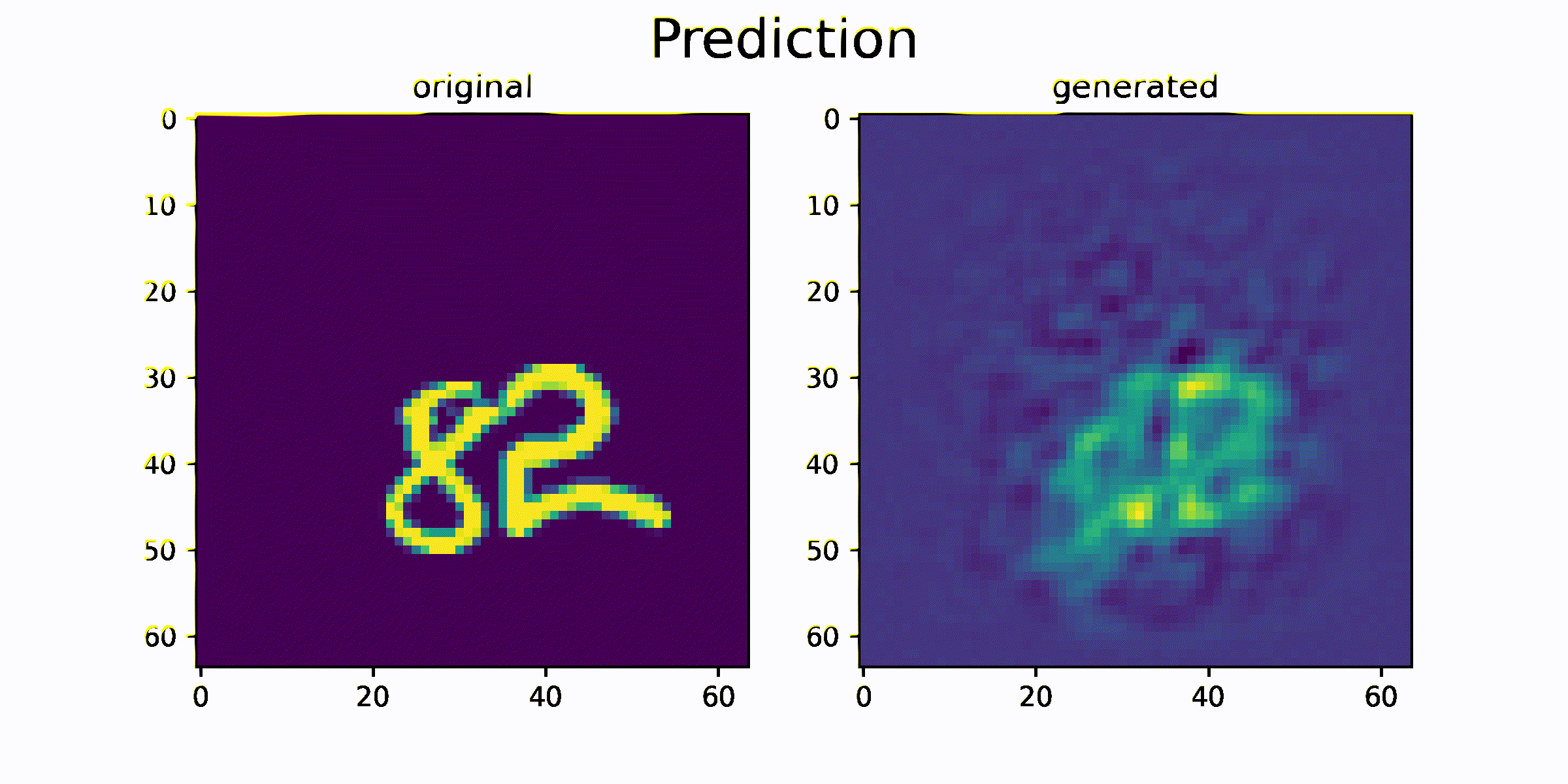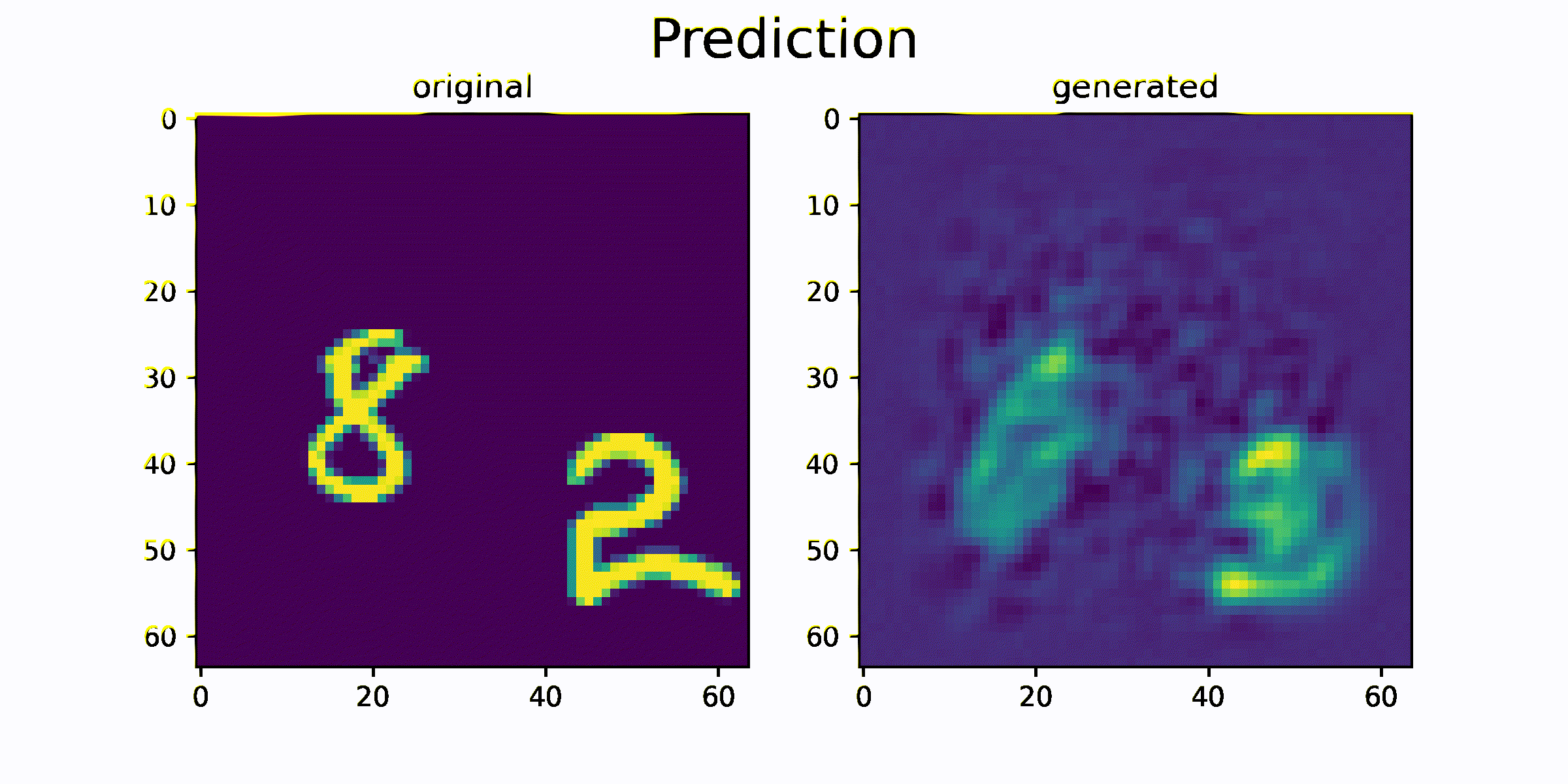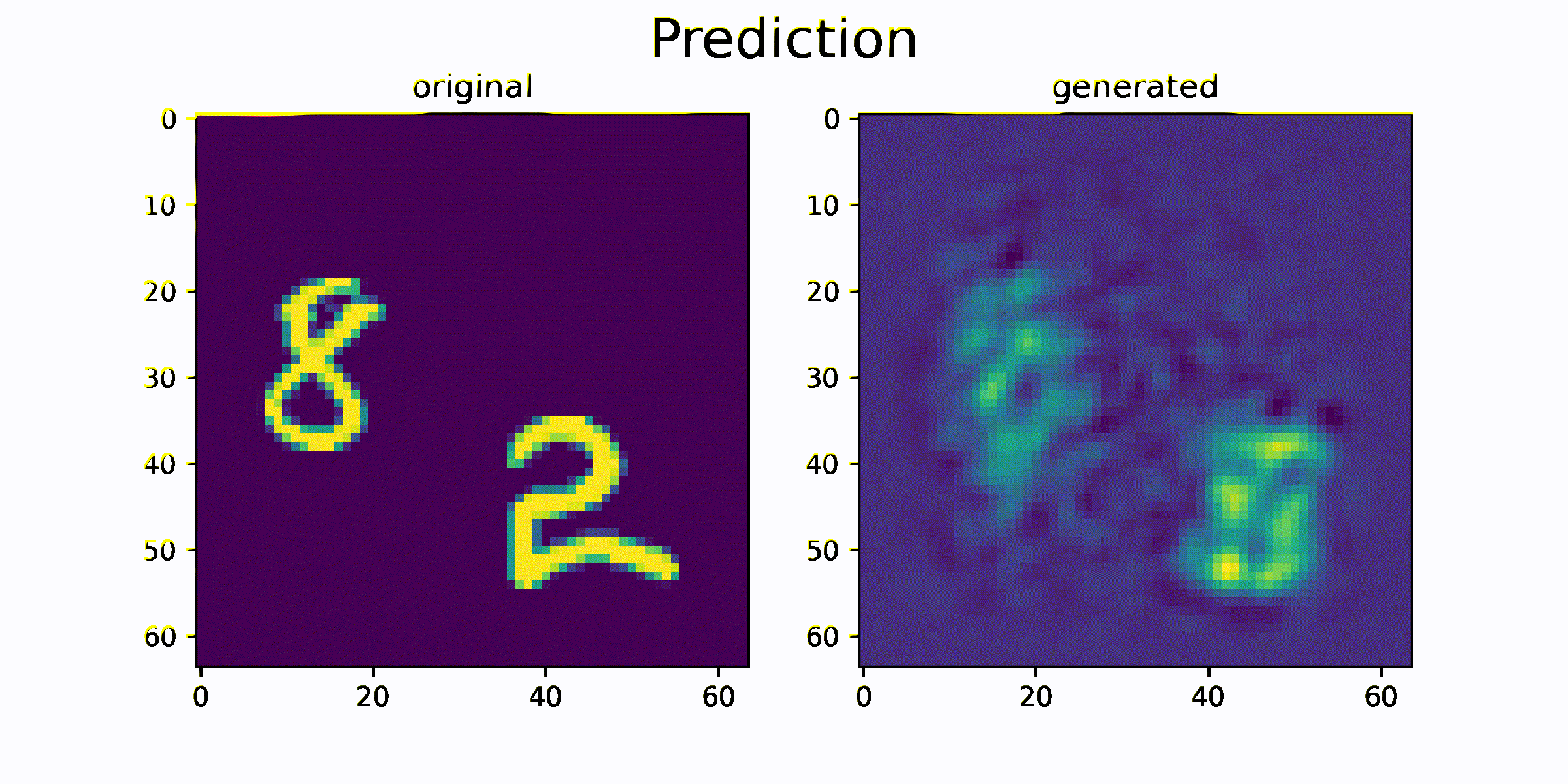
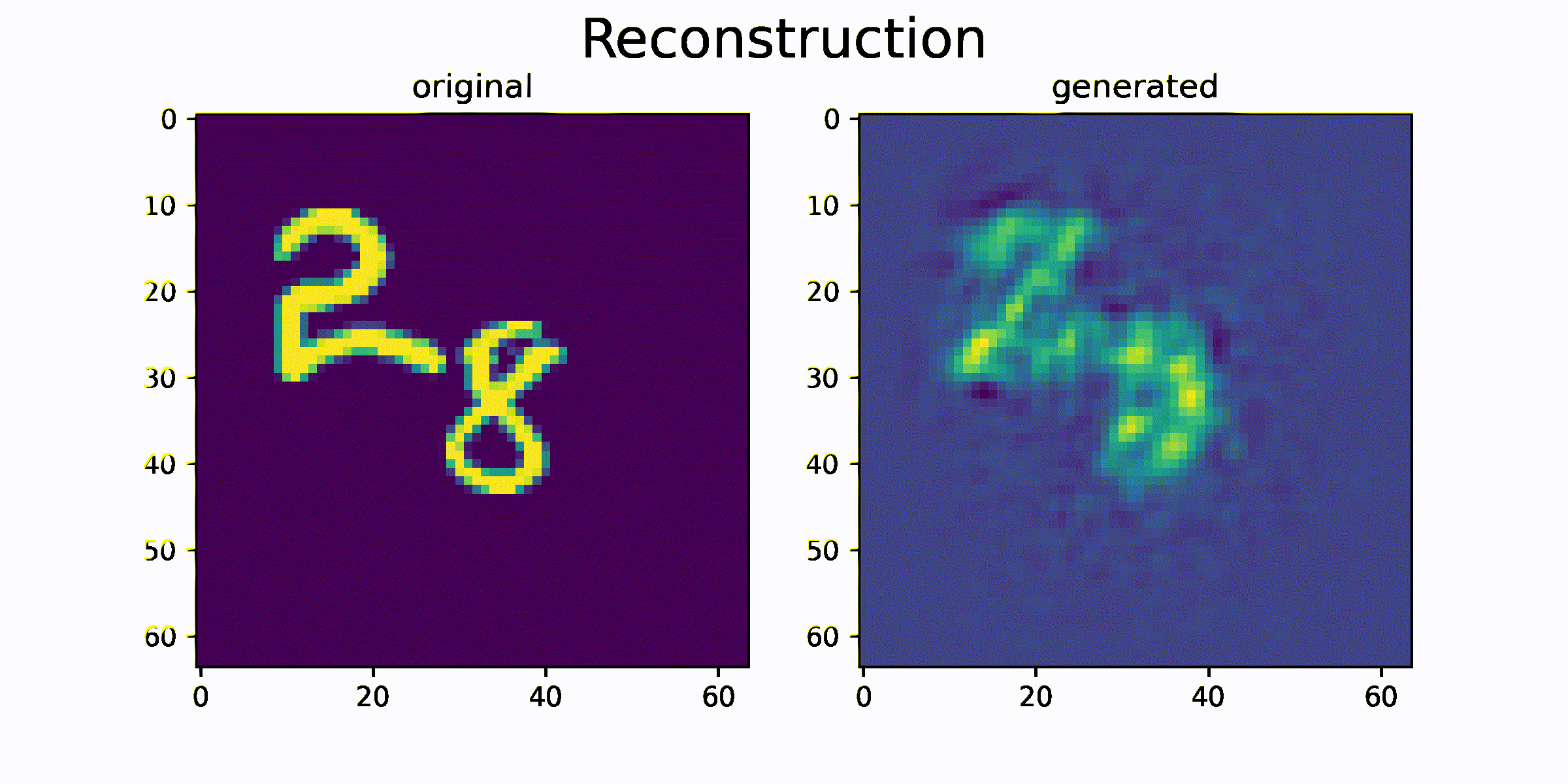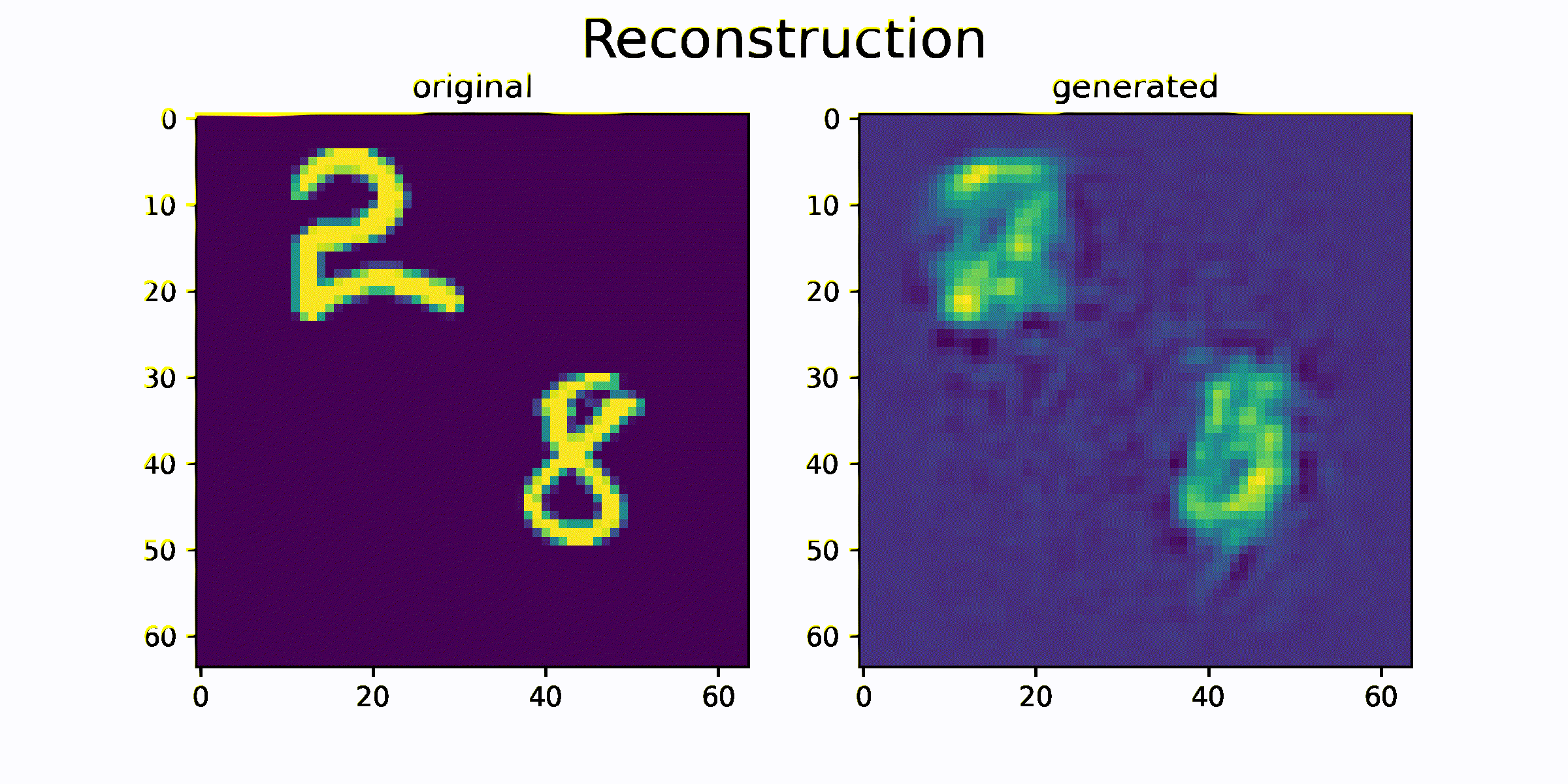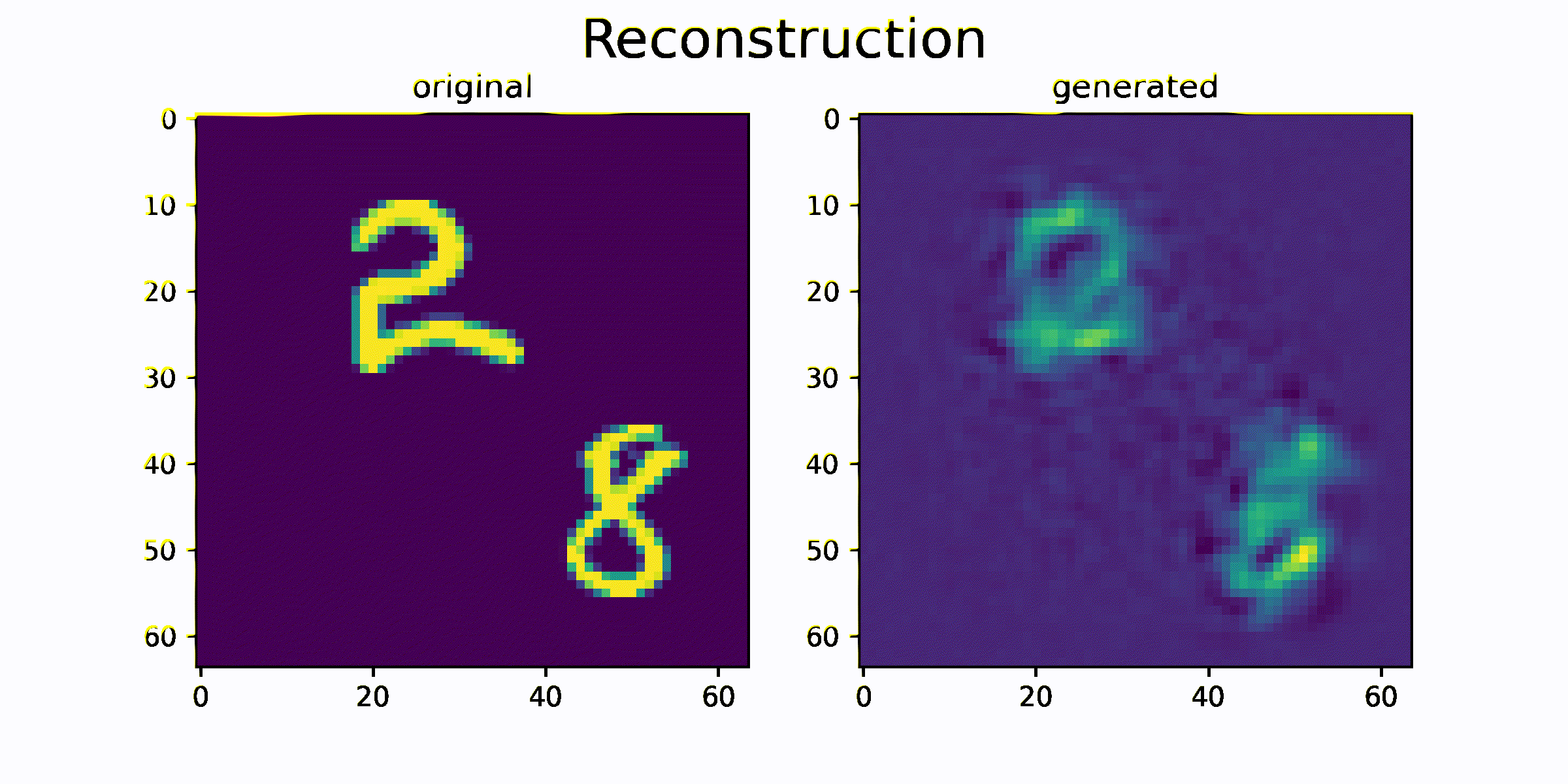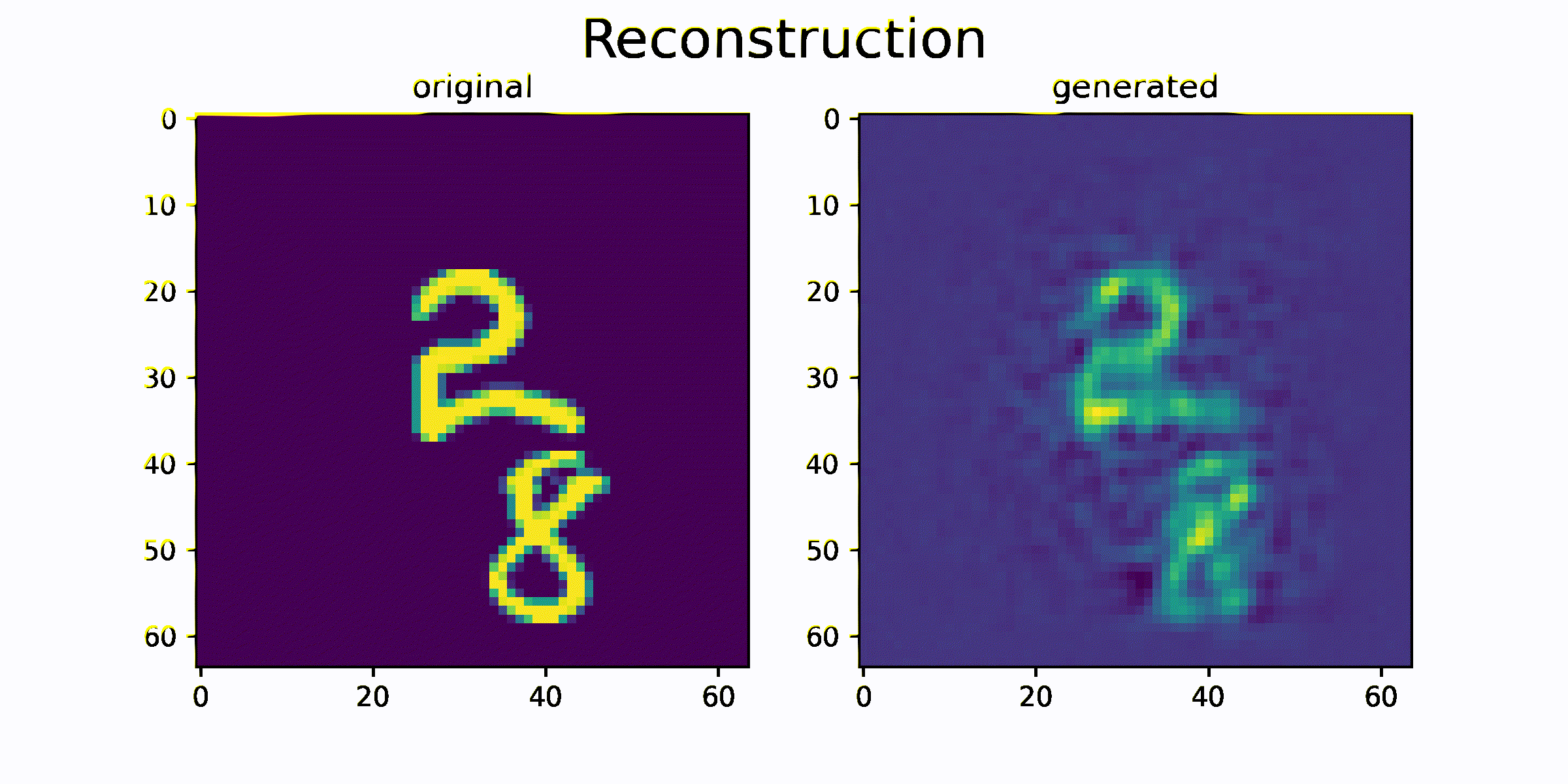
시각화 결과를 통해 원본 sequence 이미지와 생성된 sequence 이미지가 매우 흡사한 것을 확인 할 수 있습니다. 즉 이미지의 모양과 이미지의 움직임 정보가 feature 에 잘 압축되었음을 추측할 수 있습니다.
[GITHUB]에서 튜토리얼의 전체 파일을 제공하고 있습니다.
Reference
- [PAPER] Unsupervised Learning of Video Representations using LSTMs, Srivastava at el
- [GITHUB] Moving MNIST Auto Download Module, tychovdo
- [GITHUB] PyTorch Seq2Seq Sample, bentrevett
- [DATASET] Moving MNIST Dataset
- [BLOG] Teacher Forcing 이란, 김기현