[코드리뷰] - Face Recognition Using Kernel Principal Component Analysis, 2002
오늘 리뷰는 이미지에서 Kernel-PCA를 사용하여 얼굴의 특징점을 추출하고 SVM을 이용하여 서로다른 얼굴을 분류하는 논문을 리뷰하겠습니다. 이 글은 Face Recognition Using Kernel Principal Component Analysis 논문 과 고려대학교 강필성 교수님의 강의 참고하여 정리하였음을 먼저 밝힙니다. 논문을 간단하게 리뷰하고 pytorch 및 scikit-learn 라이브러리를 이용하여 코드를 구현한 후 자세하게 설명드리겠습니다. 혹시 제가 잘못 알고 있는 점이나 보안할 점이 있다면 댓글 부탁드립니다.
Short Summary
이 논문의 큰 특징 3가지는 아래와 같습니다.
- 이미지로부터 특징점을 추출하는 방법으로 Kernel-PCA를 적용합니다.
- SVM을 활용하여 이미지 특징점을 학습하고 얼굴을 분류하는 알고리즘을 구축합니다.
- SVM으로부터 추출된 점수를 정규화하기 위하여 Neural Network를 활용합니다.
모델 구조
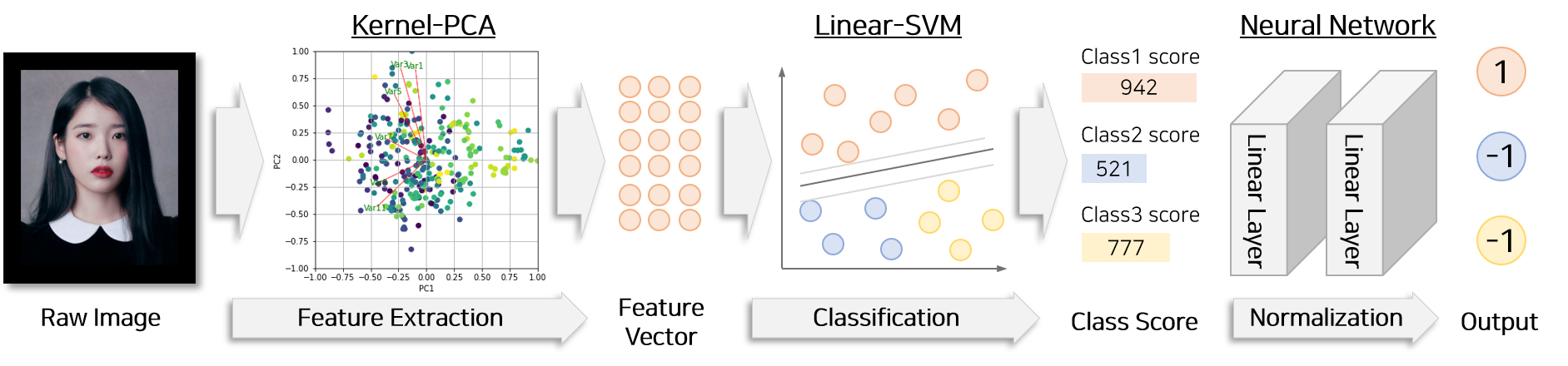
논문에서 제시하는 얼굴인식 분류 과정은 크게 2가지로 나뉩니다.
- Face Feature Extraction : kerenl-PCA를 이용하여 이미지 특징점 추출과정
- Face Recognition : linear-SVM을 이용하여 이미지를 class로 분류하는 과정
이미지 특징점 추출하는 단계에서는 kernel-PCA를 활용합니다. 분류단계에서는 linear-SVM과 Neural Network를 활용합니다.
[1] Face Feature Extraction
본 논문에서는 이미지 특징점을 추출하기 위하여 kernel-PCA를 이용합니다. 따라서 PCA와 kernel-PCA에 대해 간단하게 설명드리겠습니다.
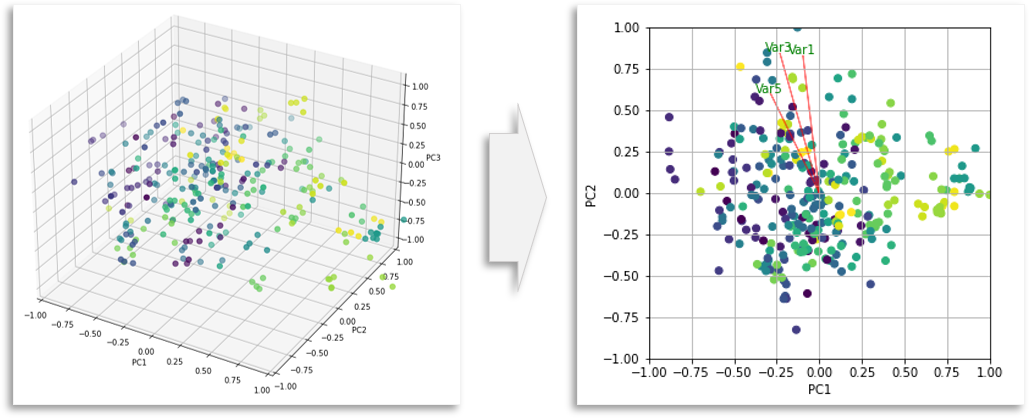
PCA는 데이터의 분산을 최대한 보존하면서 저차원 공간으로 변환하는 기법입니다. 따라서 의미없는 정보를 버리고 의미있는 정보만을 추출하는 방법으로 사용됩니다. 일반적으로 공분산에서 고유벡터(eigenvector)와 고유값(eigenvalue)를 추출한 뒤 n개의 고유벡터만을 활용하여 입력을 재구성함으로써 PCA를 적용할 수 있습니다.
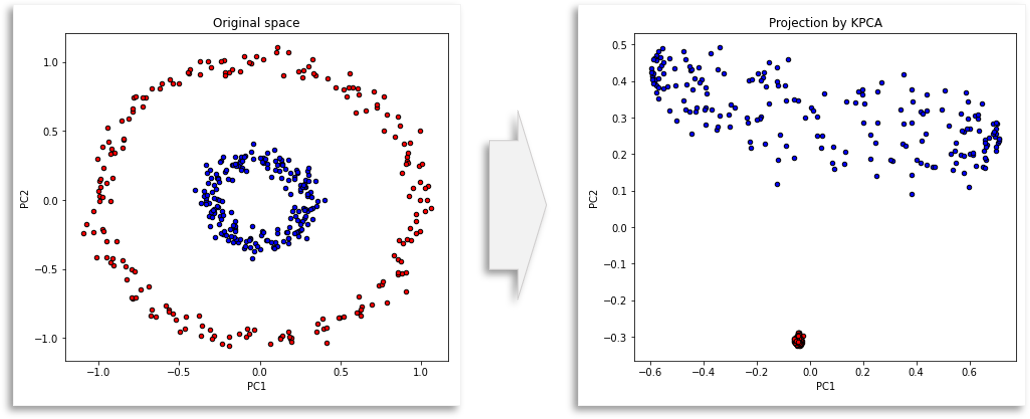
kernel-PCA는 PCA에 kernel trick을 적용한 알고리즘 입니다. kernel-PCA는 non-linear 매핑함수 $\phi$를 활용하여 input $x$를 고차원 공간으로 매핑한 다음 일반적인 linear-PCA를 적용합니다.
Kernel PCA Procedure
covariance의 정의에 따라 kernel covariance matrix는 아래과 같이 표현됩니다. covariance matrix는 feature M×M 차원으로 표현됩니다.
$\phi$ : 매핑함수
$C^{\phi}$ : kernel covariance matrix
$x_i$ : i 번째 데이터
$\phi(x_i)$ : 고차원으로 공간으로 매핑된 i 번째 데이터
$m^{\phi}$ : 고차원으로 공간으로 매핑된 데이터의 평균
$M$ : feature space의 차원
$N$ : 데이터 갯수
기존 covariance matrix의 형태에서 x를 고차원 공간으로 매핑한 함수 $\phi$를 적용한 모습과 같습니다. 사영된 공간에서 평균은 0이라는 가정을 하면 좀 더 쉬운 수식으로 아래와 같이 표현할 수 있습니다.
수학적 정의에 따라 covariance matrix($C^{\phi}$)의 eigenvalue($\lambda_k$)와 eigenvectors($v_k$)는 아래와 같이 식이 성립합니다.
위 두 수식을 이용하여 다음과 같은 식을 구성할 수 있습니다. 또한 주성분 $v_k$ 는 데이터의 선형결합으로 표현되므로 아래와 같은 식으로 표현할 수 있습니다.
$v_k$를 정리하면 식을 아래와 같이 정리할 수 있습니다.
위 식에 kernel fuctnion을 적용하기 위하여 $\phi(x_l)$를 양변에 곱하고 약간의 변형하여 식을 재구성합니다.
이제 kernel trick을 이용하여 매핑함수 $\phi$와 관련된 식을 정리하면 아래와 같이 표현할 수 있습니다.
이로써 Kernel PCA는 아래와 같이 구할 수 있습니다.
[2] Face Recognition
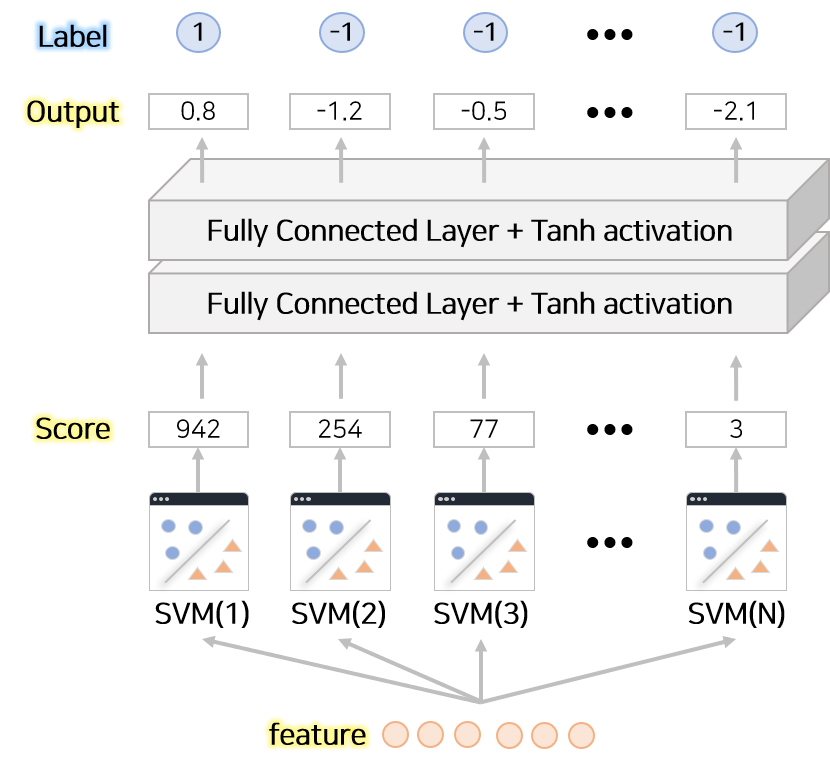
kernel-PCA를 통해 추출한 특징점을 이용하여 이미지를 분류하는 단계입니다. 본 논문에서는 2가지 모델을 차례로 이용하여 특징점을 각 class로 분류합니다.
- 점수 추출 : Linear-SVM으로부터 각 class에 대한 점수를 추출하는 단계
- 정규화 과정 : Neural Network 를 활용하여 각 class에 대한 점수를 normalize하고 최종 결과를 도출하는 단계
각 class에 대한 점수를 추출하기 위하여 Linear-SVM을 구성합니다. 분류할 대상은 2개 이상의 class를 갖고 있으므로 SVM을 class 갯수(N)만큼 구성합니다. kernel-PCA로부터 추출한 특징을 N개의 SVM에 넣어 각 class에 대한 점수를 추출합니다.
추출한 점수를 (Fully Connected Layer + Tanh activation) 으로 구성된 2개 층의 Neural Network에 넣습니다. Neural Network로부터 최종 결과인 각 class에 대한 Normalized 점수가 추출됩니다. 이미지가 해당 class에 속할 경우 1로 해당하지 않을 경우 -1로 label을 구성하고 Neural Network의 output과의 차이로부터 MSE Loss로 계산하여 학습하면 SVM으로부터 추출된 점수보다 정규화한 점수를 Neural Network에서 추출할 수 있습니다.
코드 구현
주의
튜토리얼은 pytorch, numpy, torchvision, easydict, tqdm, matplotlib, celluloid, tqdm 라이브러리가 필요합니다. 2020.11.01 기준 최신 버전의 라이브러리를 이용하여 구현하였고 이후 업데이트 버전에 따른 변경은 고려하고 있지 않습니다. Jupyter로 구현한 코드를 기반으로 글을 작성하고 있습니다. 따라서 tqdm 라이브러리를 python 코드로 옮길때 주의가 필요합니다.
데이터

튜토리얼에서 사용하는 데이터는 The Labeled Faces in the Wild face recognition dataset 입니다.
Olivetti 데이터는 총 40명의 인물이 등장하며 각 인물에 대해 10개의 이미지로 구성되어 있습니다.
각 이미지는 서로 다른 시간에 촬영되었습니다.
또한 촬영 시 제약사항이 없으므로 이미지에는 다양한 얼굴표정, 안경 착용 등 독특한 특징이 나타날 수 있습니다.
데이터는 scikit-learn package를 통해서 다운 받을 수 있으므로 편의상 라이브러리를 활용합니다.
1. 라이브러리 Import
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from sklearn.datasets import fetch_olivetti_faces
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report, accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.decomposition import KernelPCA
from sklearn.svm import SVC
import numpy as np
import matplotlib.pyplot as plt
import numpy as np
from sklearn.pipeline import Pipeline
import pandas as pd
import plotly.express as px
from torch import optim
import torch
from tqdm.notebook import tqdm
모델을 구현하는데 필요한 라이브러리를 import 합니다. Import 에러가 발생하면 반드시 해당 라이브러리를 설치한 후 진행해야 합니다.
2. 데이터 불러오기
1
2
3
4
5
6
7
8
9
10
11
12
olive_data = fetch_olivetti_faces()
## 이미지 데이터
n_samples, h, w = olive_data.images.shape
data_size = h*w
X = olive_data.images.reshape(-1, data_size)
print("이미지 갯수[{}], 이미지 가로[{}], 이미지 세로[{}] 가로X세로[{}]".format(n_samples, h, w, data_size))
## Label 데이터
y = olive_data.target
n_classes = len(set(y))
print("클래스 개수[{}]".format(n_classes))
이미지의 갯수는 총 400개 입니다. 각 이미지는 1개의 channel과 64×64 픽셀 크기를 갖고 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
## 데이터 시각화
def plot_gallery(images, item_index, n_col = 3, h=64, w=64, title=None):
if len(item_index) < n_col:
n_row = len(item_index)
plt.figure(figsize =(1.8 * n_col, 2.4))
item_index = item_index[:n_col]
#plt.subplots_adjust(bottom = 0, left =.01, right =.99, top =.90, hspace =.35)
for i in range(n_col):
plt.subplot(1, n_col, i + 1)
plt.imshow(images[item_index[i]].reshape(h, w), cmap = plt.cm.gray)
plt.xticks(())
plt.yticks(())
if title is not None:
plt.suptitle(title)
## 얼굴 선택
sample_index = 1
n_col = 3
itemindex = np.where(y==sample_index)[0]
## 얼굴 plot
plot_gallery(X, itemindex, n_col, h, w)

API를 통해 데이터를 저장한 후 이미지를 시각화하여 데이터가 잘 저장되었는지를 확인합니다.
3. Kernel-PCA & Linear-SVM 파라미터 탐색
이미지를 input으로 사용하여 각 class로 구분하기하기 위하여 kernel-PCA, SVM, Neural Network 알고리즘을 구성해야 합니다. 각 알고리즘은 다양한 hyper-parameter 갖고 있으므로 알맞는 hyper-parameter 탐색이 필요합니다. 우선적으로 Kernel-PCA와 SVM 두개의 알고리즘을 이용하여 Pipe-Line을 구성하고 Grid Search를 활용하여 각 알고리즘의 hyper-parameter 탐색을 진행합니다.
pipe-line에 있는 각 알고리즘의 hyper-parameter를 grid-search를 이용하여 탐색하기 위해서는 pipe-line에서 설정한 이름 + __ + 파라미터 로 String을 만들어야 합니다.
예를들어 SVM의 이름을 pipeline에서 svc라고 지정하고 Grid Search를 이용하여 SVM의 hyper-parameter인 C를 탐색하고 싶다면
parameter dict에 key를 svc__C로 넣고 value에 탐색할 영역에 해당하는 리스트 형태의 데이터를 넣어야 합니다.
1
2
3
4
5
6
7
8
9
## Pipe Line 구성
pipe = Pipeline([('pca', KernelPCA(kernel="poly")), ('svc', SVC(class_weight ='balanced'))])
## 탐색 할 hyper-paramter 를 setting
param_grid = {
'pca__n_components': [20, 40, 60, 80, 100, 120, 140], ## Kernel-PCA 파라미터(n_components)
'pca__degree': [2, 3, 4, 5], ## Kernel-PCA 파라미터(degree)
'svc__C': [1e-1, 2e-1, 3e-1, 4e-1, 5e-1, 6e-1, 7e-1, 8e-1, 9e-1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 1e1], ## SVM 파라미터
}
kernel-PCA에서 탐색해야 할 hyper-paramter는 degree와 n_components 입니다. degree는 polynomial kernel 의 승수를 의미합니다. n_components는 몇개의 eigenvector를 활용하여 차원을 축소할 것인지를 나타내는 hyper-parameter입니다.
본 논문에서는 Polynomial Kernel-PCA의 degree를 4로 설정했을 때 가장 성능이 좋았다고 기술하고 있습니다. 또한 알고리즘으로부터 추출된 eigenvalues(n_components) 중 큰 순서대로 120개를 뽑아 특징점으로 활용했을 때 가장 성능이 높다고 기술하고 있습니다. 하지만 튜토리얼에서는 Grid Search을 통해 합리적인 hyper-parameter를 도출합니다.
Support Vector Machine(SVM)에서 탐색해야 할 hyper-parameter는 C입니다. C는 패널티 강도를 의미하며 SVM을 fitting하는 과정에서 정답 class로 분류되지 않을 때 부여되는 값과 비례합니다.
1
2
3
4
5
6
7
8
9
10
11
12
clf = GridSearchCV(pipe, param_grid=param_grid)
clf = clf.fit(X_train, y_train)
print("Grid Search를 이용하여 탐색한 Best hyper-parameter")
print(clf.best_estimator_)
## 결과를 Dataframe으로 도출
summary = pd.concat([pd.DataFrame(clf.cv_results_["params"]),pd.DataFrame(clf.cv_results_["mean_test_score"], columns=["Accuracy"])],axis=1)
## 결과를 시각화
fig = px.bar(summary, x="pca__n_components", y="Accuracy", color="pca__n_components",
animation_frame="svc__C", animation_group="pca__n_components", range_y=[0.5,1])
fig.show()
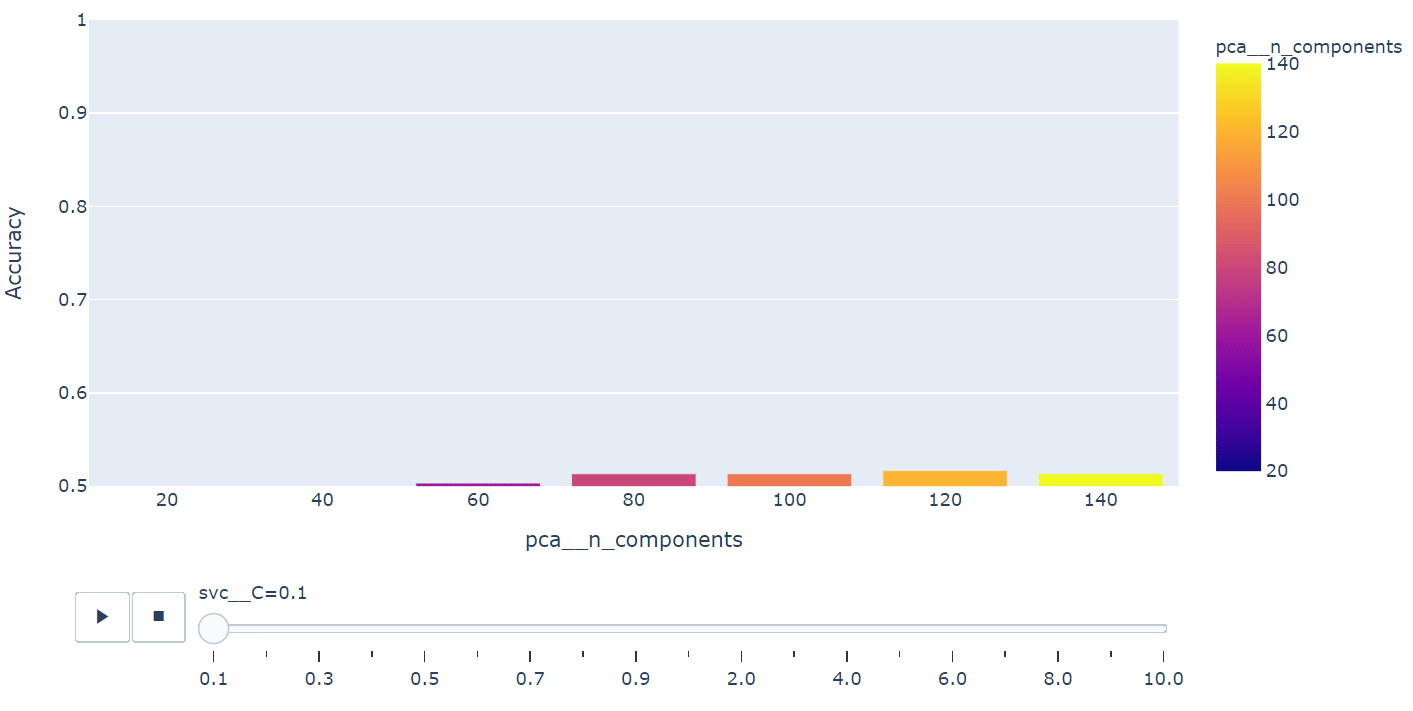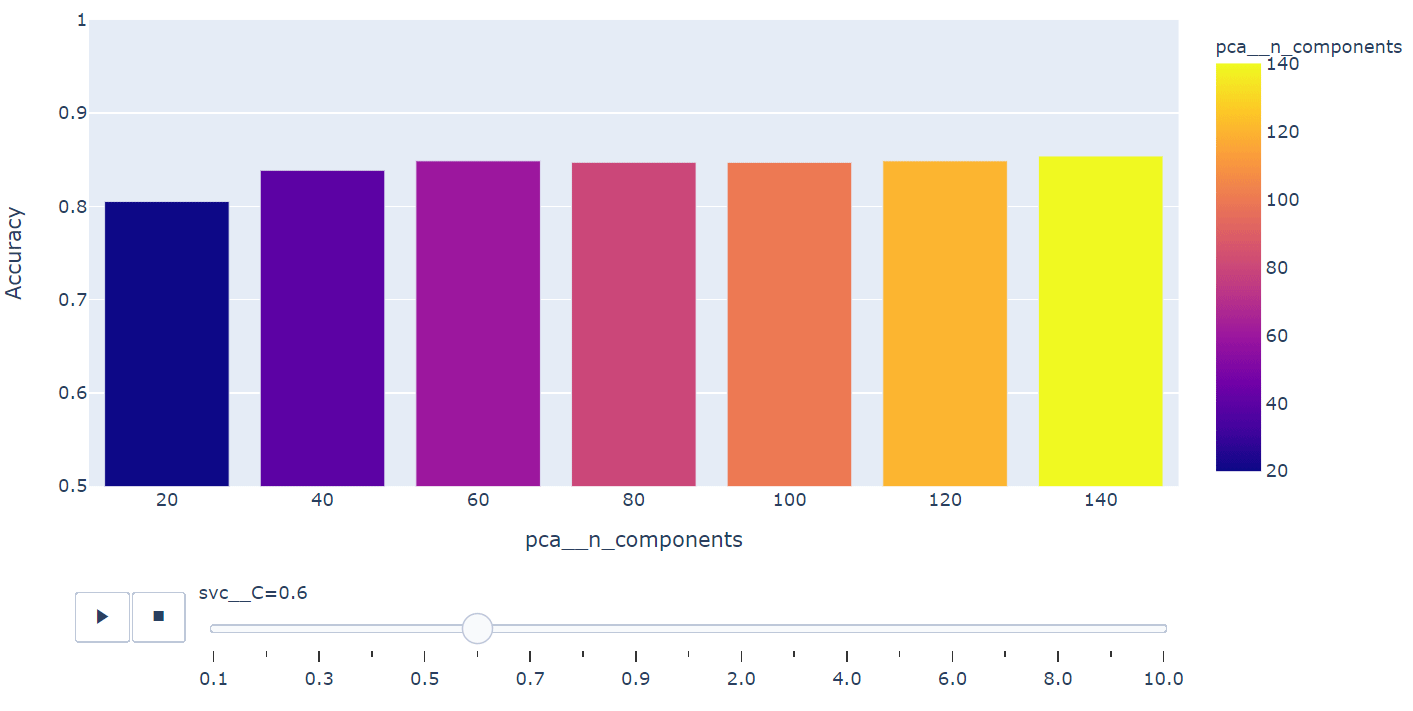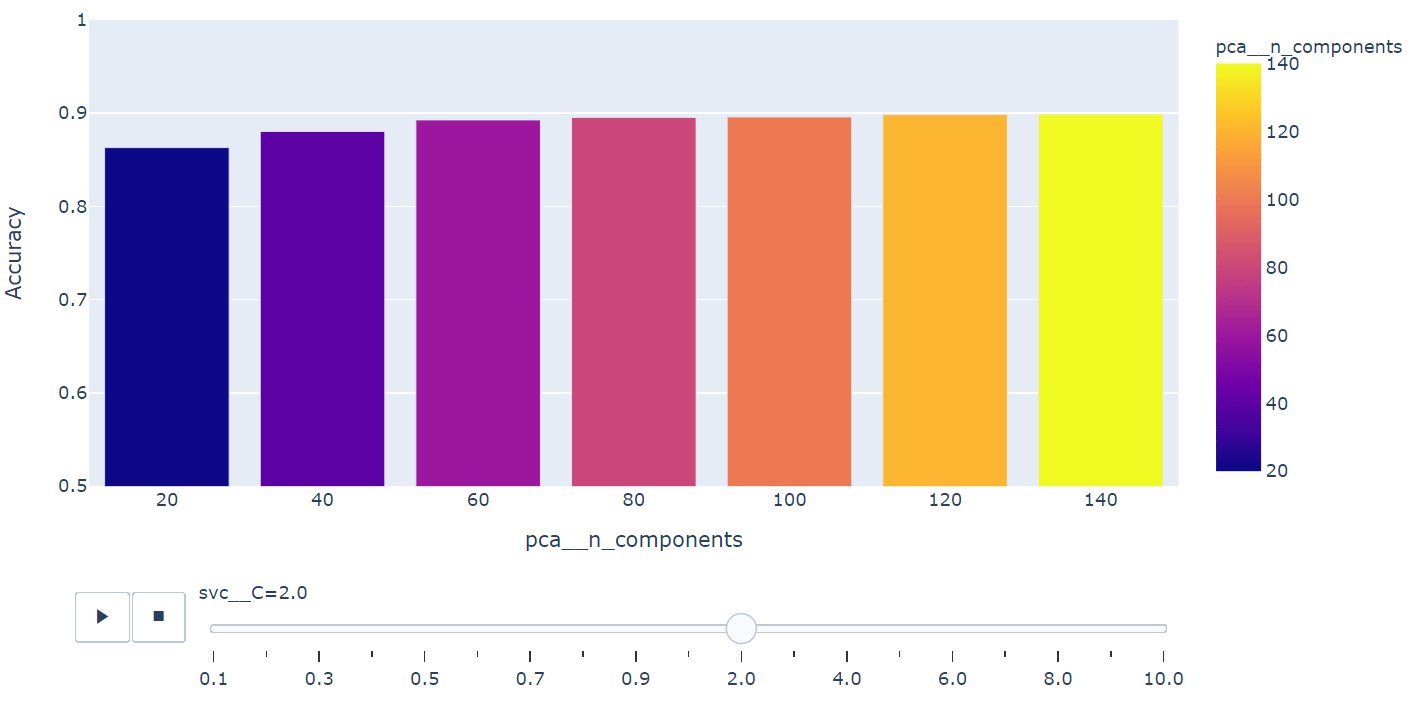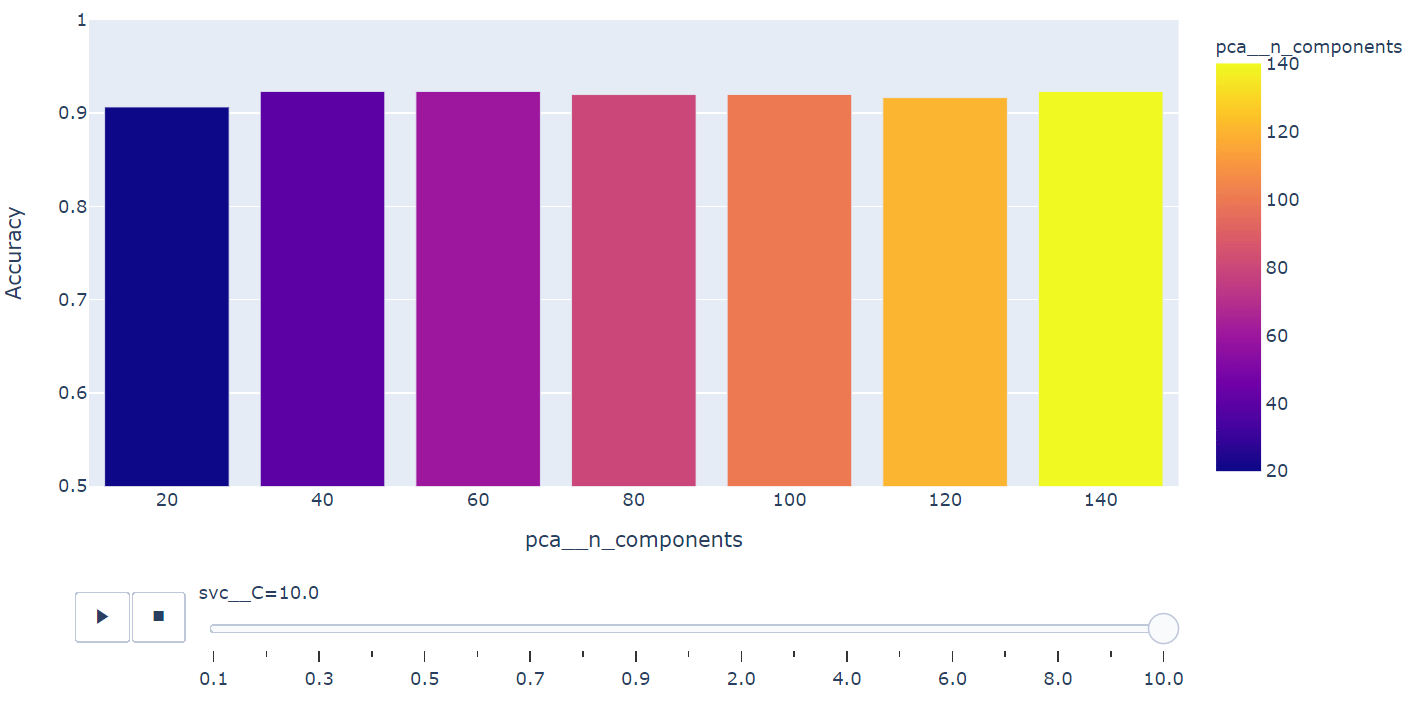
Grid Search를 통해 앞서 setting 탐색범위를 확인하고 가장 좋은 성능의 모델을 추출합니다.
1
2
3
4
5
6
## kenel-PCA & SVM 성능평가
y_pred = clf.predict(X_train)
print("학습용 데이터 성능 [{}]".format(accuracy_score(y_train, y_pred)))
y_pred = clf.predict(X_test)
print("검증용 데이터 성능 [{}]".format(accuracy_score(y_test, y_pred)))
탐색을 통해 얻은 hyper-parameter를 활용하여 Kernel-PCA와 SVM 만을 활용했을 때 검증용 데이터에서 성능을 측정합니다. 성능측정 결과 0.915의 정확도가 도출되었습니다. 즉 Kernel-PCA와 SVM만으로도 충분히 40개의 얼굴 이미지는 분류가 가능하다는 것을 확인할 수 있습니다.
3. Neural Network 구축
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class NeuralNetwork(nn.Module):
def __init__(self, hidden_size, class_size):
super(NeuralNetwork, self).__init__()
self.fc = nn.Sequential(
nn.BatchNorm1d(class_size),
nn.Linear(class_size, hidden_size),
nn.Tanh(),
nn.BatchNorm1d(hidden_size),
nn.Linear(hidden_size, class_size),
)
def forward(self, x, label=None):
output = self.fc(x)
return output
Neural Network를 구축합니다. scaling 되지 않은 input을 처리해야 하므로 빨리 수렴할 수 있도록 본 논문에서 제시한 구조와는 조금 다르게 BatchNorm을 사용하였습니다. 또한 본 논문에서는 Neural Network에 넣기 전 SVM에 tanh activation을 적용하도록 제시하고 있지만 반복 실험한 결과 SVM output에 tanh activation을 적용하면 SVM의 크기 정보가 손실되어 Neural Network가 잘 학습되지 않는 현상이 있습니다. 따라서 SVM output에 비선형 함수를 적용하지 않고 바로 Neural Network의 input으로 활용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
class FaceRecognition(object):
def __init__(self, pca, svm, hidden_size, class_size, learning_rate=0.001):
## PCA, SVM setting
self.pca = pca
self.svm = svm
self.class_size = class_size
## Neural Network 구축
self.network = NeuralNetwork(hidden_size, class_size)
## loss
#self.loss = nn.MSELoss()
self.loss = nn.CrossEntropyLoss()
self.optimizer = optim.Adam(self.network.parameters(), lr=learning_rate)
## 변환 함수
def transform(self, x, label=None):
## PCA를 이용하여 데이터 변환
projected_x = self.pca.transform(x)
## SVM Score 산출
class_scores = self.svm.decision_function(projected_x)
## Neural Network로 정규화
tensor_score = torch.tensor(class_scores, dtype=torch.float)
output = self.network(tensor_score)
## Label 이 있는 경우
if label is not None:
label = torch.tensor(label, dtype=torch.long)
## MSE를 이용하여 loss 계산
return self.loss(output, label)
return output
## 학습용 함수
def fit(self, x, label):
self.network.train()
self.network.zero_grad()
loss = self.transform(x, label)
loss.backward()
self.optimizer.step()
return float(loss)
## 예측용 함수
def predict(self, x):
self.network.eval()
with torch.no_grad():
output = self.transform(x)
output = output.argmax(dim=1).cpu().numpy()
return output
def raw_predict(self, x):
## PCA를 이용하여 데이터 변환
projected_x = self.pca.transform(x)
## SVM Score 산출
return self.svm.predict(projected_x)
최종 얼굴분류 알고리즘 클래스를 다음과 같이 구성합니다.
앞 단계에서 얻은 hyper-parameter로 setting된 PCA와 SVM을 내부적으로 활용합니다.
학습용 데이터로 Neural Network가 학습할 수 있도록 fit함수를 만들었습니다.
또한 학습된 모델로 예측할 수 있도록 함수 predict를 구성하였습니다.
4. Neural Network 학습
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
## Best SVM, PCA 모델 hyper-parameter setting
degree = clf.best_estimator_.get_params()['pca__degree']
n_components = clf.best_estimator_.get_params()['pca__n_components']
C = clf.best_estimator_.get_params()['svc__C']
svm = SVC(class_weight ='balanced', C=C)
pca = KernelPCA(kernel="poly", degree=degree, n_components=n_components)
## SVM, PCA Fitting
X_transformed = pca.fit_transform(X_train)
svm.fit(X_transformed, y_train)
## 최종 모델 구축
hidden_size = 10
model = FaceRecognition(pca, svm, hidden_size=n_classes , class_size=n_classes, learning_rate=0.002)
## training epoch 설정
epochs = 300
## 학습하기
progress_bar = tqdm(range(epochs), desc='Epoch')
for epoch in progress_bar:
loss = model.fit(X_train, y_train)
progress_bar.set_postfix_str("loss [{}]".format(loss))
## 최종 모델 성능평가
y_train_pred = model.predict(X_train)
print("학습용 데이터 성능 [{}]".format(accuracy_score(y_train, y_train_pred)))
y_test_pred = model.predict(X_test)
print("검증용 데이터 성능 [{}]".format(accuracy_score(y_test, y_test_pred)))
Neural Network 학습 후 성능을 평가합니다. 성능 평가 결과 학습용 데이터는 1.0 정확도 성능을 보이고, 검증용 데이터는 0.8 정확도 성능을 보입니다.
최종모델을 활용한 결과 학습용 데이터에서는 SVM+PCA 만을 사용한 경우와 비슷한 정확도를 보입니다. 하지만 검증용 데이터에서 평가 결과 최종모델이 SVM+PCA 모델보다 좋지 못한 성능을 보이는 것을 확인 할 수 있습니다. 저자의 주장과는 다르게 SVM+PCA 결과를 Neural Network로 normalize하는 것이 오히려 안 좋은 결과로 도출되었습니다. 개인적으로 생각해 봤을 때 이미 SVM은 PCA를 통해 도출한 특징점을 보고 가장 합리적인 Output인 각 class에 대한 점수를 추출합니다. 이 점수가 neural network에 들어가면 neural network는 SVM의 다른 것들을 보며 가중치 합으로 최종 output을 만듭니다. 즉 neural network가 만든 최종 output은 단순히 SVM으로부터 도출된 각 class 점수를 normalize 하는것이 아니라 복잡한 연산을 통해 다른 class 점수도 함께 이용하여 output을 구성합니다. SVM의 합리적인 결과를 그대로 사용하지 않고 SVM 끼리 상호 작용까지 고려한 결과를 도출한 것입니다. 상호작용이 있었다면 검증용데이터에서 성능향상을 볼 수 있었겟지만 상호작용이 없었기 때문에 더 안 좋은 결과가 나온 것으로 생각됩니다. 오히려 PCA 결과를 neural network에 바로 활용한 것이 좋은 결과를 도출 할 수 있는 방법이라고 생각합니다.(물론 데이터가 많은 데이터셋에서 유효한 방식입니다.)
[주피터 파일(튜토리얼)]에서 튜토리얼의 전체 파일을 제공하고 있습니다.
Reference
- [PAPER] Face Recognition Using Kernel Principal Component Analysis, 2002
- [BLOG] Face Recognition Using PCA Implementation,
- [YOUTUBE] Kernel-based Learning - KPCA, 강필성