[코드리뷰] - Deep Exploration via Bootstrapped DQN, NIPS 2016
딥러닝, 강화학습 등이 사회에 보편적으로 알려져 있지 않던 2016년 3월 구글 딥마인드에서 만든 알파고와 당시 세계 바둑 랭킹 2위인 이세돌 9단과의 세기의 대결이 펼쳐졌습니다. 5국의 바둑 대결에서 놀랍게도 알파고가 이세돌 9단을 4대1로 이기고 우승을 차지하였습니다. 이후 많은 사람들이 당시 대결로부터 큰 충격과 영감을 받았으며 딥러닝과 강화학습의 가능성에 큰 기대를 갖고 투자를 시작하여 현재 해당 분야는 많은 발전을 이루었습니다.

현재는 다양한 강화학습 모델이 존재하고 있으며 다양한 분야에 활용되고 있습니다. 강화학습의 종류는 여기 를 참조하시기 바랍니다.
오늘 포스팅에서는 강화학습 모델 중 하나인 DQN(Deep Q Network)에 bootstrapping 방법을 적용한 Ensemble 모델인 Bootstrapped DQN 에 대해 다루도록 하겠습니다.
이 글은 Deep Exploration via Bootstrapped DQN 논문을 참고하여 정리하였음을 먼저 밝힙니다.
논문을 간단하게 리뷰하고 pytorch 라이브러리를 이용하여 코드를 구현한 내용을 자세히 설명드리겠습니다.
혹시 제가 잘못 알고 있는 점이나 보안할 점이 있다면 댓글 부탁드립니다.
Short Summary
이 논문의 큰 특징 3가지는 아래와 같습니다.
- 강화학습 모델 DQN을 변형한 앙상블 모델인 Bootstrapped DQN의 아키텍처를 제시합니다.
- Mask를 만들어 Replay Momory에 저장되어 있는 데이터를 각 앙상블 모델에 할당하는 Boostraping 방법론을 제시합니다.
- 앙상블 모델이 기존 DQN보다 빠른 시간 안에 학습할 수 있다는 것을 실험적으로 증명합니다.
논문 리뷰
Deep Q Learning 이란?
논문에서 활용한 base 모델인 DQN(Deep Q Network)에 대한 짧은 개념을 먼저 소개하고 논문리뷰를 시작하겠습니다. 이 내용은 Playing Atari with Deep Reinforcement Learning 논문과 Greentec’s 블로그 를 참고하여 정리하였습니다. DQN 모델을 이해하기 위해서는 먼저 강화학습이 다루는 문제가 어떤 것인지 살펴보겠습니다.
[1] Deep Q Learning 기초
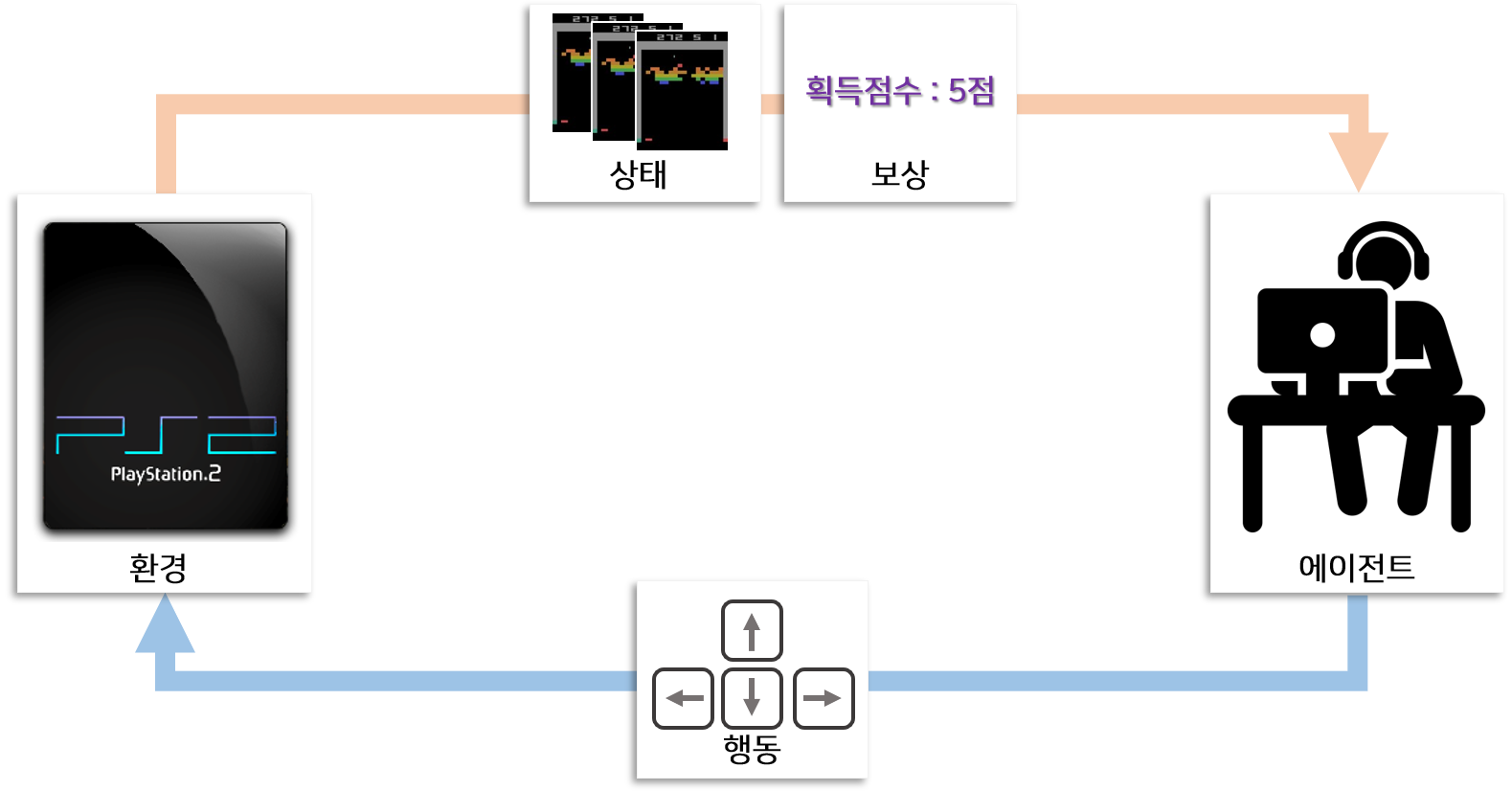
강화학습에는 환경(Environment)과 에이전트(Agent)가 있습니다. 이 포스팅에서는 게임을 예제로 다룰 것이니 환경을 게임기라고 하고 에이전트를 사람 또는 딥러닝 에이전트라고 생각해 봅시다. 게임기는 매 시점 마다 현재 게임에서 어떤 상황인지를 파악할 수 있는 정보인 상태(State) 와 보상(Reward) 에 대한 정보를 제공합니다. 게임에서 상태는 게임화면이라고 볼 수 있고 보상은 획득점수 또는 깨진 블럭수(블럭깨기 게임)로 볼 수 있습니다.
그 정보를 보고 에이전트는 매 시점에서 어떤 행위를 취해야 할지 결정하고 행동을 환경에 전달하게 됩니다. 게이머가 방향키 키보드를 누르는 행위를 행동의 예로 들 수 있습니다.

매 시점 보상이 생성되는 게임도 있지만 일반적으로 이벤트(블럭이 감소)가 발생한 특정시점에 생성됩니다. 강화학습의 목표는 매 시점 주어진 환경에서 보상을 최대한 많이 받을 수 있도록 에이전트를 만드는 것(학습)입니다.
강화학습 모델 중 DQN은 상태와 행동을 가치(Value)로 치환하는 함수 Q함수 를 만들어 강화학습에 적용하는 방법론입니다.
이 방법은 매 시점 상태(게임화면)를 보고 특정 행위(왼쪽, 오른쪽)를 선택했을 때 얻을 수 있는 가치(Value)를 모델링 하는 방법입니다.
즉 특정 상태(게임화면)를 보고 특정 행위(왼쪽, 오른쪽)을 선택했을 때 얻을 수 있는 보상을 알 수 있다면 매 시점 가장 큰 미래의 보상을 보장하는 행위를 선택하면 되는 문제로 바뀔 수 있습니다.

현재 시점의 상태를 $s$라고 하고, 현재 시점에 취한 행동을 $a$라고 한다면 지금 상태($s$)에서 행동($a$)를 취했을 때 가치 Q함수는 $Q(s, a)$로 표현합니다.
현재 상태($s$)에서 행동($a$)을 취한 후 도달한 다음 시점의 상태를 $\grave{s}$ 라고 하고 다음 시점의 행동을 $\grave{a}$ 라고 한다면 상태($\grave{s}$)에서 행동($\grave{a}$)을 취했을 때 가치는 $Q(\grave{s}, \grave{a})$ 입니다.
현재 시점의 가치와 미래 시점의 가치를 이용하여 아래와 같이 표현할 수 있습니다.
$R$ 은 상태($s$)에서 행동($s$)를 취했을 때 받을 수 있는 즉각적인 보상을 의미합니다. 보상은 게임에서는 블럭 한개를 깻을 때 받을 수 있는 점수와 같습니다. 즉 위의 식은 상태($s$)에서 행동($s$)을 취했을 때 받을 수 있는 가치는 즉각적인 가치와 미래 가치를 더한 것이라는 것을 의미합니다.
다만 게임의 경우 빠른 시간에 보상을 얻어 게임을 끝내는 것이 더 좋은 결과이므로 미래 가치에는 시간에 따른 감가율($\gamma$)이 적용되어야 합니다. 또한 다음 시점의 상태($\grave{s}$)에서 일반적으로 가장 이득을 취할 수 있는 행동을 취할 것이므로 이를 반영하면 위의 식을 변형하여 아래와 같이 표현할 수 있습니다.
Q함수 대한 정의를 하였고, 이제 위에서 정의한 것처럼 $Q(s,a)$ 가 $R + \gamma \cdot max Q(\grave{s}, \grave{a})$ 에 가까워지게 만들면 됩니다.
현재 $Q(s,a)$와 $R + \gamma \cdot max Q(\grave{s}, \grave{a})$ 의 차이에 학습율 $\alpha$를 곱하여 점진적으로 Q함수를 근사하는 것이 바로 DQN 강화학습의 목표입니다.
이는 아래와 같이 표현 할 수 있습니다.
이제 실제 게임과 연결지어 앞서 설명한 내용을 적용하는 방법에 대해 생각해 보겠습니다.
DQN의 핵심을 간략하게 서술했기 때문에 기반지식 없이 이해하기 어려울 수 있습니다. 강화학습의 자세한 내용은 강화학습 알아보기 BLOG 를 방문하시어 확인하시기 바랍니다.
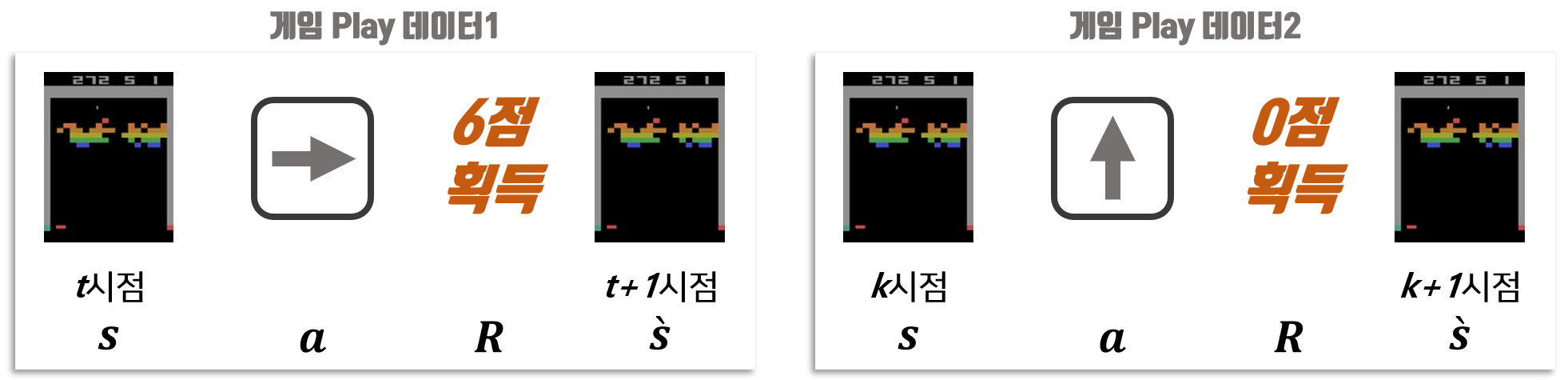
컴퓨터 또는 사람이 게임한 내용을 저장하고 있다고 가정합니다. 게임한 내용은 특정 시점에서 화면($s$), 그 시점에서 조작한 행동($a$), 그 행동을 통해 생성된 보상($R$), 그 행동을 통해 다음 시점 변경된 게임화면($\grave{s}$)을 포함하고 있습니다.
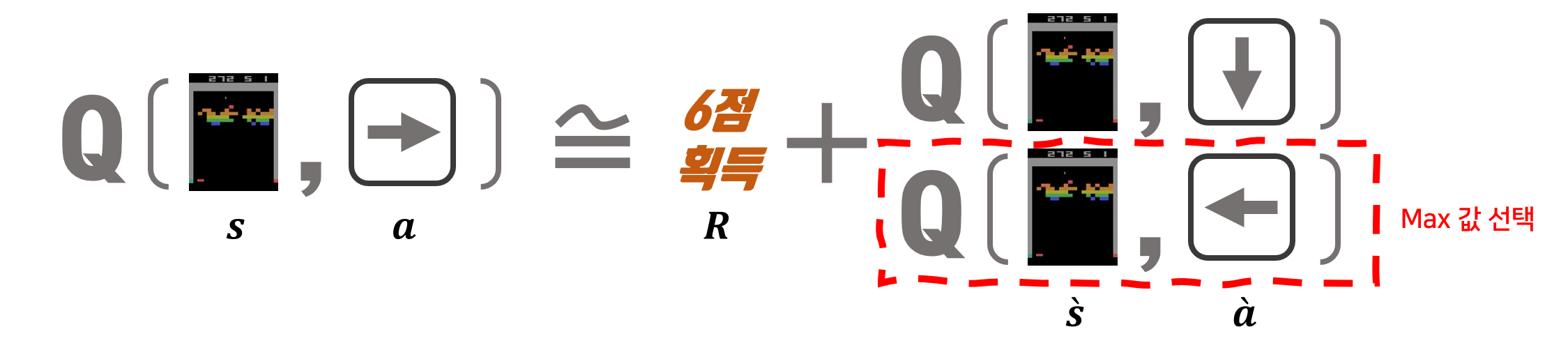
이 데이터를 이용하면 그림과 같이 쉽게 식을 구성할 수 있습니다.
이제 앞서 설명한 것처럼 Q함수를 잘 근사하는 모델을 만들고 학습하면 됩니다.
[2] Deep Q Learning 아키텍처
DQN은 Deep Neural Network를 이용하여 Q함수를 근사한 아키텍처를 의미합니다.
Q함수는 게임 화면($s$)를 입력으로 받고 각 행동($s$)에 따라 얼마만큼 가치가 있는지 추출할 수 있어야 합니다.
이를 딥러닝 아키텍처로 표현한 DQN은 아래와 같습니다.
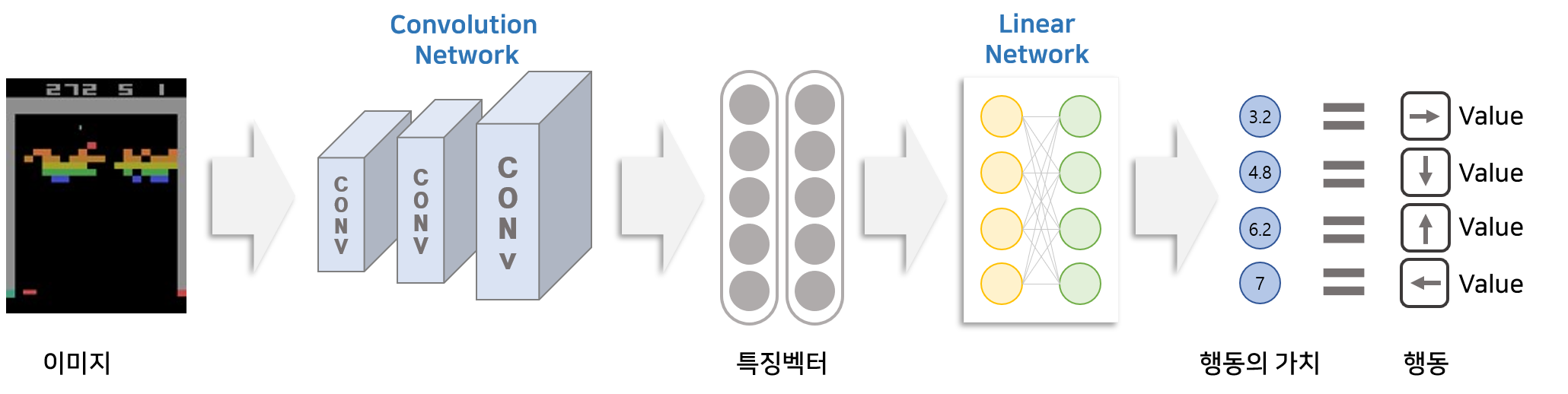
DQN은 크게 Convolution Network와 Linear Layer로 구성되어 있습니다. 입력으로 게임 이미지(환경)가 3개의 Convolution Network를 통과하면 특징벡터가 생성됩니다. 생성된 특징벡터를 Linear Layer에 넣으면 행동의 갯수 만큼 벡터가 생성됩니다. 이 벡터의 요소들이 각각 의미하는 것은 입력으로 넣은 이미지(환경)에서 특정 방향키(행동)을 했을 때의 가치입니다.
[3] Deep Q Learning 학습 구조
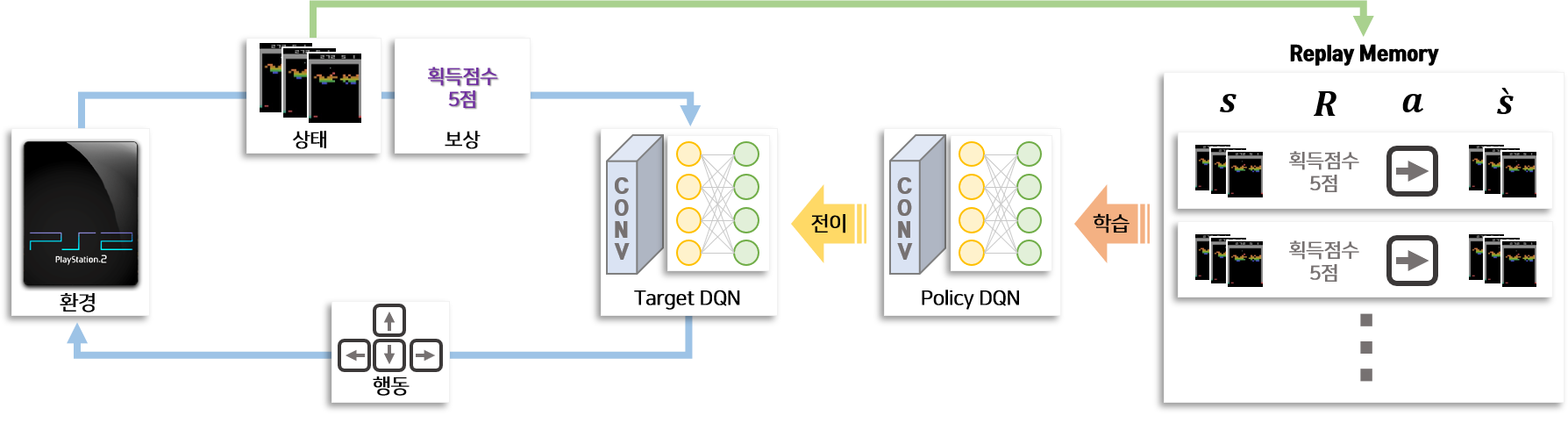
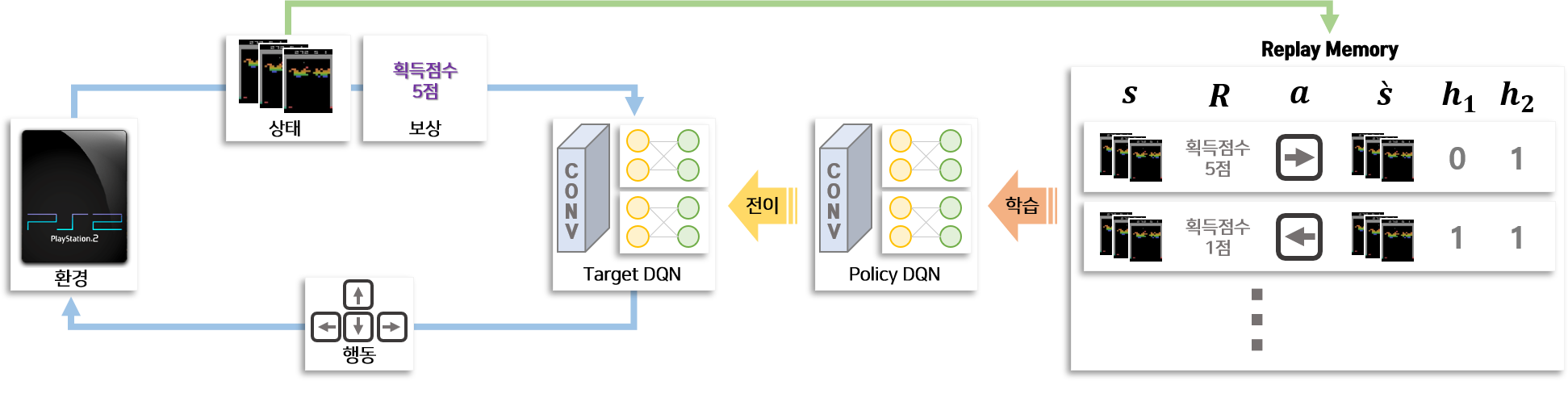
다음은 Atari 게임을 하면서 DQN의 학습 과정의 전체적인 모습을 보겠습니다. 상호작용하는 객체는 환경, Target DQN, Policy DQN, Replay Memory가 있습니다.
파란색 선으로 표기된 게임 play 과정 부터 살펴보겠습니다. 파란색 선에 있는 환경은 게임기를 의미합니다. 이 게임기는 입력으로 행동(방향키)를 받고 출력으로 상태(게임화면)과 보상(점수)를 제공합니다. Target DQN은 상태(게임화면)과 보상(점수)을 입력으로 받고 행동을 출력하는 Deep Nueral Network 입니다. Target DQN은 각 행동(방향키)에 대한 점수를 생성하므로 게임을 Play하여 상호작용 할 때에는 매번 DQN을 통해 나온 행동(방향키) 중 점수가 높은 행동(방향 한개)을 선택하여 상호작용합니다. 즉 게임기와 Target DQN의 상호작용에 따라 게임이 Play 되며, 이로부터 지속적으로 상태와 보상 그리고 행동과 관련된 데이터가 생성됩니다.
다음은 초록색 선으로 표기된 데이터 저장 단계를 살펴보겟습니다. 게임기와 Target DQN의 상호작용으로 생성된 데이터는 초록색 선으로 표기된 방향으로 이동하여 Replay Memory에 저장됩니다. Replay 메모리에 저장되는 데이터는 특정 시점에서 게임화면($s$), 그 시점에서 조작한 행동($a$), 그 행동을 통해 생성된 보상($R$), 그 행동을 통해 다음 시점 변경된 게임화면($\grave{s}$)을 포함하고 있습니다.
다음은 학습 과정입니다. 빨간색으로 표기된 선처럼 강화학습의 학습과정은 Replay Memory에 저장되어 있는 데이터를 이용합니다. Replay Memory에 저장되어 있는 데이터를 Batch 형태로 갖고 와서 Policy DQN을 학습합니다. 파란색 과정에서 생성된 데이터를 이용하여 바로 학습하지 않고 Replay Memory를 만드는 이유는 Replay Memory에 저장된 여러개의 데이터를 랜덤으로 샘플링하여 Batch 단위로 학습하기 위해서 입니다. 랜덤으로 샘플링하기 때문에 batch 데이터는 평향되어 있지 않아 학습을 원할하게 하며, 이전 시점에 생성된 데이터를 재활용하여 학습의 안전성을 높일 수 있습니다.
마지막으로 전이 과정입니다. 학습과정을 통해 사용자가 설정한 횟수 만큼 Policy DQN을 학습한 후 Policy DQN의 학습 정보(Weights)를 Target DQN에 전달합니다. 즉 Policy DQN을 복제하여 Target DQN으로 교체하는 것을 의미합니다. Policy DQN과 Target DQN을 따로 만들고 전이하는 과정을 적용한 이유는 DQN을 이용하여 파란색 선처럼 환경과 상호작용할 때 DQN이 학습되어 매 시점 동일한 상태(게임화면)에서 다른 행동(방향키)을 하게 되면 학습에 방해가 되기 때문입니다.
Bootstrapped DQN 이란?
Bootstrapped DQN이란 DQN에서 설명한 강화학습 구조에 Bootstrapping 방법을 적용하여 만든 앙상블 모델입니다. Bootstrapped DQN은 DQN과 총 4부분이 다릅니다.
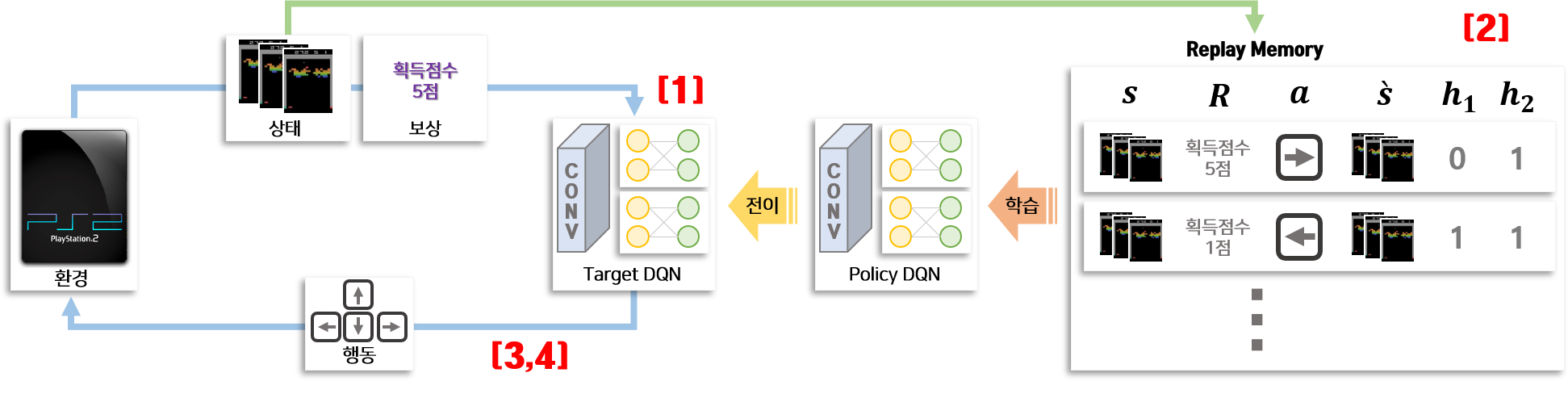
- 앙상블 DQN 모델의 구조
- Replay Memory 저장 구조
- 데이터 수집할 때 앙상블 DQN의 행동을 선택하는 방법
- 평가 할 때 앙상블 DQN의 행동을 선택하는 방법
[1] 앙상블 DQN 아키텍처
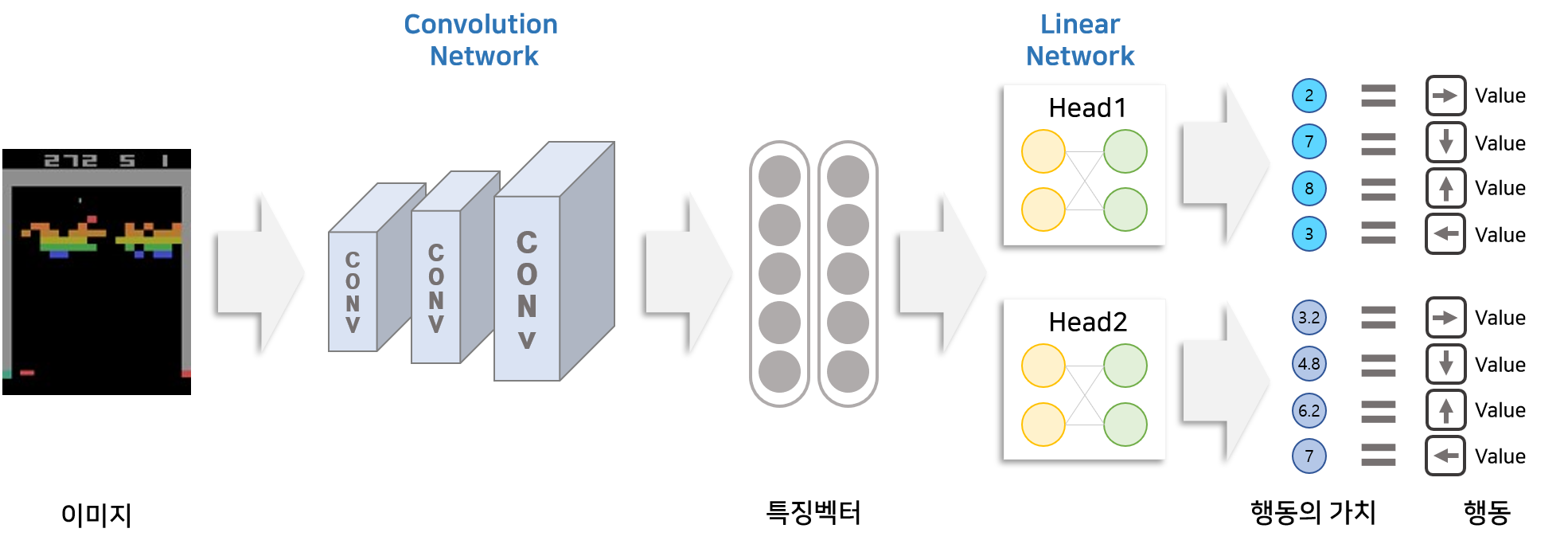
앙상블 DQN의 입력과 출력은 DQN과 동일합니다. 앙상블 DQN은 입력으로 이미지(게임화면)을 받고 Neural 각 행동(방향키)에 대한 가치를 출력합니다. 앙상블 DQN은 DQN과의 차이점은 Linear Layer 부분입니다. 앙상블 DQN은 k개의 Linear Layer를 구성하고 이를 Head라고 부릅니다. Convolution Network를 통해 나온 특징벡터는 각각 Head에 들어가 행동(방향키)에 대한 가치로 변환됩니다. 즉 앙상블 DQN은 Convolution Network를 공유하지만 Linear Network는 따로 설계함으로써 서로 다른 행동(방향키)를 출력할 수 있도록 만든 앙상블 모델입니다.
[2] Replay Memory with Bootstrapping
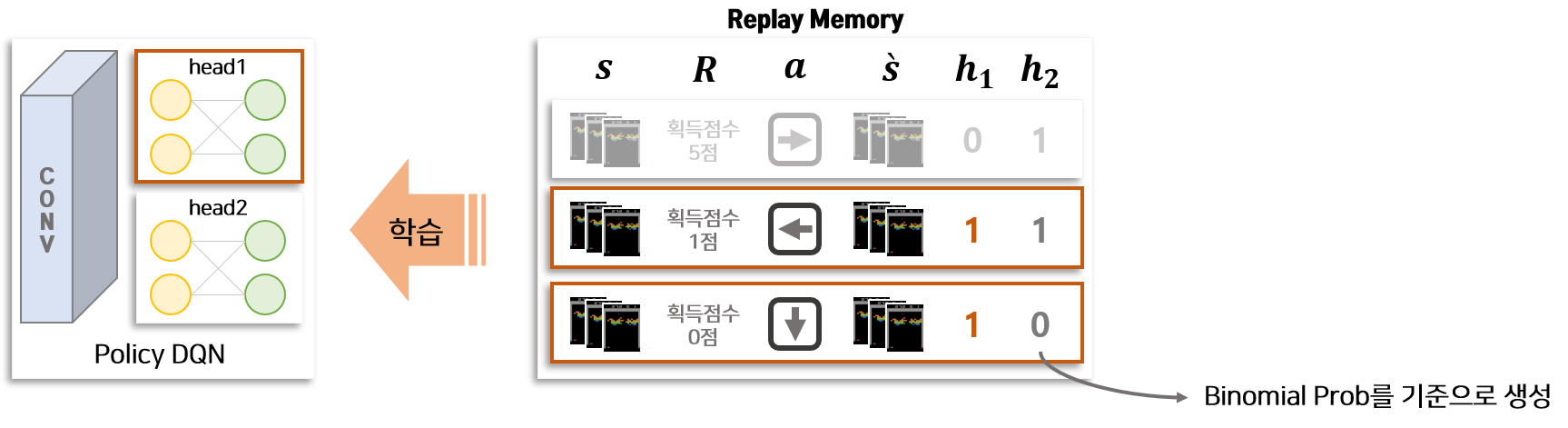
Bootstrapped DQN은 Bootstrapping을 적용하기 위하여 학습 데이터를 저장하고 있는 Replay Memory에 한가지 태그 정보($h_1, h_2, …, h_k$)를 추가합니다. 태그 정보가 의미하는 것은 특정 Replay 데이터를 Bootstrapped DQN의 특정 Head의 학습에 사용할지 여부입니다. 테그 정보는 binomial 분포를 통해 0 또는 1이 부여됩니다. 같은 Replay 데이터가 여러개의 Head로 할당 될 수 있습니다. 위의 그림에서 처럼 Head가 2개이고 Head1을 학습할 때 사용하는 Replay 데이터는 $h_1$ 이 1로 태깅된 데이터 입니다. 테깅을 통해 앙상블 DQN의 각 Head를 서로 다른 데이터로 학습할 수 있습니다. 이는 데이터를 복원 추출함으로써 Bootstrapping을 적용하는 일반적인 앙상블의 학습 과정과 비슷한 장치로 볼 수 있습니다.
[3] 앙상블 DQN 행동 선택 방법(수집)
.png)
게임과 같은 강화학습의 구조는 시작과 끝이 있습니다. 게임에서 공을 놓쳐 life가 0이 되거나 특정 시간이 지나면 게임이 종료 됩니다. 게임을 시작한 후 끝나게 되는 지점까지를 episod라고 부릅니다. 일반적으로 환경과 상호작용할 때 여러번 episod를 반복하여 수행합니다. DQN의 경우 head가 1개이기 때문에 target DQN의 가치에 따라 행동을 결정하여 episod를 진행하면 됩니다. 앙상블 DQN의 경우 head가 여러개이기 때문에 episod를 진행할 때 어떤 head를 사용해야 할지를 결정합니다. 즉 각 episod에서 행동을 결정할 때 쓰는 DQN의 head는 1개로 고정하고 사용합니다. 이렇게 함으로써 episod별 다양한 데이터를 확보할 수 있다는 장점을 갖고 있습니다.
[4] 앙상블 DQN 행동 선택 방법(평가)
.png)
학습한 앙상블 DQN을 이용하여 평가할 때 행동을 선택하는 방법은 Voting입니다. 상태(게임화면)을 입력으로 넣으면 앙상블 모델의 각 head로 부터 행동의 가치가 추출됩니다. 각 head별 행동의 가치가 높은 행동(방향키)을 각각 도출한 후 각 행동의 빈도가 가장 많은 행동을 최종 행동으로 선택합니다.
코드 구현
1. 라이브러리 Import & 설치
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import gym
from torch import nn, optim
import torch.nn.functional as F
import torch
from collections import deque
import numpy as np
import os
from tqdm import tqdm
import logging
from model import EnsembleNet
from properties import build_parser, CONSOLE_LEVEL, LOG_FILE, LOGFILE_LEVEL
from repository import historyDataset, memoryDataset
import sys
import traceback
from PIL import Image
from collections import Counter
from argparse import ArgumentParser
from collections import deque
from collections import namedtuple
import numpy as np
import random
from skimage.transform import rescale
from skimage.transform import resize
모델을 구현하는데 필요한 기본 라이브러리를 Import 합니다. Import 에러가 발생하면 해당 라이브러리를 설치한 후 진행해야 합니다.
강화학습의 환경에 해당하는 게임은 GYM 이라는 라이브러리를 사용함으로써 해결 할 수 있습니다.
GYM은 OpenAI 에서 제공하고 있는 가상환경 라이브러리 입니다.
이 라이브러리는 다양한 환경을 제공하고 있으나 본 튜토리얼에서는 아타리 게임 중 하나인 breakout_4 를 활용하겠습니다.
GYM 라이브러리 설치 방법은 [OpenAI 공식 사이트] 에서 가이드를 제공 받을 수 있습니다.
하지만 해당 라이브러리는 Linux OS를 기반으로 Build 되었기 때문에 Windows OS 에서 활용하기 위해서는 Wrapper가 필요합니다.
Windows OS에서 GYM 라이브러리 설치하는 방법은 [GYM 설치방법 안내] 를 참고하시기 바랍니다.
GYM 라이브러리를 정상정으로 설치한 후 게임이 잘 작동하는지 확인해 봅니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import gym
from PIL import Image
## 벽돌깨기 게임 환경 생성
env = gym.make('BreakoutDeterministic-v4')
## 환경 초기화
state = env.reset()
frames_game = []
for _ in range(30):
## render 함수를 이용하여 화면 불러오기
img = env.render(mode='rgb_array')
img = Image.fromarray(img)
frames_game.append(img)
action = env.action_space.sample()
next_state, reward, done, _ = env.step(action)
state = next_state
## 이미지를 gif로 저장
frames_game[0].save('play_breakout.gif', format='GIF', append_images=frames_game[1:], save_all=True, duration=0.0001, loop=0)
## 환경 종료
env.close()
위의 예를 통해 게임이 잘 작동한다는 것을 확인할 수 있습니다.
gym.make 함수를 이용하여 원하는 게임의 가상환경을 불러올 수 있습니다.
gym.render는 게임의 화면을 이미지로 받아오는 기능을 담당합니다.
env.step(action)은 가상환경에 행동(action)을 넣으면 그 이후 발생될 화면과, 보상 그리고 게임이 끝낫는지 여부를 반환합니다.
2. 앙상블 DQN 구현
앙상블 DQN은 CoreNet과 여러개의 head로 구성되어 있습니다. CoreNet은 이미지로부터 특징벡터를 추출해 주는 3개의 Convolution Network입니다. head는 Linear Layer로 구성되어 있습니다. 앙상블 DQN에 기본이 되는 CoreNet과 HeadNet을 구현합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
class HeadNet(nn.Module):
def __init__(self, reshape_size, n_actions=4):
super(HeadNet, self).__init__()
self.fc1 = nn.Linear(reshape_size, 512)
self.fc2 = nn.Linear(512, n_actions)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
class CoreNet(nn.Module):
def __init__(self, h, w, num_channels=4):
super(CoreNet, self).__init__()
self.num_channels = num_channels
self.conv1 = nn.Conv2d(self.num_channels, 32, 8, 4)
self.conv2 = nn.Conv2d(32, 64, 4, 2)
self.conv3 = nn.Conv2d(64, 64, 3, 1)
# Number of Linear input connections depends on output of conv2d layers
# and therefore the input image size, so compute it.
def conv2d_size_out(size, kernel_size=5, stride=2):
return (size - (kernel_size - 1) - 1) // stride + 1
convw = conv2d_size_out(conv2d_size_out(conv2d_size_out(w, 8, 4), 4, 2), 3, 1)
convh = conv2d_size_out(conv2d_size_out(conv2d_size_out(h, 8, 4), 4, 2), 3, 1)
self.reshape_size = convw * convh * 64
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
# size after conv3
x = x.view(-1, self.reshape_size)
return x
class EnsembleNet(nn.Module):
def __init__(self, n_ensemble, n_actions, h, w, num_channels):
super(EnsembleNet, self).__init__()
self.core_net = CoreNet(h=h, w=w, num_channels=num_channels)
reshape_size = self.core_net.reshape_size
self.net_list = nn.ModuleList([HeadNet(reshape_size=reshape_size, n_actions=n_actions) for k in range(n_ensemble)])
def _core(self, x):
return self.core_net(x)
def _heads(self, x):
return [net(x) for net in self.net_list]
def forward(self, x, k=None):
if k is not None:
return self.net_list[k](self.core_net(x))
else:
core_cache = self._core(x)
net_heads = self._heads(core_cache)
return net_heads
3. historyDataset 구현
비디오 게임의 정지된 화면을 보고 다음 어떤 상황이 일어날 것인지를 예측하는 것은 매우 어렵습니다.
일반적으로 게임의 이전 몇시점의 화면을 봐야 공의 움직임과 캐릭터의 움직임 등을 파악할 수 있습니다.
따라서 DQN에 입력으로 사용하는 이미지는 1개가 아니라 특정 시점으로 부터 n 시점 이전까지의 생성된 n개의 이미지입니다.
queue 형태의 HistoryDataSet을 만들어 생성된 이미지를 쌓을 수 있게 만들고 출력으로 과거에 생성된 n 개의 이미지를 추출할 수 있도록 구성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
class historyDataset(object):
def __init__(self, history_size, img):
self.history_size = history_size
state = self.convert_channel(img)
self.height, self.width = state.shape
temp = []
for _ in range(history_size):
temp.append(state)
self.history = temp
def convert_channel(self, img):
# input type : |img| = (Height, Width, channel)
# remove useless item
img = img[31:193, 8:152]
#img = rescale(img, 1.0 / 2.0, anti_aliasing=False, multichannel=False)
img = resize(img, output_shape=(84, 84))
# conver channel(3) -> channel(1)
img = np.any(img, axis=2)
# |img| = (Height, Width) boolean
return img
def push(self, img):
temp = self.history
state = self.convert_channel(img)
temp.append(state)
self.history = temp[1:]
def get_state(self):
#return self.history
return copy.deepcopy(self.history)
push 함수는 게임과 상호작용으로 생성된 게임 이미지 1개씩을 넣을 수 있도록 만든 함수입니다.
이 함수는 이미지를 변환하는 작업(convert_channel)을 포함하고 있습니다.
convert_channel 함수는 게임의 이미지에서 중요한 부분을 추출하여 자르는 과정과 자른 이미지를 특정크기로 변환하는 과정을 포함하고 있습니다.

전처리된 이미지는 리스트에 저장됩니다.
사용자가 지정한 n를 유지하도록 되어 있으므로 리스트에 n개가 있을 때 새로운 이미지가 들어오면 앞에 있던 이미지는 퇴출 됩니다.
Replay Memory에 저장할 때에는 get_state 함수를 호출하여 해당 시점에서 과거 n개의 이미지를 가져옵니다.
Replay Memory에 이를 저장하고 학습하는데 활용합니다.
4. memoryDataset 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
class memoryDataset(object):
def __init__(self, maxlen, n_ensemble=1, bernoulli_prob=0.9):
self.memory = deque(maxlen=maxlen)
self.n_ensemble = n_ensemble
self.bernoulli_prob = bernoulli_prob
## if ensemble is 0 then no need to apply mask
if n_ensemble==1:
self.bernoulli_prob = 1
self.subset = namedtuple('Transition', ('state', 'action', 'next_state', 'reward', 'done', 'life', 'terminal', 'mask'))
def push(self, state, action, next_state, reward, done, life, terminal):
state = np.array(state)
action = np.array([action])
reward = np.array(reward)
next_state = np.array(next_state)
done = np.array([done])
life = np.array([life])
terminal = np.array([terminal])
mask = np.random.binomial(1, self.bernoulli_prob, self.n_ensemble)
self.memory.append(self.subset(state, action, next_state, reward, done, life, terminal, mask))
def __len__(self):
return len(self.memory)
def sample(self, batch_size):
batch = random.sample(self.memory, min(len(self.memory), batch_size))
batch = self.subset(*zip(*batch))
state = torch.tensor(np.stack(batch.state), dtype=torch.float)
action = torch.tensor(np.stack(batch.action), dtype=torch.long)
reward = torch.tensor(np.stack(batch.reward), dtype=torch.float)
next_state = torch.tensor(np.stack(batch.next_state), dtype=torch.float)
done = torch.tensor(np.stack(batch.done), dtype=torch.long)
##Life : 0,1,2,3,4,5
life = torch.tensor(np.stack(batch.life), dtype=torch.float)
terminal = torch.tensor(np.stack(batch.terminal), dtype=torch.long)
mask = torch.tensor(np.stack(batch.mask), dtype=torch.float)
batch = self.subset(state, action, next_state, reward, done, life, terminal, mask)
return batch

Replay 메모리에 저장되는 정보는 상태(state), 행동(action), 다음상태(next_state), 보상(reward), 재시작여부(done), 목숨(life), 종료여부(terminal) 가 있습니다.
Replay 메모리는 데이터를 저장하는 기능과 Batch 사이즈로 데이터를 추출하는 기능을 갖고 있어야 합니다.
push 함수는 게임기와 앙상블 DQN을 통해 생성된 데이터를 저장하는 함수입니다.
데이터가 들어오면 numpy 형태로 변환되며 Collection 라이브러리의 deque에 저장되므로 지정한 갯수(Memory size)만큼만 저장됩니다.
데이터가 들어올때 각 데이터가 앙상블 DQN의 어떤 Head에 속할지를 Binomial 확률을 통해 결정합니다.
numpy.random 라이브러리에 binomial 함수를 제공하고 있으므로 이를 활용합니다.
sample 함수는 앙상블 DQN을 학습하기 위하여 batch 형태로 데이터를 불러오는 기능입니다.
numpy 형태로 된 데이터를 불러온 후 batch로 쌓은 후 torch.tensor로 변형합니다.
이후 사용하기 쉽게 미리 지정한 subset tuple 형태로 만들어 제공합니다.
5. DQNSolver 구현
DQNSolver은 크게 2개로 구성되어 있습니다. 앙상블 DQN과 게임기와의 상호 작용하는 부분과 Replay Memory로 앙상블 DQN을 학습하는 부분입니다. 해당 class에 많은 내용을 포함하고 있으므로 나누어 설명드리겠습니다. 전체 모습은 Github 구현체 를 통해 확인하시기 바랍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
class DQNSolver():
def __init__(self, config):
self.device = config.device
self.env = gym.make(config.env)
self.valid_env = gym.make(config.env)
self.memory_size = config.memory_size
self.update_freq = config.update_freq
self.learn_start = config.learn_start
self.history_size = config.history_size
self.batch_size = config.batch_size
self.ep = config.ep
self.eps_end = config.eps_end
self.eps_endt = config.eps_endt
self.eps_start = self.learn_start
self.lr = config.lr
self.discount = config.discount
self.agent_type = config.agent_type
self.max_steps = config.max_steps
self.eval_freq = config.eval_freq
self.eval_steps = config.eval_steps
self.target_update = config.target_update
self.max_eval_iter = config.max_eval_iter
##Breakout Setting
if config.pretrained_dir is not None:
pretrained_config = load_saved_config(config.pretrained_dir)
config.n_ensemble = pretrained_config.n_ensemble
config.class_num = pretrained_config.class_num
config.resize_unit = pretrained_config.resize_unit
policy_model = build_model(config)
target_model = build_model(config)
self.policy_model = load_saved_model(policy_model, config.pretrained_dir)
self.target_model = load_saved_model(target_model, config.pretrained_dir)
else:
config.resize_unit = (84, 84)
config.class_num = 4
self.policy_model = build_model(config)
self.target_model = build_model(config)
self.resize_unit = config.resize_unit
self.class_num = config.class_num
self.n_ensemble = config.n_ensemble
self.policy_model.to(config.device)
self.target_model.to(config.device)
self.optimizer = optim.Adam(params=self.policy_model.parameters(), lr=self.lr)
##Replay Memory Init
self.memory = memoryDataset(maxlen=config.memory_size, n_ensemble=config.n_ensemble,
bernoulli_prob=config.bernoulli_prob)
##INIT LOGGER
if not logging.getLogger() == None:
for handler in logging.getLogger().handlers[:]: # make a copy of the list
logging.getLogger().removeHandler(handler)
logging.basicConfig(filename=LOG_FILE, level=LOGFILE_LEVEL) ## set log config
console = logging.StreamHandler() # console out
console.setLevel(CONSOLE_LEVEL) # set log level
logging.getLogger().addHandler(console)
##save options
self.out_dir = config.out_dir
if not os.path.isdir(config.out_dir):
os.mkdir(config.out_dir)
self.test_score_memory = []
self.test_length_memory = []
self.train_score_memory = []
self.train_length_memory = []
##중간시작
self.start_steps = config.start_steps
self.learn_start = self.learn_start + self.start_steps
self.eval_steps = self.eval_steps + self.start_steps
self.config = config
save_config(config, self.out_dir)
상호작용하는 모습을 구현하기 위하여 필요한 설정과 모델을 생성하는 단계입니다.
중요한 내용은 Replay Memory 생성, policy model 생성, target model 생성 입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
class DQNSolver():
def __init__(self, config):
...
def choose_action(self, history, header_number:int=None, epsilon=None):
if epsilon is not None:
if np.random.random() <= epsilon:
return self.env.action_space.sample()
else:
with torch.no_grad():
state = torch.tensor(history.get_state(), dtype=torch.float).unsqueeze(0).to(self.device)
if header_number is not None:
action = self.target_model(state, header_number).cpu()
return int(action.max(1).indices.numpy())
else:
# vote
actions = self.target_model(state)
actions = [int(action.cpu().max(1).indices.numpy()) for action in actions]
actions = Counter(actions)
action = actions.most_common(1)[0][0]
return action
else:
with torch.no_grad():
state = torch.tensor(history.get_state(), dtype=torch.float).unsqueeze(0).to(self.device)
if header_number is not None:
action = self.policy_model(state, header_number).cpu()
return int(action.max(1).indices.numpy())
else:
# vote
actions = self.policy_model(state)
actions = [int(action.cpu().max(1).indices.numpy()) for action in actions]
actions = Counter(actions)
action = actions.most_common(1)[0][0]
return action
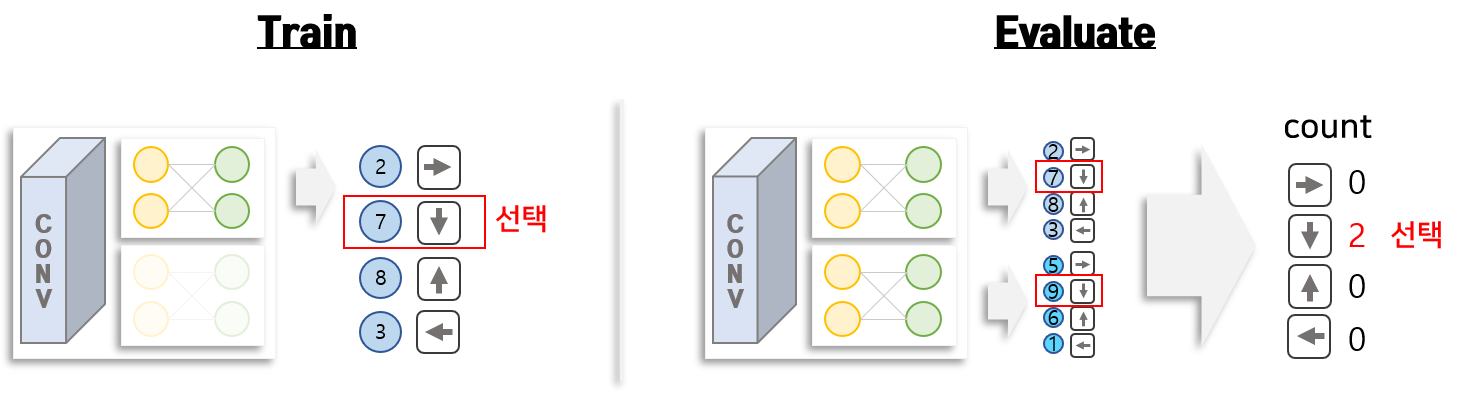
다음은 환경(게임기)와 상호작용 시 앙상블 DQN을 이용하여 행동을 추출하는 부분입니다. 학습 단계에서는 특정 head를 선택하여 그 head에서 생성된 행동의 가치가 가장 높은 행동을 선택하도록 되어 있습니다. 추론 단계에서는 모든 head로부터 각각 행동의 가치를 추출하고 각각 가치가 높은 행동을 선택한 다음 Vote하여 가장 많이 나온 행동을 선택하도록 되어 있습니다.
주의해야 할 점은 아직 학습이 완료되지 않은 DQN을 이용하면 점수를 획득할 수 있는 좋은 움직임을 보여주지 못할 확률이 높습니다.
또한 매번 동일한 행동만을 반복하므로 이를 해결하기 위하여 epsilon을 조건에 포함시킵니다.
epsilon은 0과 1 사이의 값을 가지며 랜덤으로 0과 1사이의 값을 생성한 후 epsilon 보다 낮은 숫자가 나오면 랜덤으로 숫자를 생성하도록 조정합니다.
이를 이용하여 동일한 환경에서 다른 행동을 취하게 하고 다양한 데이터를 확보하는 장치로 사용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
class DQNSolver():
def __init__(self, config):
...
def choose_action(self, history, header_number:int=None, epsilon=None):
...
def replay(self, batch_size):
self.optimizer.zero_grad()
batch = self.memory.sample(batch_size)
state = batch.state.to(self.device)
action = batch.action.to(self.device)
next_state = batch.next_state.to(self.device)
reward = batch.reward
reward = reward.type(torch.bool).type(torch.float).to(self.device)
done = batch.done.to(self.device)
life = batch.life.to(self.device)
terminal = batch.terminal.to(self.device)
mask = batch.mask.to(self.device)
with torch.no_grad():
next_state_action_values = self.policy_model(next_state)
state_action_values = self.policy_model(state)
total_loss = []
for head_num in range(self.n_ensemble):
total_used = torch.sum(mask[:, head_num])
if total_used > 0.0:
next_state_value = torch.max(next_state_action_values[head_num], dim=1).values.view(-1, 1)
reward = reward.view(-1, 1)
target_state_value = torch.stack([reward + (self.discount * next_state_value), reward], dim=1).squeeze().gather(1, terminal)
state_action_value = state_action_values[head_num].gather(1, action)
loss = F.smooth_l1_loss(state_action_value, target_state_value, reduction='none')
loss = mask[:, head_num] * loss
loss = torch.sum(loss / total_used)
total_loss.append(loss)
if len(total_loss) > 0:
total_loss = sum(total_loss)/self.n_ensemble
total_loss.backward()
self.optimizer.step()
다음은 Policy DQN을 학습하는 단계입니다.
Replay 메모리에 어느정도 게임 플레이된 데이터가 쌓여 있으면 replay 함수를 호출하여 앙상블 DQN을 학습합니다.
repaly 함수는 Replay Memory로 부터 batch 크기의 데이터를 불러오는 self.memory.sample 기능과 Policy Network로 Action을 도출하여 Loss를 구하는 부분으로 구성되어 있습니다.
Loss의 식을 보면 위에서 언급한 것처럼 현재 $Q(s,a)$와 $R + \gamma \cdot max Q(\grave{s}, \grave{a})$ 의 차이로 구성되 있는 것을 확인할 수 있습니다. 이 둘을 아래와 같이 구성하여 점진적으로 학습하는 것이 강화학습의 목표입니다.
앙상블 DQN의 경우 여러개의 Head에서 위와 같은 수식으로 Loss를 구할 수 있으므로 이를 합쳐서 Batch로 Update합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
class DQNSolver():
def __init__(self, config):
...
def choose_action(self, history, header_number:int=None, epsilon=None):
...
def replay(self, batch_size):
...
def train(self):
progress_bar = tqdm(range(self.start_steps, self.max_steps))
state = self.env.reset()
history = historyDataset(self.history_size, state)
done = False
##Report
train_scores = deque(maxlen=10)
train_lengths = deque(maxlen=10)
episode = 0
max_score = 0
##If it is done everytime init value
train_score = 0
train_length = 0
last_life = 0
terminal = True
## number of ensemble
heads = list(range(self.n_ensemble))
active_head = heads[0]
try:
for step in progress_bar:
## model update
if step > self.learn_start and step % self.target_update == 0:
self.target_model.load_state_dict(self.policy_model.state_dict())
## game is over
if done:
np.random.shuffle(heads)
active_head = heads[0]
state = self.env.reset()
history = historyDataset(self.history_size, state)
train_scores.append(train_score)
train_lengths.append(train_length)
episode += 1
##If it is done everytime init value
train_score = 0
train_length = 0
last_life = 0
terminal = True
action = self.choose_action(history, active_head, self.get_epsilon(step))
if terminal: ## There is error when it is just started. So do action = 1 at first
action = 1
next_state, reward, done, life = self.env.step(action)
state = history.get_state()
history.push(next_state)
next_state = history.get_state()
life = life['ale.lives']
train_length = train_length + 1
## Terminal options
if life < last_life:
terminal = True
else :
terminal = False
last_life = life
self.memory.push(state, action, next_state, reward, done, life, terminal)
if step > self.learn_start and step % self.update_freq == 0:
self.replay(self.batch_size)
train_score = train_score + reward
if step > self.eval_steps and step % self.eval_freq == 0:
train_mean_score = np.mean(train_scores)
train_mean_length = np.mean(train_lengths)
self.train_score_memory.append(train_mean_score)
self.train_length_memory.append(train_mean_length)
save_numpy(self.train_score_memory, self.out_dir, 'train_score')
save_numpy(self.train_length_memory, self.out_dir, 'train_length_memory')
valid_score, valid_length = self.valid_run()
self.test_score_memory.append(valid_score)
self.test_length_memory.append(valid_length)
save_numpy(self.test_score_memory, self.out_dir, 'test_score')
save_numpy(self.test_length_memory, self.out_dir, 'test_length_memory')
다음은 전체 학습 과정을 포함하는 train 함수 입니다.
이 함수가 하는 역할을 크게 분할하면 게임기와 상호작용하여 행동을 선택하고 데이터를 저장하는 부분과 Replay Memory를 이용하여 DQN을 학습하는 부분으로 나뉘어 있습니다.
env.reset() 함수를 이용하여 환경을 초기화 하고 게임 화면을 하나씩 받아 memory.push 함수를 이용하여 Replay Memory에 저장합니다.
저장된 데이터가 일정 갯수를 초과하면 replay 함수를 호출하여 Replay Memory에 저장된 데이터로 Policy DQN을 학습 합니다.
이렇게 학습을 반복하면서 가장 성능이 높은 모델을 저장하고 종료합니다.
6. 파라미터 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
def build_parser():
parser = ArgumentParser()
parser.add_argument("--mode", dest="mode", metavar="mode", default="train")
parser.add_argument("--device", dest="device", metavar="device", default="gpu")
parser.add_argument("--env",dest="env", metavar="env", default="BreakoutDeterministic-v4")
parser.add_argument("--memory_size", dest="memory_size", metavar="memory_size", type=int, default=int(1e6))
parser.add_argument("--update_freq", dest="update_freq", metavar="update_freq", type=int, default=4)
parser.add_argument("--learn_start", dest="learn_start", metavar="learn_start", type=int, default=50000)
parser.add_argument("--history_size", dest="history_size", metavar="history_size", type=int, default=4)
parser.add_argument("--target_update", dest="target_update", metavar="target_update", type=int, default=10000)
parser.add_argument("--n_ensemble", dest="n_ensemble", type=int, default=9)
parser.add_argument("--bernoulli_prob", dest="bernoulli_prob", type=float, default=0.9)
##Learning rate
parser.add_argument("--batch_size", dest="batch_size", metavar="batch_size", type=int, default=32)
parser.add_argument("--ep", dest="ep", metavar="ep", type=int, default=1)
parser.add_argument("--eps_end", dest="eps_end", metavar="eps_end", type=float, default=0.01)
parser.add_argument("--eps_endt", dest="eps_endt", metavar="eps_endt", type=int, default=int(1e6))
parser.add_argument("--lr", dest="lr", metavar="lr", type=float, default=0.00025)
parser.add_argument("--discount", dest="discount", metavar="discount", type=float, default=0.99)
parser.add_argument("--agent_type", dest="agent_type", metavar="agent_type", default="DQN")
parser.add_argument("--max_steps", dest="max_steps", metavar="max_steps", type=int, default=int(5e7))
parser.add_argument("--start_steps", dest="start_steps", metavar="start_steps", type=int, default=0)
parser.add_argument("--eval_freq", dest="eval_freq", metavar="eval_freq", type=int, default=50000)
parser.add_argument("--eval_steps", dest="eval_steps", metavar="eval_steps", type=int, default=50000)
parser.add_argument("--max_eval_iter", dest="max_eval_iter", metavar="max_eval_iter", type=int, default=10000)
parser.add_argument("--pretrained_dir", dest="pretrained_dir", metavar="pretrained_dir", type=str, default=None)
parser.add_argument("--out_dir", dest="out_dir", metavar="out_dir", type=str, default=None, required=True)
return parser
논문에서 제시한 Default Setting입니다.
memory_size가 크기 때문에 64GB RAM으로도 학습이 어려울 수 있습니다.
따라서 몇가지 파라미터를 조정하여 학습하는데 활용하시기 바랍니다.
7. 강화학습 시작
1
2
3
4
5
6
python breakout.py \
--env=BreakoutDeterministic-v4 \
--device=gpu \
--memory_size=1e5 \
--n_ensemble=9 \
--out_dir=results
메모리 사이즈를 1e5로 줄이고 앙상블의 크기를 9로 설정하여 벽돌깨기 게임의 강화학습을 돌리는 코드입니다. 이외에도 다양한 설정이 있으니 위에 Setting을 참고하시어 변경하기 바랍니다.

8. 결과화면

학습한 강화학습 모델을 이용하여 벽돌깨기 게임을 시각화 한 모습입니다. 총 9개의 앙상블 DQN 모델로 구성되어 있으며 각 모델로부터 매 시점별 최선의 행동(방향)이 추출합니다. Voting을 통해 하나의 행동(방향)으로 움직여 벽돌깨기 게임을 진행합니다.
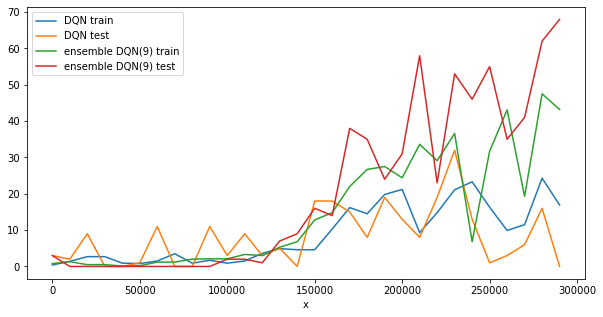
위 그림은 학습 횟수에 따른 성능의 변화를 나타낸 그래프입니다. 실험 환경은 논문에서 제시한 환경과 동일하지 않습니다. 제한된 resource안에서 실험하였기 때문에 논문에서 주장한 성능보다 다소 떨어집니다. 하지만 앙상블 DQN 모델이 DQN보다 빠르게 학습된 다는 것을 확인할 수 있습니다. 논문에서 제시한 기간보다 적은 횟수로 학습하였기 때문에 더 성능을 높일 여지가 있습니다.
결론
앙상블 DQN은 DQN에 Bootstrapping을 적용한 모델입니다. DQN은 학습이 더디고 학습이 불안정하다는 단점을 갖고 있습니다. 앙상블 모델을 이용하여 학습할 경우 DQN보다 안정적이게 학습할 수 있기 때문에 유용하다고 생각 됩니다. 하지만 여전히 성능 향상이 불안정하고 지속적으로 상승하지 않는 현상을 보이고 있습니다. 튜토리얼에서는 DQN의 학습 효율을 올릴 수 있는 여러가지 테크닉(Dueling DQN, Double DQN)을 사용하지 않았기 때문에 해당 테크닉을 적용시 어느정도 불안정한 학습 형태가 변할 가능성이 있습니다. 해당 방법을 적용하면 더 안전하게 학습이 가능하다는 것이 실험적으로 증명되었으므로 관심이 있으신 분들은 LINK 를 확인하시기 바랍니다.
[Bootstrapped DQN] 에서 튜토리얼에서 구현한 전체 파일을 제공하고 있습니다. 해당 Github를 방문하시어 구현물 전체 모습을 확인바랍니다.
Reference
- [PAPER] Deep Exploration via Bootstrapped DQN, Osband at el, NIPS 2016
- [PAPER] Playing Atari with Deep Reinforcement Learning, Osband at el
- [BLOG] 강화학습 알아보기(DQN)
- [GITHUB] Bootstrap DQN(Pytorch Implementation)