[논문리뷰] - WaveNet : A Generative Model for Raw Audio, DeepMind
딥러닝 기반 음성합성방법이 등장하기 전까지는 아래와 같은 2가지 대표적인 방식을 주로 채택하여 음성을 생성하거나 합성하였습니다.
- Concatenative TTS 방식 : 다량의 음성데이터를 음소로 분리하고 조합하여 새로운 음성을 생성하는 방식
- Parametric TTS 방식 : 통계적 모델(은닉 마르코프 모델)을 기반으로 음성을 합성하는 방식
하지만 위 방법으로부터 생성된 음성은 실제 사람의 음성만큼 매끄럽지 않으며 음편사이의 경계가 부자연스러운 문제들이 있습니다.
2016년 딥마인드(DeepMind) 에서 딥러닝 기반 음성 생성모델에 관한 논문을 공개하였습니다.
오늘은 이 딥러닝 기반 End-to-End 음성 생성 모델인 WaveNet 을 포스팅하겠습니다.
이 글은 WaveNet 논문 과 Medium 글 을 참고하여 정리하였음을 먼저 밝힙니다.
또한 논문을 이해하기 위하여 필요한 내용을 외부 코드 및 글을 정리하여 추가하였으므로 포스팅한 글은 논문의 내용만을 담고 있지 않습니다.
제가 잘못 알고 있는 점이나 보안할 점이 있다면 댓글 부탁드립니다.
Short Summary
이 논문의 큰 특징 4가지는 아래와 같습니다.
- WaveNet은 자연스러운 음성 파형을 직접 생성합니다.
- 긴 음성 파형을 학습하고 생성할 수 있는 새로운 구조를 제시합니다.
- 학습된 모델은 컨디션 모델링으로 인해 다양한 특징적인 음성을 생성할 수 있습니다.
- 음악을 포함한 다양한 음성 생성분야에서도 좋은 성능을 보입니다.
모델 구조
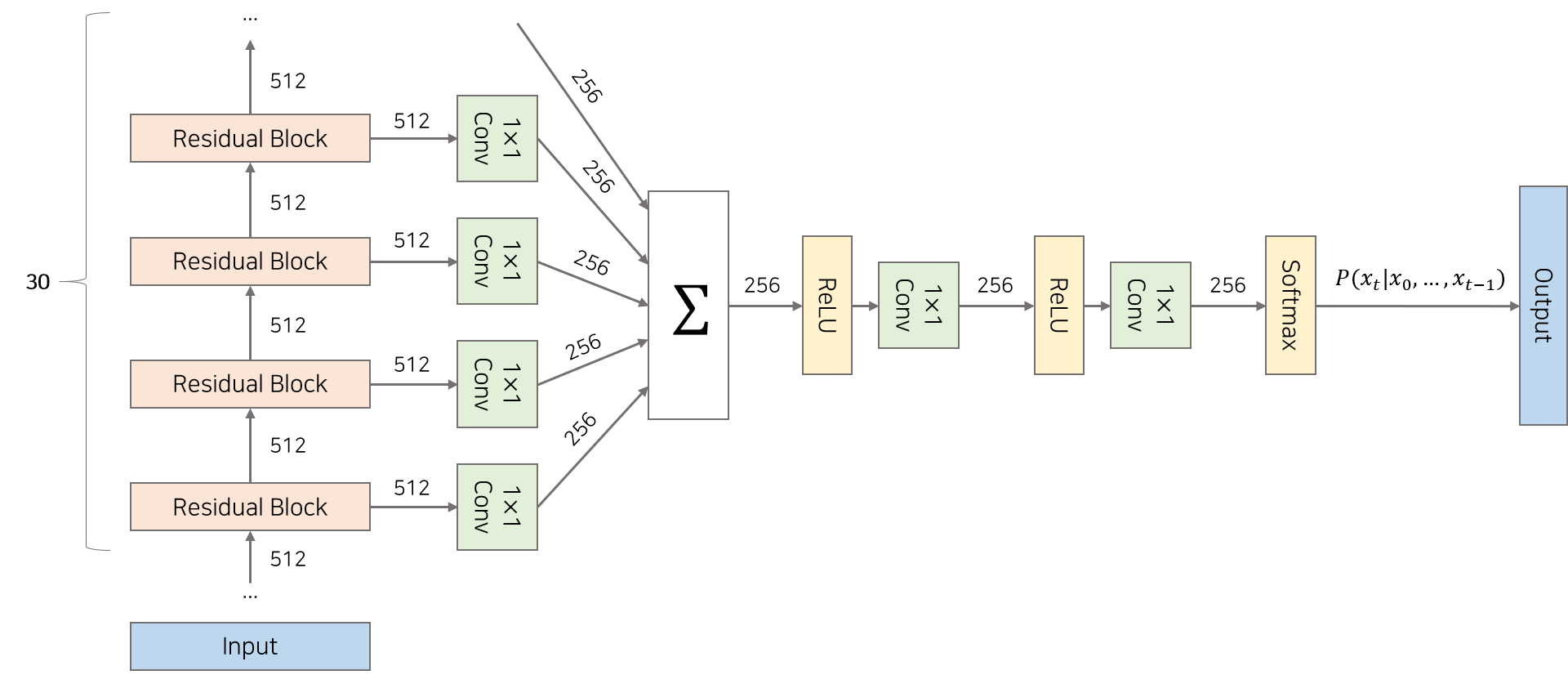
WaveNet은 30개의 Residaul Block을 쌓은 형태의 구조를 갖고 있습니다. 정수 배열을 Input으로 받아 첫번째 Residaul Block부터 30번째 Residual Block까지 차례대로 들어갑니다. 각각의 Residual Block으로부터 생성된 Output은 Skip Connection을 통해 합쳐지고 이를 모델의 Output으로 활용합니다.
1) Modeling
WaveNet은 확률론적 모형(Probabilistic Model)으로써 T개의 배열로 구성된 음성 데이터 $x_1, …, x_{T-1} ,x_{T}$ 열이 주어졌을 때 음성으로써 성립할 확률 $P(x_1, …, x_{T-1} ,x_{T})$ 을 학습하여 이후 생성에 활용합니다. 이 확률은 각 음성 데이터들의 조건부 확률을 이용하여 아래와 같이 표현될수 있습니다.
위 조건부확률을 따르는 모델은 $t$ 시점을 기준으로 과거의 음성 데이터 $x_1, …, x_{t-1} ,x_{t}$ 을 이용하여 한 시점 뒤 음성 데이터 $x_{t+1}$가 나올 확률을 나타낼 수 있으므로 그 확률을 이용하여 음성을 생성할 수 있습니다.
[참고문서]
2) Input & Output
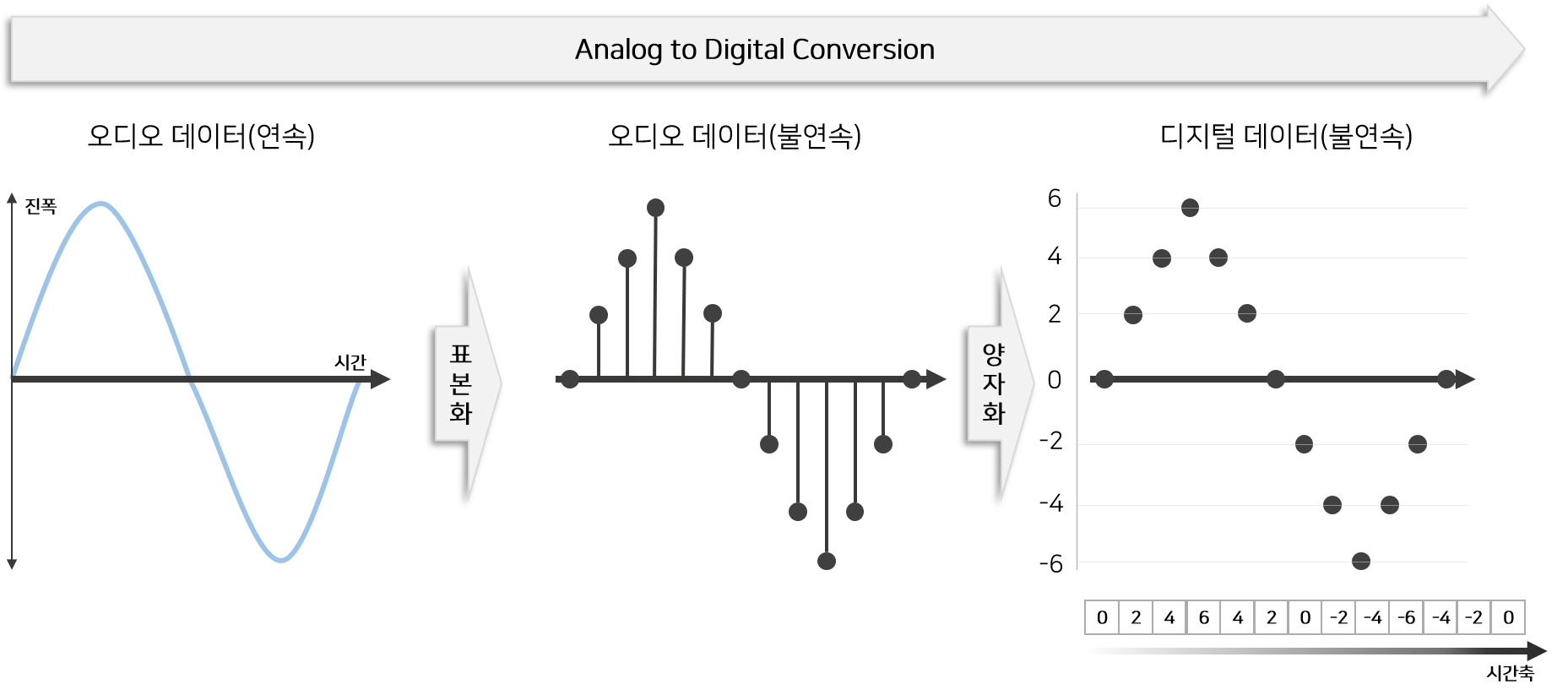
아날로그 음성 데이터는 연속형(Continous) 데이터입니다. 이 음성 데이터를 컴퓨터에서 처리하거나 저장(.wav, .mp4)하려면 디지털 데이터로 변환해야 합니다.
이 변환하는 과정을 Analog Digital Conversion 라고 부르며 표본화(Sampling), 양자화(Quantizing)로 구성되어 있습니다.
Analog Digital Conversion 과정을 통해 처리된 음성 데이터는 이산형(Discrete) 디지털 데이터로 변환되어 정수배열(Integer Array)로 표현됩니다.
이 정수배열이 WaveNet의 Input과 Output으로 활용됩니다.
[참고문서]
3) SoftMax Distribution
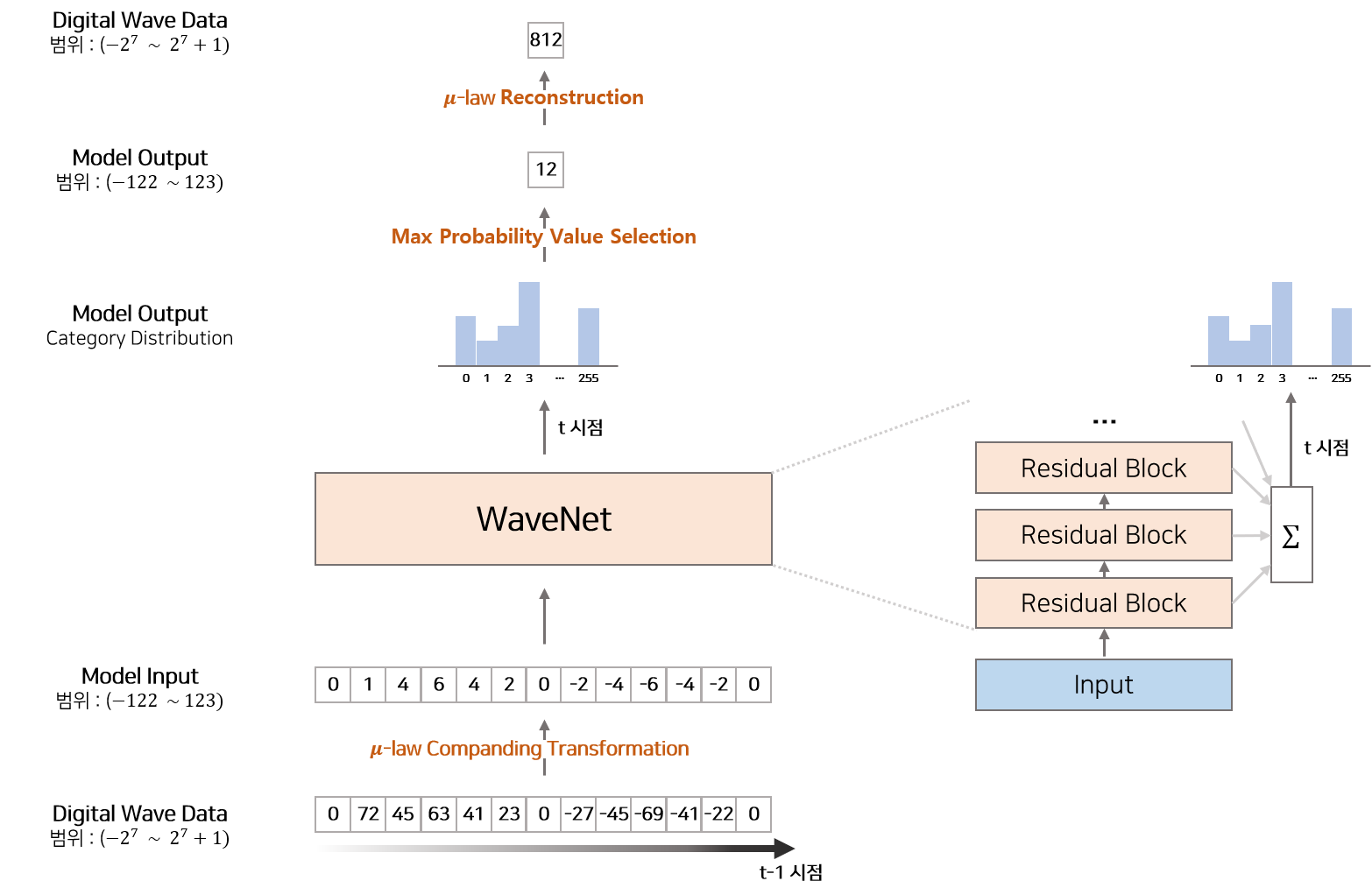
일반적인 음성 데이터는 각 샘플을 16(bit) 정수 값으로 저장하므로 앞서 설명한 Anlog Digital Conversion을 통해 생성된 정수배열의 정수는 $-2^{15}$ ~ $2^{15}+1$ 사이의 숫자입니다. WaveNet은 확률론적 모델링에 따라 매 $t$ 시점 특정 파형이 나올 확률 $P(x_t|x_1, …, x_t−1)$ 을 계산하는데 이 확률을 범주형 분포(Categorical Distribution)로 가정하면 매 $t$ 시점 $-2^{15}$ ~ $2^{15}+1$ 사이의 숫자가 나올 확률 $P(-2^{15}|x_1, …, x_t−1), …, P(2^{15}+1|x_1, …, x_t−1)$ 을 계산해야 합니다. 각 숫자가 나올 확률(총 65,536 개의 확률)을 다루는 것은 매우 어려우므로 WaveNet에서는 이를 256개의 숫자(총 256 개의 확률)로 변환하는 $\mu$-law Companding 이라는 변환방법을 사용합니다. 논문에서는 $\mu$-law Companding와 같은 비선형적인 변환방식이 선형적인 변형방식보다 더 효과적이라고 기술하고 있습니다.
$\mu$-law Companding Transformation
결론적으로 WaveNet 모델에서 Input으로 사용하는 것은 $\mu$-law Companding 변환방법을 이용하여 음성 디지털 데이터를 작은 범위의 정수 배열로 변환한 값입니다. WaveNet 모델로부터 추출된 Output 역시 -127~128(256개) 범위의 정수이며, 이 정수를 Reconstruction을 통해 다시 음성 디지털 데이터로 변형한 것이 최종 결과물입니다.
4) Dilated Causal Convolutions
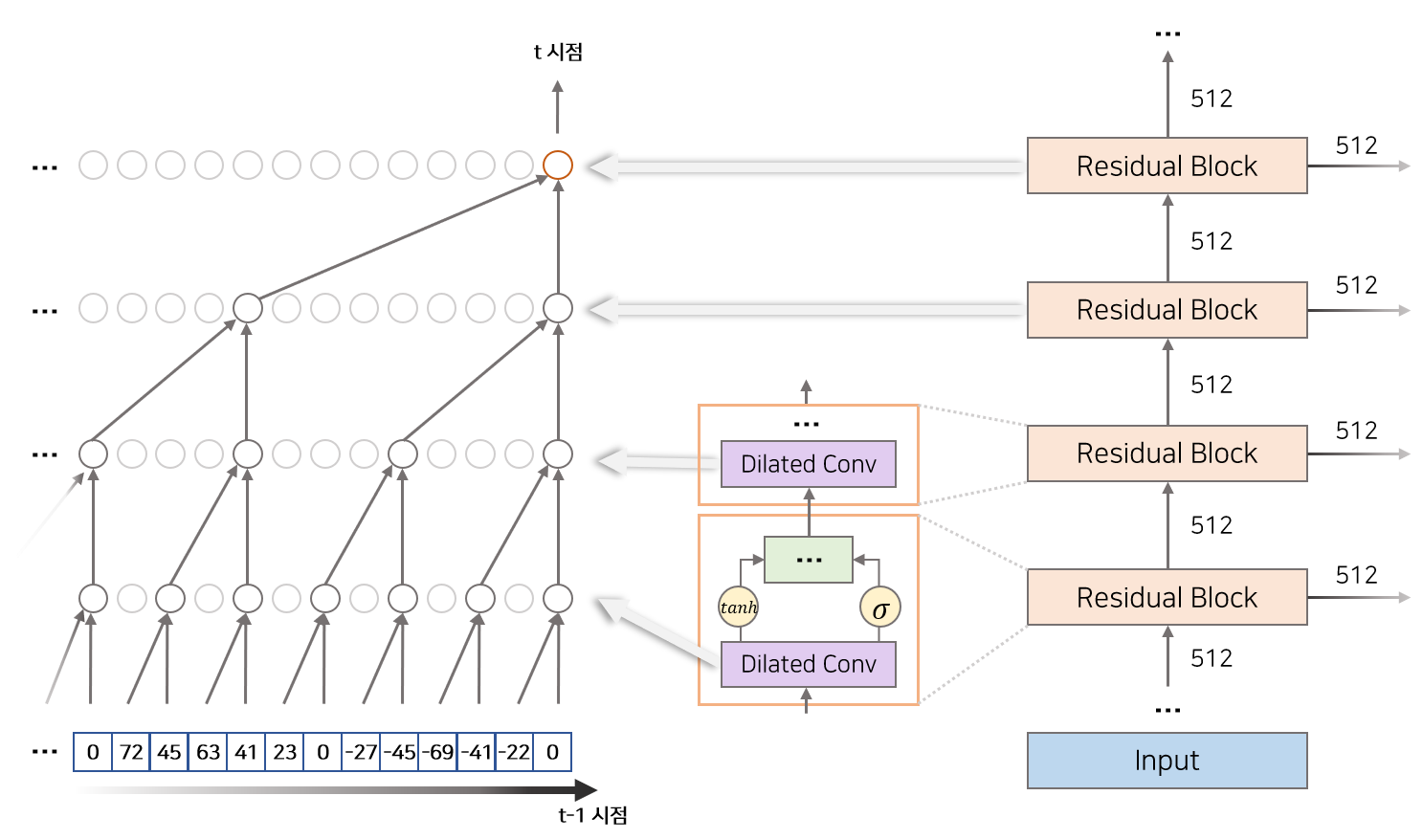
모델의 Residual Block은 몇가지 Activation Function과 Neural Layer로 구성되어 있습니다. 이 중에서 과거 음성 정보에 접근하는 구조를 갖는 Layer는 Dilated Causal Convolutions Layer 입니다. 입력의 범위를 중점으로 상세하게 묘사하면 Figure 4의 왼쪽과 같습니다.
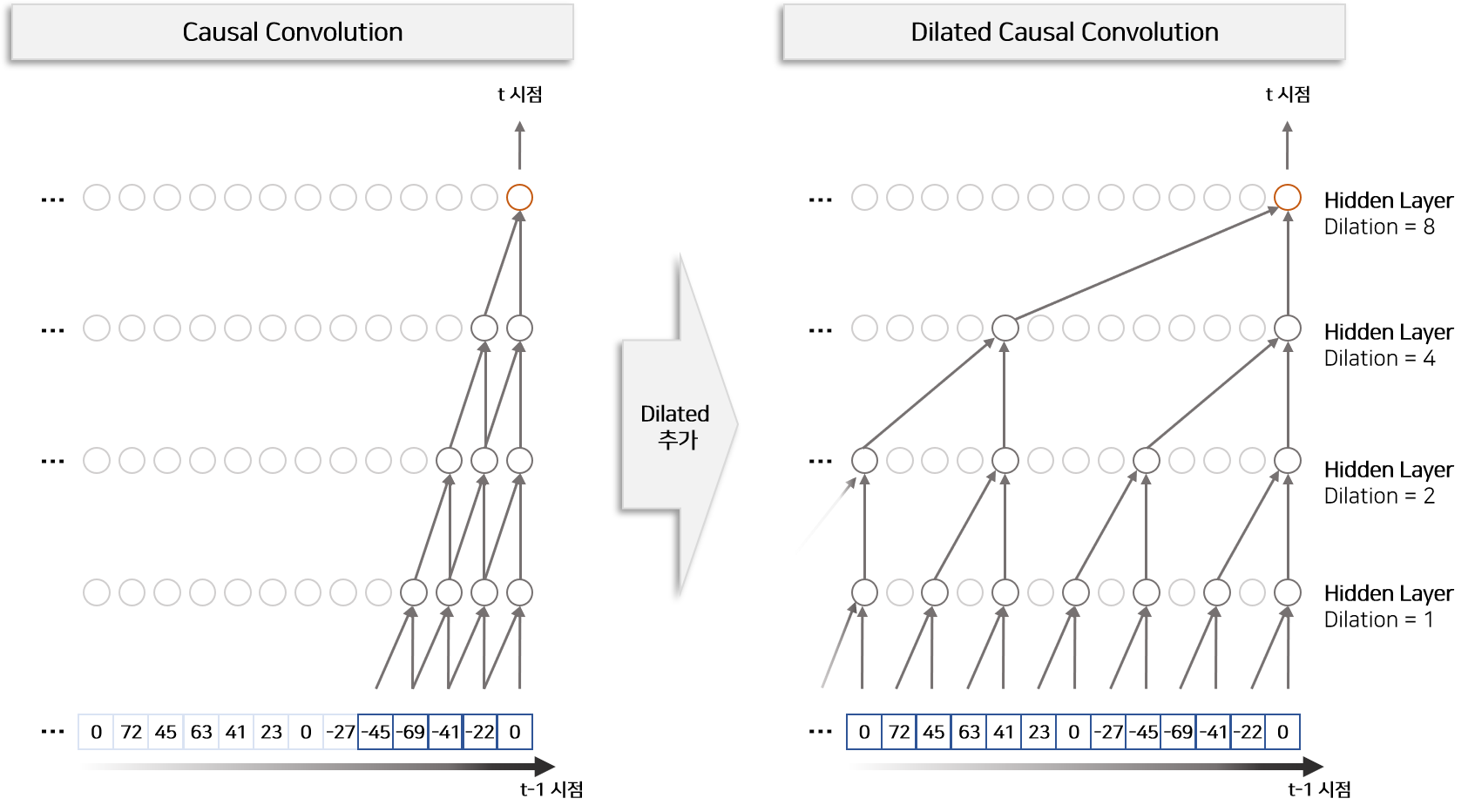
Dilated Causal Convolutions Layer 은 Dilated Convolution Layer의 기능과 Causal Convolutions Layer의 기능을 합쳐놓은 Convolution Layer입니다.
Causal Convolution이란 시간 순서를 고려하여 Convolution Filter를 적용하는 변형 Convolution Layer입니다. Causal Convolution을 위로 쌓을 수록 Input 데이터의 수용 범위(Receptive Field)가 커지므로 RNN 계열의 모델처럼 음성 데이터(시계열 데이터)를 모델링 할 수 있습니다. 다만 Causal Convolution만을 이용하면 수용 범위를 넓히기 위해서 많은 양의 Layer를 쌓아야 하는 단점이 존재합니다. 이를 해결하기 위하여 Dilated Convolution을 함께 적용합니다.
Dilated Convolution이란 추출 간격(Dilation)을 조절하여 더 넓은 수용 범위를 갖게 하는 변형 Convolution Layer입니다. 즉 추출 간격을 조절하는 Dilated Causal Convolutions을 적용하면 적게 Layer를 쌓아도 넓은 수용 범위를 갖을 수 있는 장점을 갖고 있습니다. Figure 5처럼 Layer를 쌓을 때 추출 간격을 차례대로 1, 2, 4, …, 512 까지 늘리면 모델의 Input 수용범위(Receptive Field)는 1024 입니다.
WaveNet 논문에서는 추출간격을 일정 수준(512)까지 늘리는 것을 반복하여 (1, 2, 4, …, 512, 1, 2, 4, …, 512, …) 총 30층의 Layer를 쌓아 모델을 구성합니다. Figure 6은 DeepMind 에서 Dilated Causal Convolutions과 수용범위(Receptive Field)를 설명하기 위하여 만든 에니메이션 입니다.

5) Residual Connection & Gated Activation Units
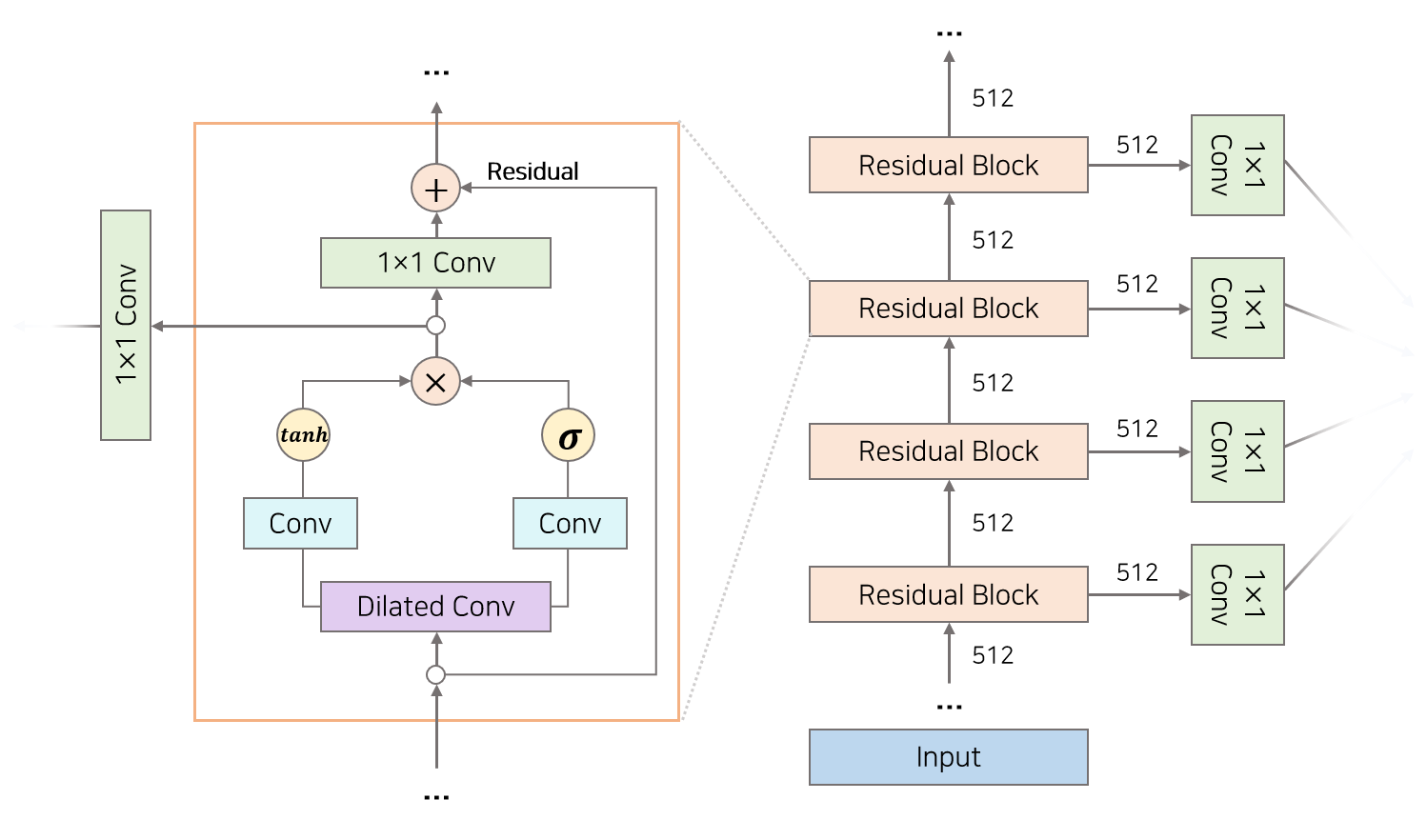
Residaul Block은 앞서 설명한 Dilated Convolution Layer와 두개의 Activation Function($tanh, \sigma$), 두개의 일반적인 Convolution Layer, 1$\times$1 Convolution Layer 으로 구성되어 있습니다. Dilated Convolution 통해 생성된 벡터는 두개의 경로를 통해 계산되는데 Convolution Layer와 $tanh$ 경로를 필터(Filter)라고 부르고, Convolution Layer와 $\sigma$ 경로를 게이트(Gate)라고 명칭합니다. 각각 경로를 통해 계산된 벡터는 다시 $Element-Wise$ 곱을 통해 하나의 벡터로 변환되는데 이 방식을 Gated Activation Units이라고 합니다.
Gated Activation Units
$* : Convolution 연산$
$\odot : Element-wise 곱셈$
$\sigma() : Sigmoid Function$
$W : 학습 가능한 Convolution Filter$
$f : filter \ g : gate \ k : layer 번호$
Autoregressive Model 중 하나인 참조논문(PixelCNN) 에서 고안한 방식으로 특정 Layer에서 생성한 지역적 특징(Local Feature)을 필터(Filter)로 보고 이 필터의 정보를 다음 Layer에 얼만큼 전달해 줄지를 정해주는 수도꼭지의 역할을 하는 것이 게이트(Gate)의 기능입니다.
Gated Activation Unit을 통해 생성된 벡터 $z$는 1$\times$1 Convolution Layer 지나 Reisidual Connection으로 해당 Layer Input과 합쳐져 Layer Output이 됩니다. 이러한 Residaul Connection 구조는 딥러닝 모델을 더 깊게 쌓게 할 뿐만 아니라 빠르게 학습할 수 있도록 돕는 역할을 합니다.
6) Skip Connection
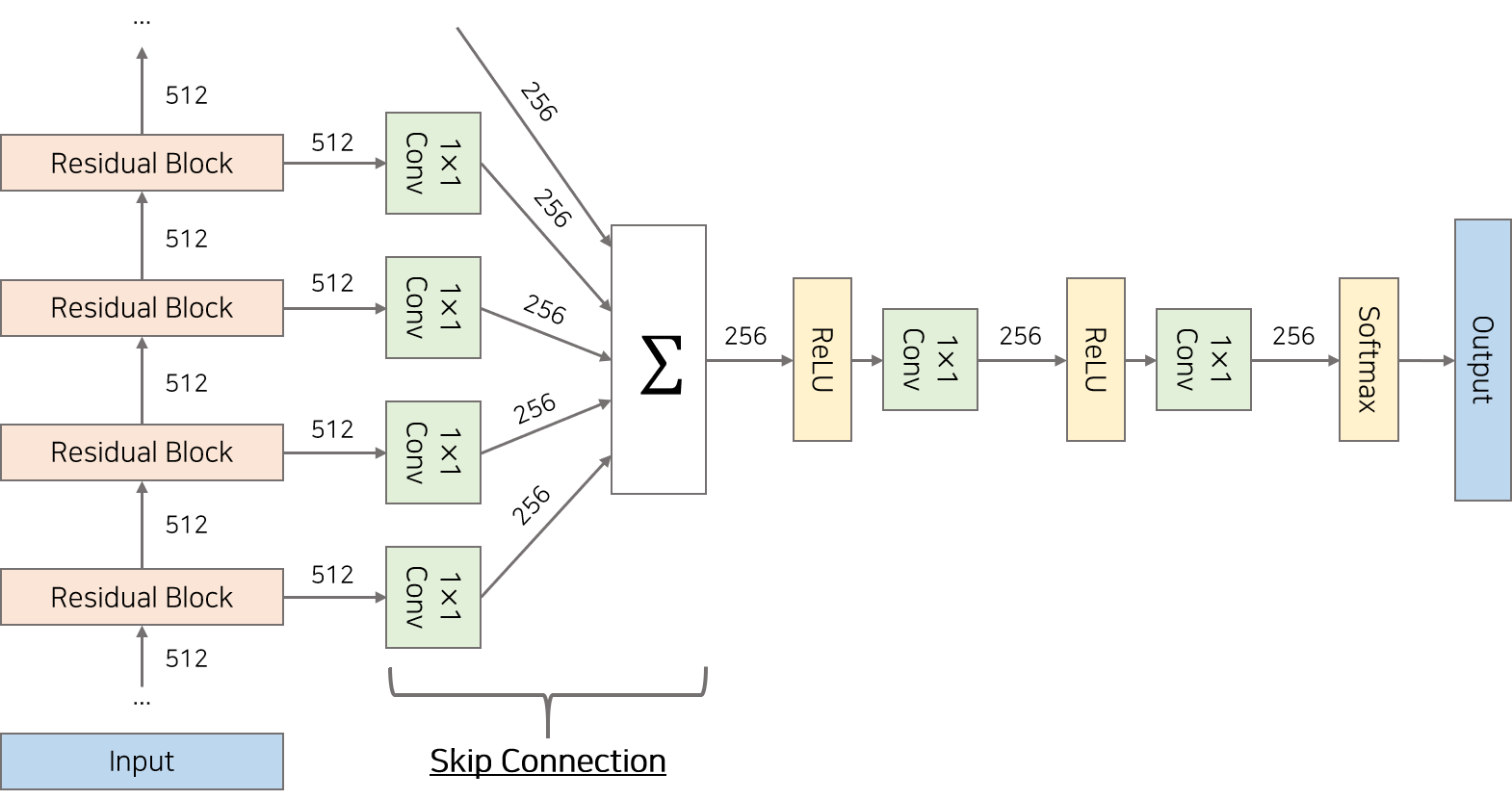
Skip Connection은 각 Residual Block Layer에서 생성된 Layer Output을 1$\times$1 Convolution Layer 통과시킨 후 합하는 과정으로 구현됩니다. 각 Residual Block Layer에서 생성된 Output은 layer Depth에 따라 서로 다른 수용범위(Receptive Field)를 이용하여 Local Output을 생성하므로 이 정보를 모두 더하여 최종 모델의 Output을 생성합니다.
7) Conditional WaveNets
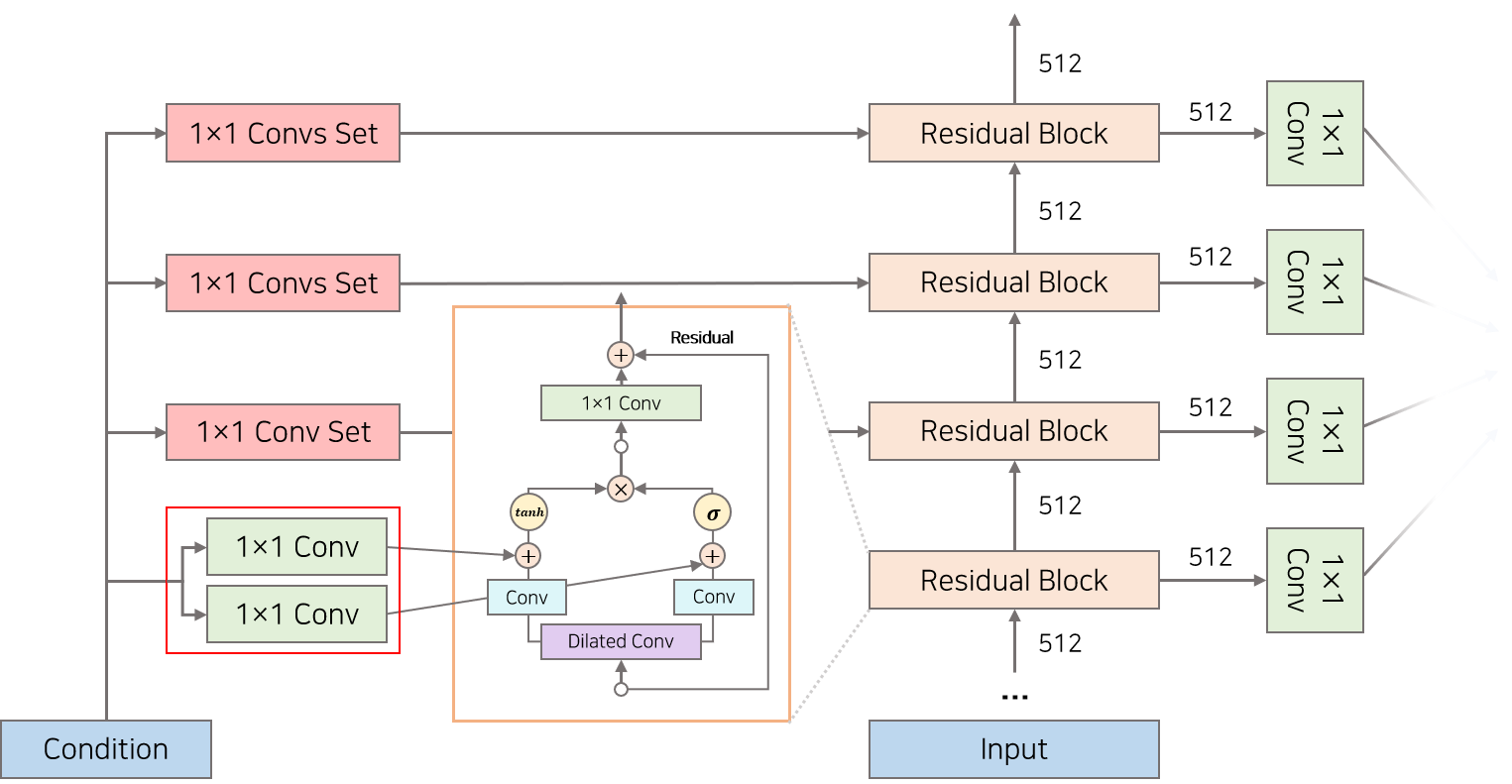
WaveNet은 Conditional Modeling $P(x|h)$ 이 가능합니다. 즉 WaveNet에 특징($h$)을 추가하여 특징에 맞는 음성을 생성할 수 있습니다. 예를 들어 TTS(Text to Speech)인 경우 Text Embedding을 조건정보로 추가하여 모델을 학습시킴으로써 Generation 단계에서 Text Embedding를 Input으로 넣으면 관련 Text에 맞는 음성을 생성합니다. 다른 예로써 Vocoder인 경우 스펙트로그램을 Wavenet의 조건정보로 추가하여 모델을 학습시킴으로써 Generation 단계에서 스펙트로그램을에 맞는 음성을 생성할 수 있습니다.
Conditional Modeling 하는 방법에는 2가지 형태가 있습니다.
- 전역적 조건(Global Conditioning) : 시점에 따라 변하지 않는 조건 정보를 추가하는 방법.
- 지역적 조건(Local Conditioning) : 시점에 따라 변하는 조건 정보를 추가하는 방법.
전역적 조건(Global Conditioning) 수식
모델로부터 여러 화자의 음성을 생성하고 싶을 때에는 조건으로 화자의 정보 $h$를 추가하여 음성과 함께 학습합니다. 이 정보는 화자 고유의 특성이므로 시점별로 변하는 정보가 아닙니다. 따라서 전역적 조건정보 $h$를 모든 시점에 동일하게 추가하여 모델의 학습 및 생성에 영향을 주어야합니다. 논문에서는 위 수식을 통해 모든 시점에서 동일하게 조건정보를 추가하였습니다. 수식에서 $h$는 조건에 해당하는 벡터를 의미하고, $V^T_{f,k}, V^T_{g,k}$ 는 각 선형함수를 의미합니다. 벡터 곱으로 생성된 $V^T_{f,k}h, V^T_{g,k}h$은 필터와 게이트 부분에 추가되어 모든 시점에 영향을 주는 장치로써 작동합니다.
지역적 조건(Local Conditioning) 수식
TTS(Text to Speech)인 경우 Linguistic Feature 또는 Text Embedding 과 같은 정보를 조건으로 추가하여 음성을 생성합니다.
이 정보는 음성과 길이는 다르지만 순서가 있는 일정 길이의 Sequence 벡터 입니다.
따라서 이 조건 정보를 음성의 정보와 매칭시켜 시점에 따라 다르게 넣어주어야 합니다.
예를들자면 ‘나는 사과를 좋아한다’라는 TEXT를 조건 정보로 추가할 때 음성에서 ‘사과’라는 소리가 나오는 시점에 ‘사과’ 단어의 Embedding 이 영향을 주도록 음성과 조건정보의 시점을 매칭시켜야 합니다.
해당 정보를 담고 있는 음성의 위치와 정확하게 매핑시키는 것은 어렵지만 조건정보를 일률적으로 증가시키는 방식으로 음성의 길이와 조건의 길이를 일치 시킬 수 있습니다.
따라서 논문에서는 Transposed Convolution 또는 간단한 복제를 통해서 길이를 증가시킨 후 모델의 조건 정보로 활용합니다.
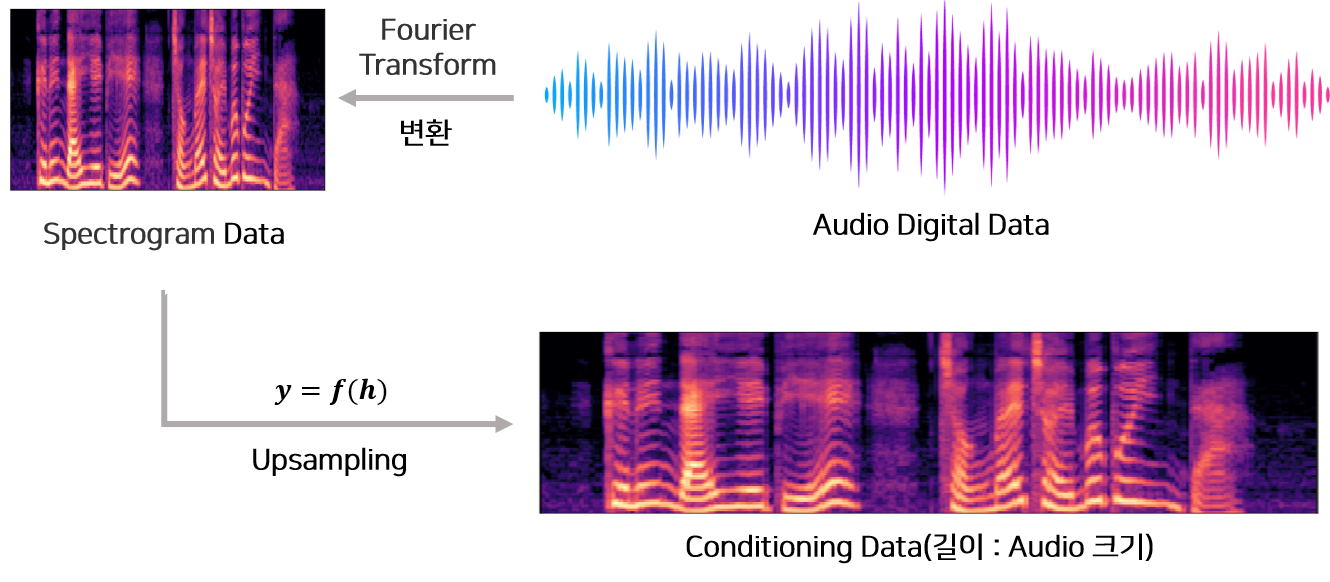
Figure 10은 조건 정보의 길이를 증가시키는 방법(Usampling)의 예시입니다.
길이를 맞추는 함수를 통해 생성된 조건 정보 $y=f(h)$는 1x1 Convolution 함수 $V_{f,k}, V_{g,k}$를 통과한 후 필터와 게이트에 추가되어 각 시점에 영향을 주는 장치로써 작동합니다.
실험 및 결과
1) Multi-Speaker Speech Generation
VCTK Dataset(English multi-speaker corpus) 을 이용하여 다양한 화자의 ID를 조건으로 추가하여 WaveNet 모델로부터 각 화자의 특징을 포함한 음성을 생성할 수 있는지를 테스트 합니다. 화자의 ID를 One-Hot Vector로 변환한 후 학습 시 조건정보로 추가합니다. 학습된 WaveNet은 각 화자에 맞는 음성을 생성할 수 있음을 보여주었습니다.
2) Text to Speech
WaveNet을 이용하여 TTS(Text to Speech)를 하기 위해서 추가하는 조건정보는 음소, 음소 길이, 기본 주파수 $F_0$ 등이 있습니다.
즉 합습 시 이 정보들을 추가하여 학습한 후 생성할 때에는 조건 정보만을 이용하여 음성을 생성합니다.
문장으로부터 음소와 음소길이 기본주파수를 추출하는 방식에 대해서 논문에서 언급하지 않습니다.
다만 외부 모델로 부터 학습하이 관련 정보를 추출하고 이 조건정보를 WaveNet의 입력으로 활용한다고 기술합니다.
아마도 추가적인 음성모델링을 통해 이런 기본정보를 추출하는 것으로 추측합니다.
TTS(Text to Speech) Task에서 WaveNet의 성능을 평가하기 위하여 HMM(Hidden Markov Model), LSTM-RNN Model을 비교 모델로 준비합니다.
WaveNet(L)은 Linguistic Features(음소, 음소 길이) 조건정보로 추가하여 학습한 모델이고, WaveNet(L+F)는 Linguistic Features 뿐만 아니라 기본주파수에 log Scale을 한 $log F_0$ 를 추가하여 학습한 모델입니다.
총 2가지 방법으로 모델의 성능을 평가합니다.
- Paired Comparison Test : 피실험자에게 두 개의 실험모델로부터 생성된 음성을 들려주고 그 중 더 좋은 음성을 선택하는 실험.
- Mean Opinion Score(MOS) Test : 피실험자에게 실험모델로부터 생성된 음성을 들려주고 1~5점의 품질 점수를 선택하도록 하는 실험.
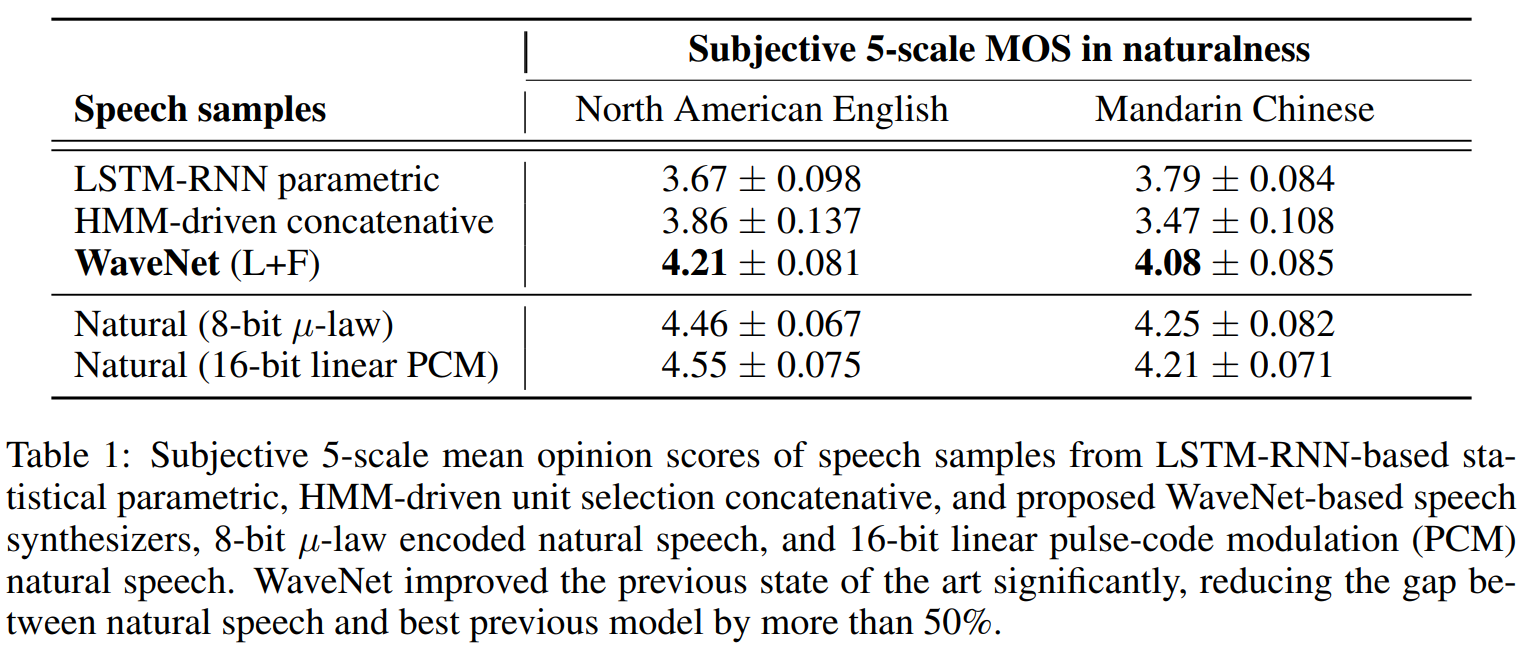
MOS Test에서 압도적으로 WaveNet에서 생성된 음성이 가장 높은 점수를 획득하였습니다. 실제 음성의 데이터와도 큰 차이가 나지 않는 점수인걸 확인 할 수 있습니다.
결론(개인적인 생각)
음성합성을 위하여 처음으로 본 논문이기 때문에 논문에서 자세하게 다루지 않는 내용을 이해하기 위하여 다양한 외부 정보를 추가하여 리뷰하였습니다. 딥러닝 모델 구조와 그 작동원리는 논문에서 자세하게 설명하기 때문에 이해하기 쉬웠지만 TTS를 만들기 위하여 문장으로부터 음소, 음소길이, 기본 주파수를 추출하는 방법은 자세하게 기술하지 않았으므로 TTS 구현체를 만드는 것은 다소 어려워보입니다. 다행히 MEDIUM BLOG 에서 WaveNet 구현체와 실험방법에 대해 자세히 설명하였기 때문에 이점을 참고하면 좋을 것 같습니다.
WaveNet 논문에서는 음소정보와 기본주파수를 조건정보로 모델에 추가하여 TTS에 적용한 사례를 보여줍니다. 최근 논문에서는 WaveNet을 주로 Vocoder로 활용하고 있습니다. 즉 타코트론과 같은 모델을 이용하여 텍스트로부터 스펙토그램을 추출하고 이를 WaveNet에 넣어 음성을 합성하는 방식으로 활용합니다. 연세대학교 석박통합과정 황민제님의 발표영상 에서도 WaveNet을 Vocoder로 활용할 경우 더 빠르게 학습이 가능하며 음성의 품질을 향상시킬 수 있다고 언급합니다.
Reference
- [BLOG] Understanding WaveNet architecture, Satyam Kumar
- [BLOG] WaveNet 이란?, JG Ahn
- [BLOG] DeepMind WaveNet Review
- [BLOG] 오디오 데이터 전처리, Hyunlee103
- [BLOG] 파이썬 librosa 패키지로 스펙트럼 그리기, HanSeokhyeon
- [BLOG] 1x1 Convolution 이란, Hwiyong Jo
- [BLOG] ResNet 설명 및 정리, Lee Ganghee
- [BLOG] WaveNet Implementation and Experiments, Evin Pınar Örnek
- [PAPER] 한국어 text-to-speech(TTS) 시스템을 위한 엔드투엔드 합성 방식 연구, 최연주
- [YOUTUBE] A Generative Model for Raw Audio, 모두의연구소
- [YOUTUBE] Generative Model-Based Text-to-Speech Synthesis, Heiga Zen
- [YOUTUBE] Generative Model-Based Text-to-Speech Synthesis, Heiga Zen
- [GITHUB] pytorch-wavenet, vincentherrmann
- [BLOG] 활용사례
- [BLOG] AI에게 어떻게 음성을 가르칠까?, Tech Log