[논문리뷰] - TACOTRON : Towards End-to-End Speech Synthesis, DeepMind
TTS(Text to Speech)는 매우 복잡하며 긴 작업절차가 필요한 어려운 문제입니다. 그 이유는 문장으로부터 음성을 생성하기 위하여 ‘문장을 음소로 나누고, 음소의 발음을 찾고, 음소와 음성의 위치를 매핑하는 등…’ 다양한 작업이 필요하기 때문입니다. 또한 각 작업은 난이도가 높아 전문가의 지식이 필요하고 작업이 분리되어 따로 설계되므로 이들을 합쳤을 때 발생하는 품질저하 사유를 찾는 것은 매우 어렵습니다.
하지만 드디어 이러한 복잡한 문제를 극복한 End-to-End 모델인 타코트론 논문이 공개되었습니다. 이 타코트론 모델은 문장으로부터 음성을 생성하기 위하여 별도의 작업 없이 <문장, 음성> 쌍으로 이루어진 데이터가 있으면 학습이 가능하다는 특징을 갖고 있습니다. 따라서 이 논문이 나온 이후로 이제는 전문가의 도움 없이도 개인이 음성을 합성할 수 있게 되었습니다.
오늘 포스팅은 타코트론 또는 Tacotron라고 불리는 End-to-End 모델 대해 상세하게 리뷰하도록 하겠습니다.
이 글은 Tacotron 논문과 Tacotron을 한국어에 적용한 논문 을 참고하여 정리하였음을 먼저 밝힙니다.
논문 그대로를 리뷰하기보다는 생각을 정리하는 목적으로 제작하고 있기 때문에 실제 내용과 다른점이 존재할 수 있습니다.
혹시 제가 잘못 알고 있는 점이나 보안할 점이 있다면 댓글 부탁드립니다.
Short Summary
이 논문의 큰 특징 3가지는 아래와 같습니다.
- Attention 기반 Seq-to-Seq TTS 모델 구조를 제시합니다.
- <문장, 음성> 쌍으로 이루어진 데이터만으로 별도의 작업없이 학습이 가능한 End-to-End 모델입니다.
- 음성합성 품질 테스트(MOS)에서 높은 점수를 획득하였습니다. 합성품질이 뛰어납니다.
모델 구조
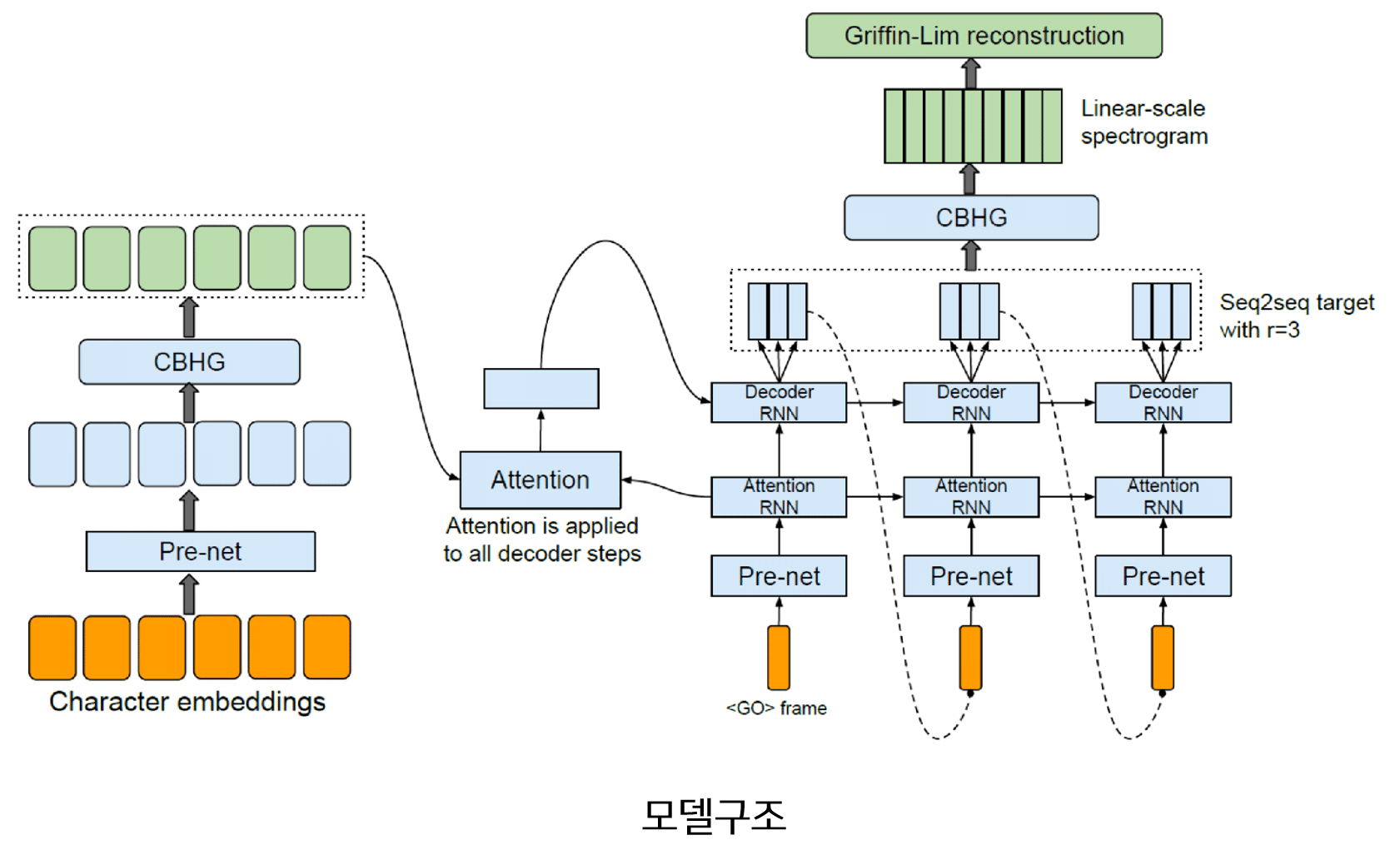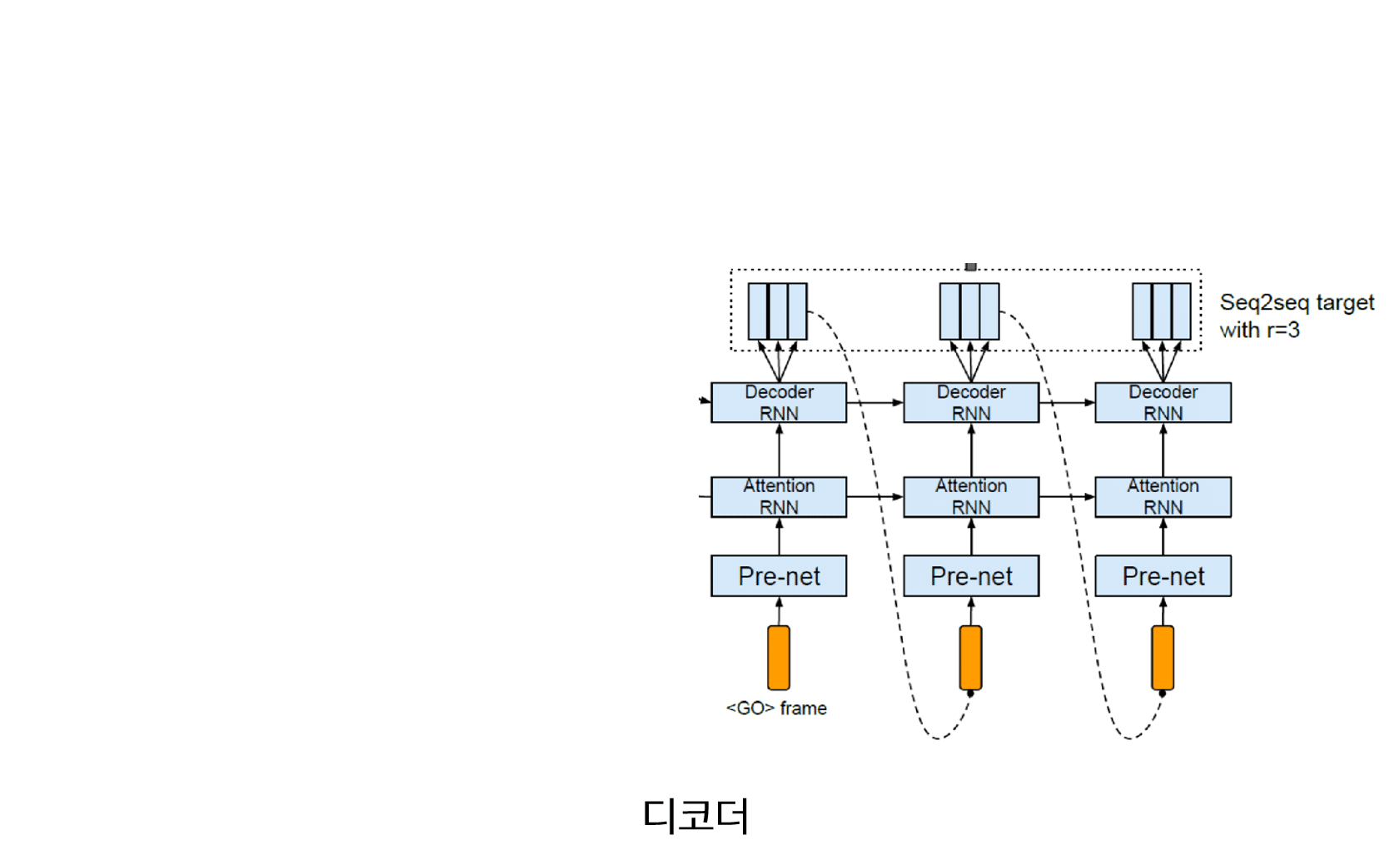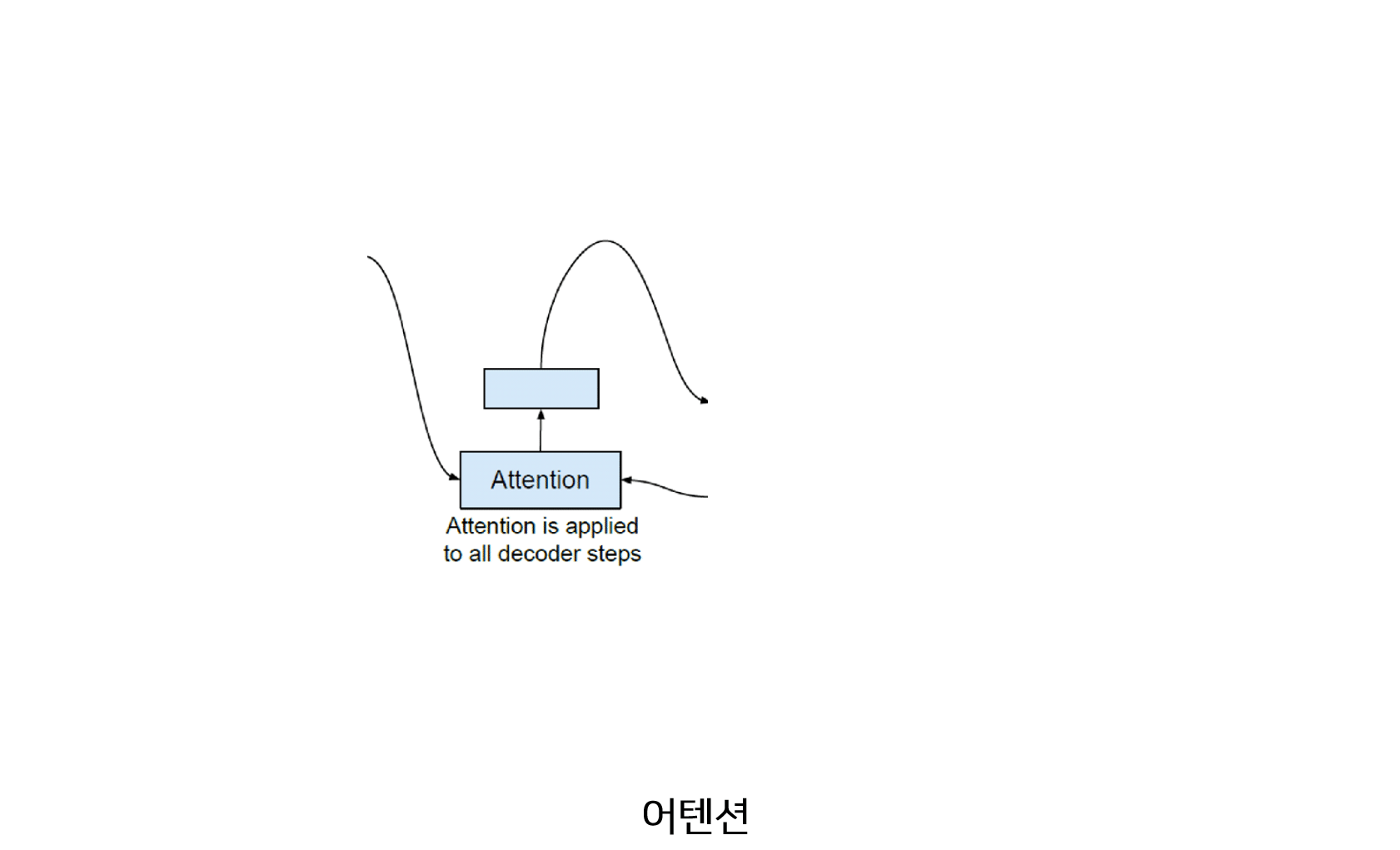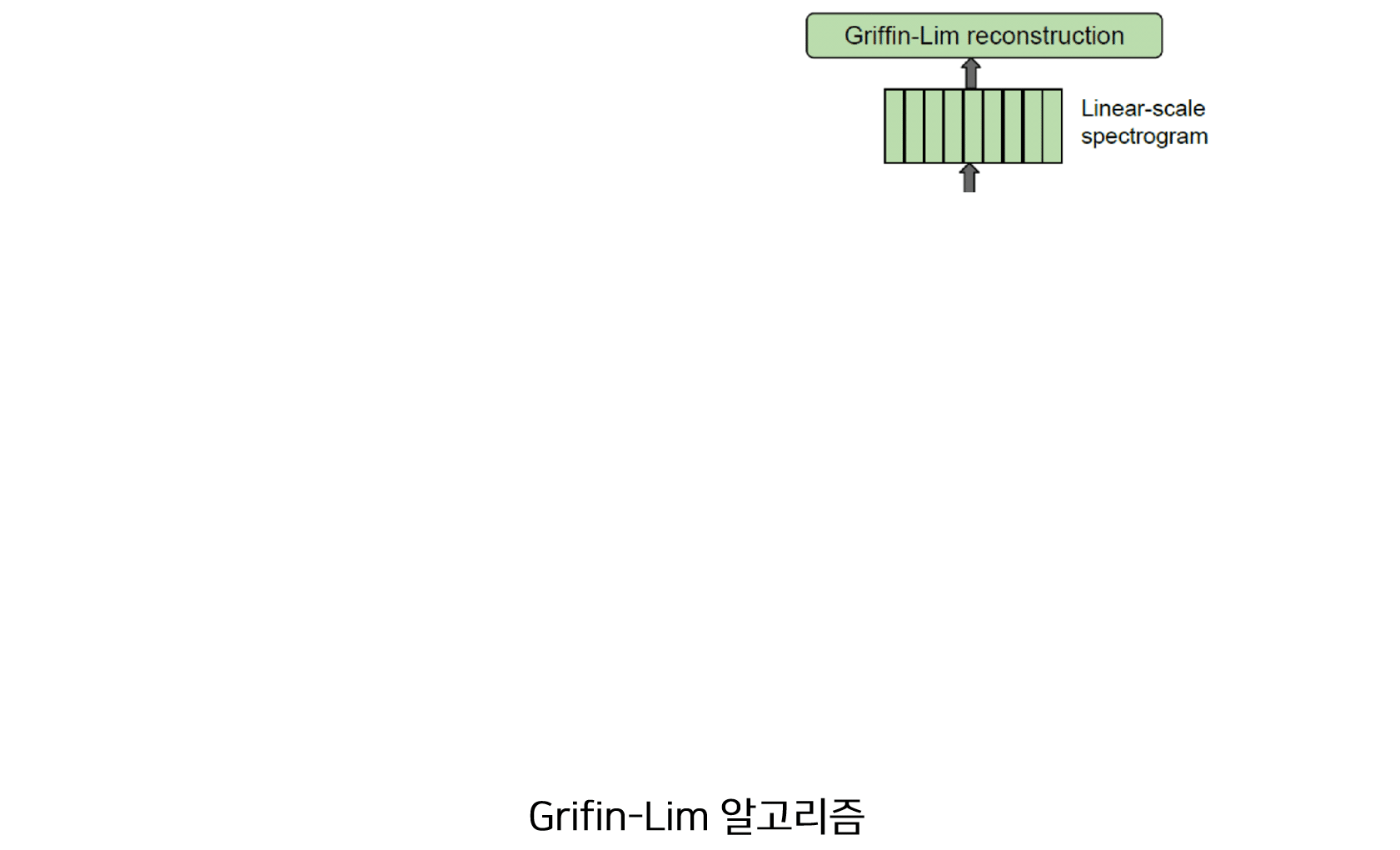
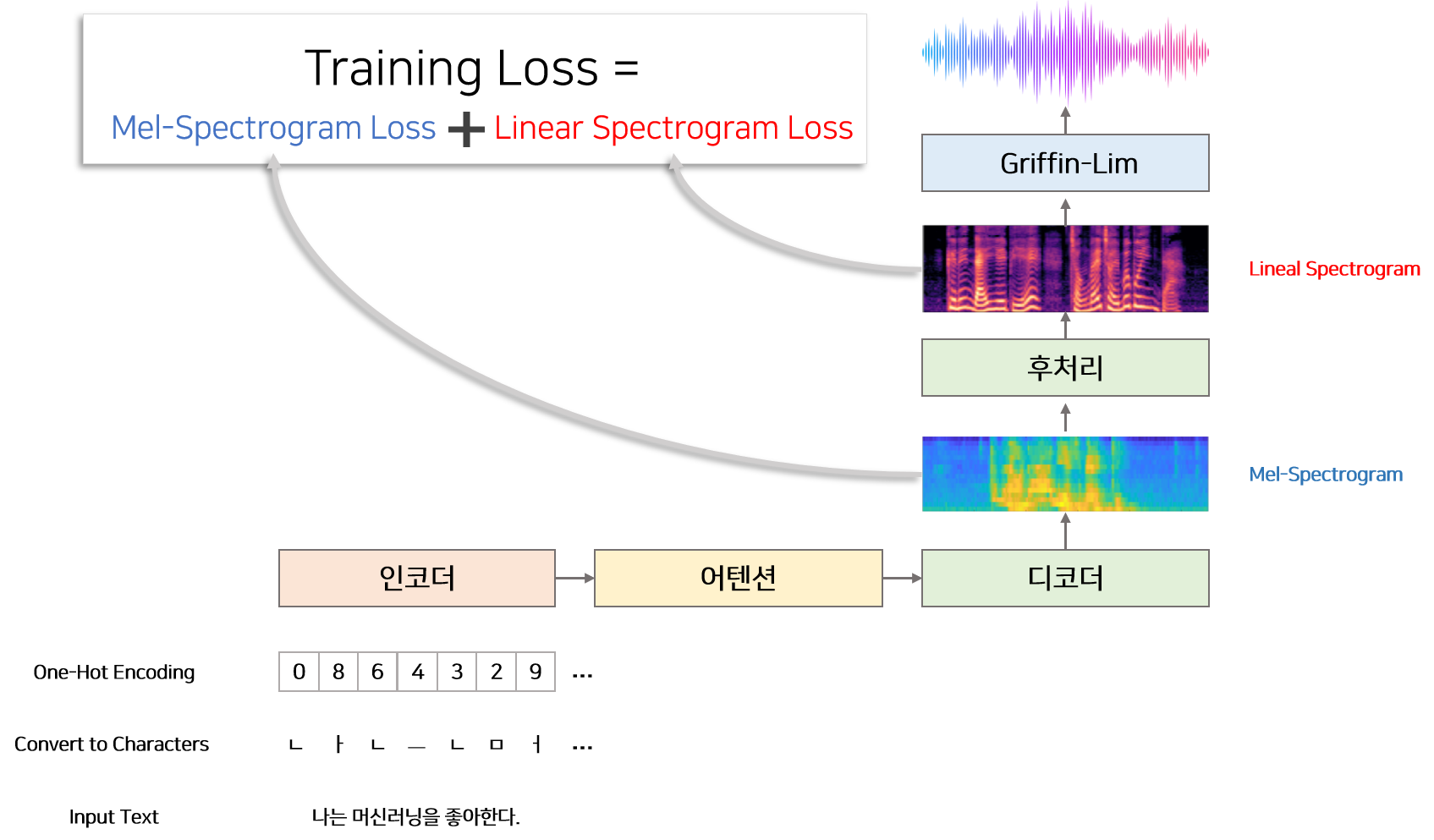
모델은 크게 문장을 Input으로 받아 정보를 추출하는 인코더, 인코더로부터 추출된 정보를 이용하여 멜 스펙토그램을 생성하는 디코더, 인코더의 정보를 디코더에 매핑해주는 어텐션, 마지막으로 디코더에서 생성된 멜 스펙토그램을 이용하여 Linear 스펙토그램을 생성하는 후처리 부분으로 나뉠 수 있습니다. 그리고 추가적으로 모델로부터 나온 최종 결과물인 Linear 스펙토그램을 오디오로 바꿔주는 Grifin-Lim 알고리즘이 있습니다. 인코더와 디코더 안에는 공통적으로 반복되는 CBHG 공통 모듈이 존재합니다.
1) Input & Output
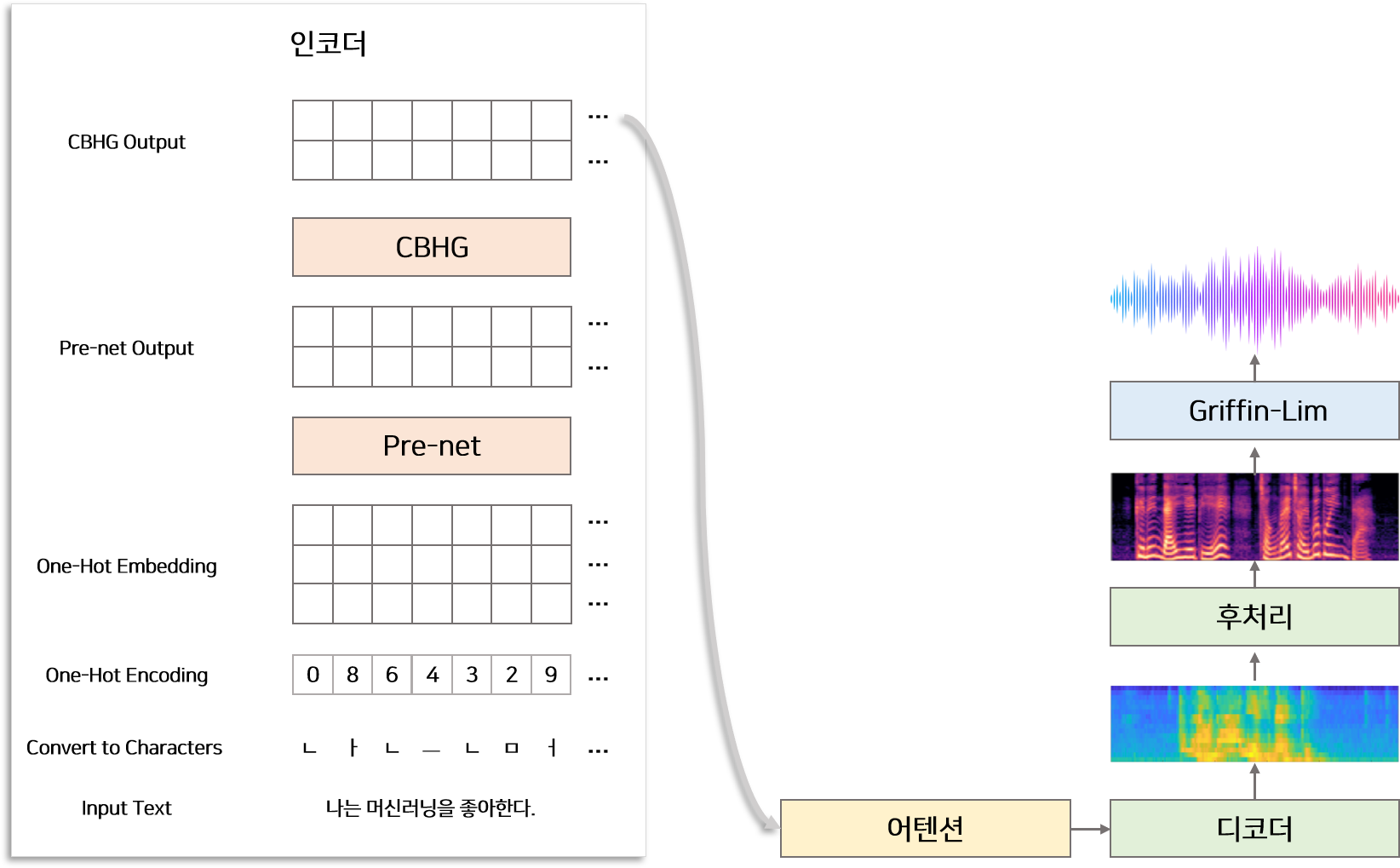
모델의 학습(Training) 및 추론(Inference) 단계에서 Input은 캐릭터 단위의 One-hot 벡터 입니다. 따라서 영어 문장을 모델에 넣기 위해서는 문장을 캐릭터 단위로 나누고 One-hot Encoding하는 작업이 필요합니다. 예를들어 ‘I love you’ 문장은 각각 한개의 캐릭터 ‘i’, ‘ ‘, ‘l’, ‘v’…, ‘u’ 로 나누고 One-hot Encoding을 통해 각 캐릭터에 맞는 숫자열[8, 6, 13, …, 2]로 변형한 뒤 모델의 Input으로 사용합니다. 한글의 경우 문장을 초성, 중성, 종성, 그리고 문장 부호로 나누어 총 80개의 캐릭터로 문자를 나누고 난 뒤 One-hot Encoding을 통해 숫자열로 변형합니다.
한글의 경우 초성과 종성의 자음은 각각 다른 캐릭터로 임베딩하여 처리합니다. 예를들어 나는 -> [ㄴ,ㅏ,ㄴ,ㅡ,ㄴ] -> [2, 4, 2, 5, 8] 으로 표현된 것처럼 ‘ㄴ’은 초성, 종성에 따라 다르게 임베딩됩니다. [한국어 타코트톤 적용 참고자료]
모델의 추론(Inference) 단계에서 Output은 Linear 스펙트로그램 입니다.
모델을 학습할 때에는 후처리 부분에서의 Ouput인 Linear 스펙토그램 뿐만 아니라 디코더 부분에서의 Output인 멜 스펙토그램을 함께 사용합니다.
즉 손실함수를 Linear 스펙토그램 Loss + 멜 스펙토그램 Loss 로 구성하여 학습합니다.
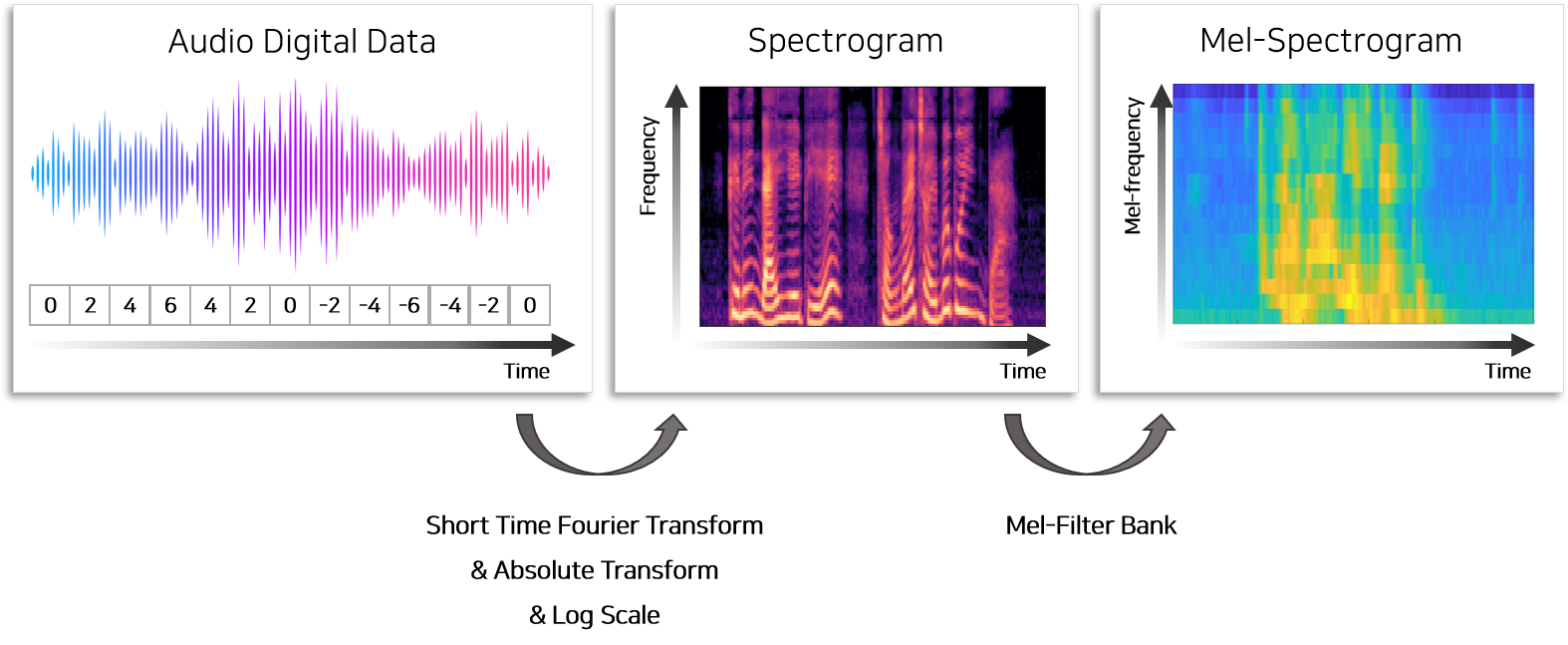
모델에 사용하는 Linear 스펙트로그램은 Short-Time Fourier Transform 뿐만아니라 로그스케일, 노말라이징, 데시벨 스케일링 등의 다양한 전처리를 통해 추출됩니다. 멜 스펙토그램은 Linear 스펙토그램을 Mel filter Bank라는 필터에 통과시켜 얻을 수 있습니다. 자세한 전처리 과정은 [오디오 데이터 전처리] 에서 참고 부탁드립니다.
2) CBHG 모듈
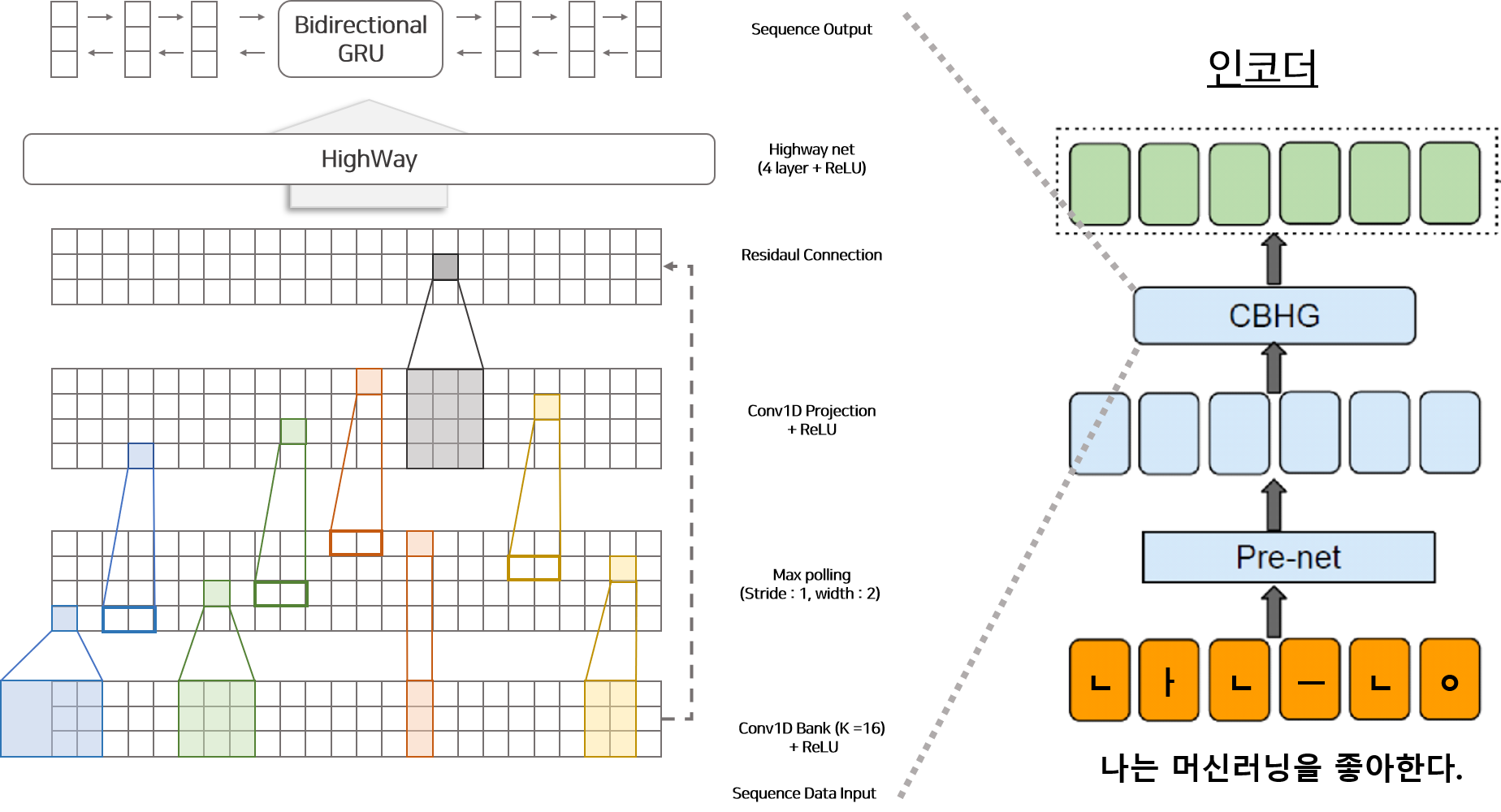
CBHG 모듈은 인코더와 디코더에 공통적으로 존재하는 모듈로써 순차적인(Sequence) 데이터를 처리하는데 특화되어 있습니다. CBHG 모듈은 1D Convolution Bank, Highway 네트워크, Bidirectional GRU로 구성되어 있습니다. 모듈은 Sequence 벡터를 Input으로 사용하며 Sequence 벡터가 Output으로 추출됩니다. 모듈의 상세 프로세스는 아래와 같습니다.
- Sequence 데이터를 1부터 K개의 필터를 갖고 있는 1D Convolution bank에 통과시켜 Feature 벡터를 생성합니다.
- Feature 벡터를 Max polling Layer에 통과시켜 Sequence에 따라 변하지 않는 부분(local invariance)을 추출합니다.
- 고정된 폭을 갖은 몇개의 1D Convolution Network을 통과시켜 Sequence 데이터의 벡터 사이즈와 일치하는 벡터를 생성합니다.
- 3)에서 생성된 벡터와 1)의 Sequence Input 벡터를 더하여 Residual Connection을 구성합니다.
- 4)에서 생성된 벡터를 Highway 네트워크에 통과시켜 high-level features를 생성합니다.
- high-level features를 GRU의 입력으로 사용합니다.
1D Convolution Bank는 총 K개의 필터를 갖고 있습니다. 필터는 각각 $k$의 길이(1~K)를 갖고 있습니다. 즉 각 필터는 $k$개의 Sequence를 보고 연산을 통해 특정 길이($k$)를 고려하여 정보를 추출하는 역할을 합니다. CBHG 모듈 안에 있는 4) Residual Connection은 모델의 깊게 쌓을 수 있게 하며 학습할 때 빠르게 수렴할 수 있도록 돕는 역할을 합니다. 모든 1D Convolution Network는 Batch Normalization을 포함하고 있어 정규화 작용을 합니다.
Highway 네트워크
$T(x)=\sigma(FC(x))$ : FC Layer + Sigmoid
$H(x)=FC(x)$ : FC Layer
Hightway 네트워크는 Gate 구조를 추가한 Residual Connection 입니다. 일반적인 Residual Connection은 Input $x$와 함수 $H(x)$가 있을 때 결과 $y$와의 관계를 $y=x+H(x)$로 정의합니다. HighWay 네트워크는 $x$와 $H(x)$을 어느정도 비율로 섞을지를 학습하여 결정할 수 있도록 0~1의 값을 갖는 $T(x)$를 만들어 $x$와 $H(x)$에 곱해 줍니다.
3) 인코더(Encoder)
인코더는 문장으로부터 고정된 길이의 특징(벡터)를 추출하는 것이 목적입니다. 따라서 앞서 설명한 것 처럼 캐릭터 단위로 나뉜 캐릭터 One-Hot 벡터가 인코더의 Input으로 들어와 어텐션 모듈에서 사용될 Sequence 벡터로 변환되는 과정은 아래와 같습니다.
- 임베딩 매트릭스(Embedding Matrix)를 이용하여 One-Hot 벡터로 표현된 캐릭터 Input을 임베딩 벡터로 변환합니다.
- 임베딩 벡터를 (FC layer + Lelu + Dropout)으로 구성된 Pre-net 모듈에 통과시킵니다.
- Pre-Net을 통과시켜 생성된 벡터를 CBHG 넣으면 어텐션 모듈에서 활용될 Sequence 벡터가 생성됩니다.
Pre-Net에는 2층의 Fully Connected Layer(FC Layer) 입니다. 이 모듈은 과적합을 막기위한 목적으로 Dropout이 적용되어 있습니다.
4) 디코더(Decoder)
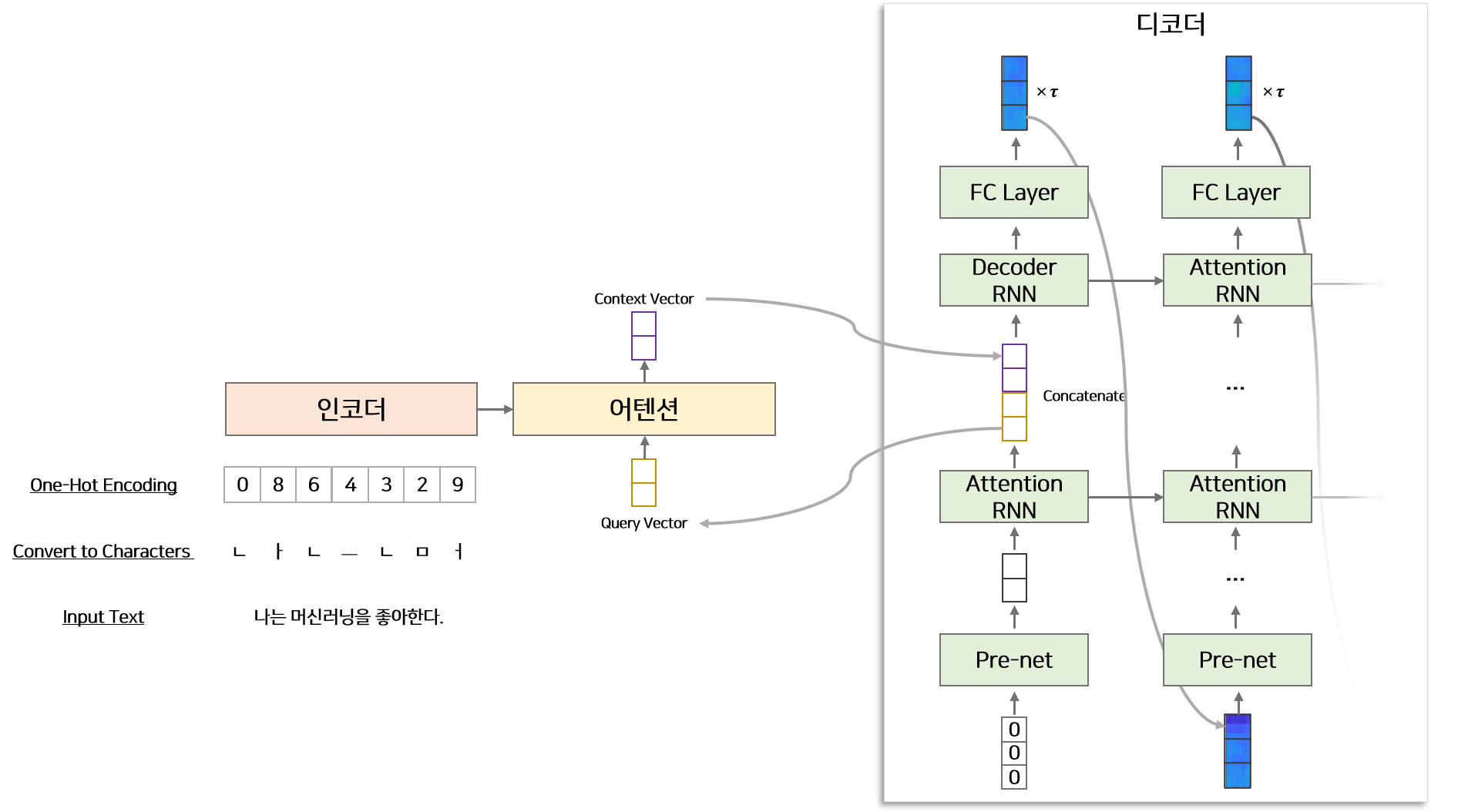
디코더는 인코더에서 생성된 Sequence 벡터와 $t-1$ 시점까지 생성된 디코더의 멜 스펙토그램을 Input으로 받아 $t$ 시점의 멜 스펙토그램을 생성합니다. 어텐션 기반 모델이므로 디코더 Attention-RNN에서 생성된 hidden 벡터($d_t$)를 query로 이용하여 인코더의 정보를 추출하고 가중합하여 Context 벡터($c_t$)를 계산하고 Decoder-RNN 모듈에 사용합니다.
- 디코더의 Input은 $t-1$ 시점까지 디코더에서 생성된 멜 스펙토그램입니다.
처음 시점에는 생성된 멜 스펙토그램이 없으므로 모든 값이 0인 멜 스펙토그램
을 Input으로 사용합니다. - 멜 스펙토그램을 Pre-Net 모듈에 통과시켜 벡터를 생성 한 후 Attention-RNN의 Input으로 사용합니다.
- Attention-RNN으로 부터 추출된 Sequence hidden 벡터($d_1, d_2, …, d_{t}$)를 어텐센 모듈에 넣어 인코더의 벡터의 각 시점과 관련된 벡터의 가중합인 Context 벡터($c_1, c_2, …, c_{t}$)를 추출합니다.
- Attention-RNN hidden 벡터($d_1, d_2, …, d_{t}$)와 Context 벡터($c_1, c_2, …, c_{t}$)를 Concatenate 하여 Decoder-RNN의 Input으로 사용합니다.
- Decoder-RNN에서 추출된 결과가 디코더의 Output인 $t$ 시점의 멜 스펙토그램입니다.
인코더와 마찬가지로 디코더의 Pre-Net도 과적합을 막기 위한 목적으로 Dropout이 적용되어 있는 Fully Connected Layer입니다. 디코더의 결과물은 멜 스펙토 그램입니다. 일반적으로 오디오로부터 추출한 멜 스펙토그램은 시간에 따라 천천히 변하는 연속한 프레임으로 구성되어 있습니다. 따라서 겹치는 정보가 많으므로(연속시점의 멜 스펙토그램은 반복되는 프레임으로 구성된 경우가 많음) 디코더에서 한 시점에서 여러개($\tau$)의 멜 스펙트그램을 생성하여 학습 및 수렴 속도를 상승시킵니다. 즉 총 $p$길이의 멜 스펙토그램이 존재하면 디코더에서 예측하는 총 시점은 $t=p/\tau$ 가 됩니다. 그리고 매 시점별 디코더에서 생성된 멜 스펙토그램를 $\tau$개 복사하여 후처리 모듈의 Input으로 사용합니다.
5) 어텐션(Attention)
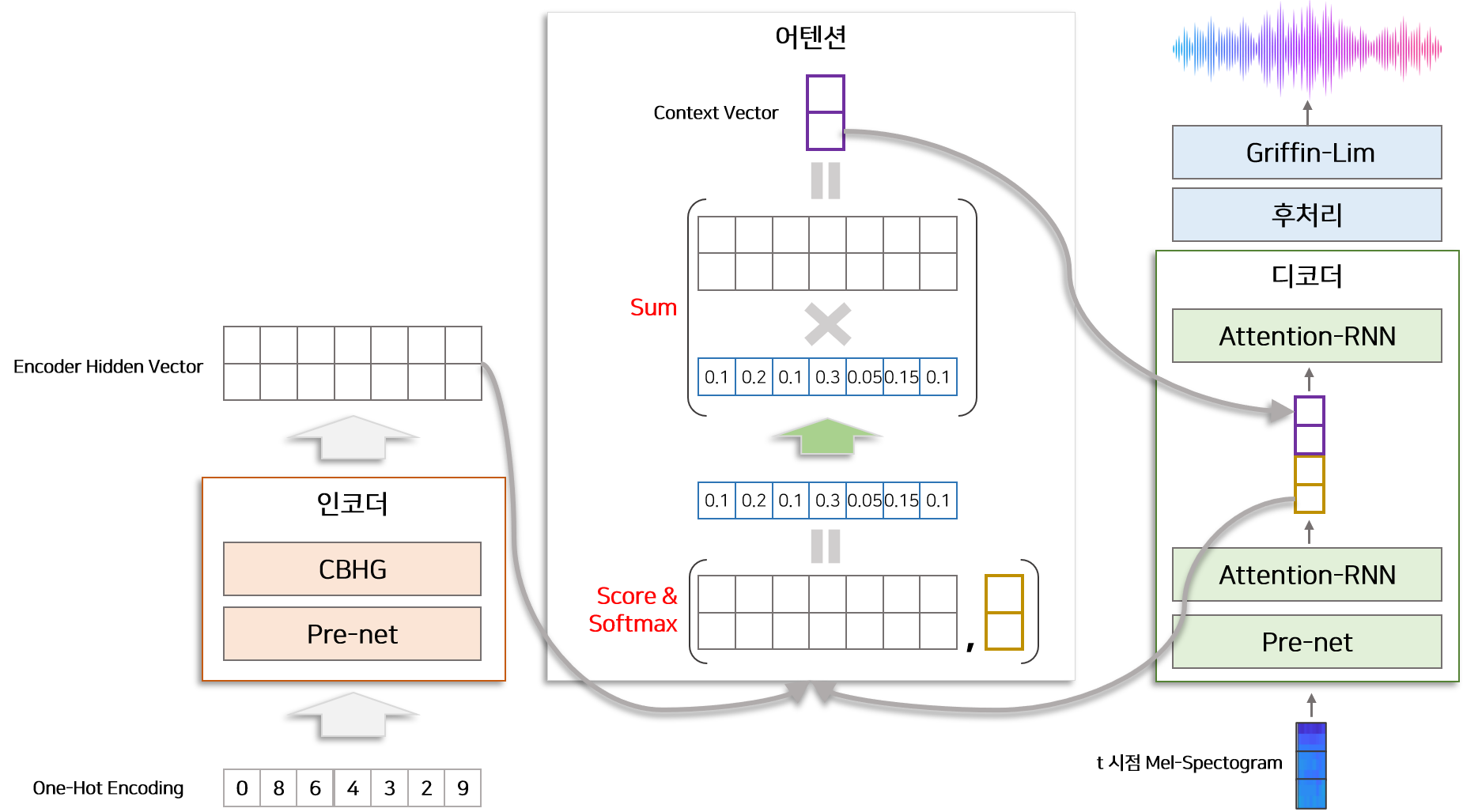
Seq2Seq 구조의 특성상 인코더와 디코더 사이에 Bottle Neck이 존재하여 모델 정확도가 하락하거나 Gradient Vanishing 문제가 발생하므로 이를 해결하기 위하여 어텐션 구조가 제안되었습니다. 어텐션에는 다양한 형태가 존재하지만 타코트론에서 적용한 방법은 Bahdanau Attetnion 입니다. $h_1, h_2, …, h_n$는 인코더에서 생성된 $n$개의 Hidden 벡터이고, 디코더의 모듈 Attention-RNN에서 $t$ 시점에 생성된 Hidden 벡터를 $d_t$라고 할때 Bahdanau Attention 통해 구한 Context 벡터 $c_t$는 아래와 같습니다.
위 식은 Medium BLOG 글을 참고하여 재구성하였습니다. 위의 식이 전체적으로 의미하는 것은 $d_t$ 와 $h_n$ 가 얼마나 유사한지를 계산하고 그 비율대로 $h_n$을 곱하여 Context 벡터 $c_t$를 구성하는 것입니다. 좀 더 자세하게 설명하면 Score Function에서 $w_a, w_h$는 각 인코더, 디코더에서 생성된 Hidden 벡터를 낮은 차원으로 사영(Projection)하는 Fully Connected Layer입니다. 이 Layer를 통해 동일한 차원으로 사영된 벡터를 서로 합하여 $tanh$ 비선형 함수를 씌운뒤 $v^T$ 벡터와 Element-Wise 곱하여 하나의 숫자로 변형 합니다. 이 숫자가 의미하는 것은 $d_t$ 와 $h_n$ 가 주어졌을 때 계산된 유사도 점수입니다. 이 유사도 점수를 기반으로 각 인코더의 Hidden 벡터를 가중합 한 벡터가 Context 벡터 $c_t$입니다.
6) 후처리(Post Processing) & Griffin-Lim 알고리즘
후처리 모듈은 디코더에서 생성된 멜 스펙토그램을 이용하여 Linear 스펙토그램을 생성하기 위한 과정입니다. Seq2Seq 모델의 특성상 디코더는 시점별로 한개씩 멜 스펙토그램을 생성하지만 후처리에서는 디코더에서 멜 스펙토그램을 모두 생성한 후 이를 이용하여 Linear 스펙토그램을 생성합니다. 즉 후처리는 멜 스펙토그램의 전체 모습을 보고 Linear 스펙토그램을 생성하므로 후처리 모듈 없이 디코더에서 바로 Linear 스펙토그램을 생성한 타코트론 모델보다 좋은 품질의 음성을 생성합니다. 후처리 모듈은 CBHG 모듈로 구성되어 있습니다.
Griffin-Lim 알고리즘은 Linear 스펙트로그램을 음성 신호로 합성하는데 사용하는 알고리즘입니다. 이 알고리즘은 특정 모델을 가정하지 않고 음성을 합성할 수 있으며 단순 반복작업을 통하여 음성 신호를 생성하므로 계산량에 있어서 일반적인 보코더보다 유리한 장점을 갖고 있습니다. 자세한 사항은 Griffin-Lim Algorithm 참고바랍니다.
실험 및 결과
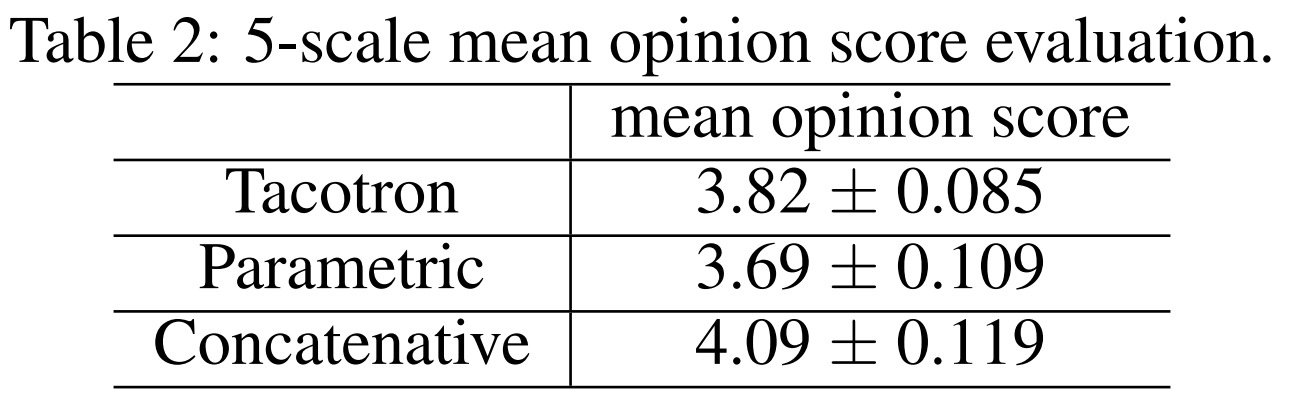
TTS(Text to Speech) Task에서 모델의 성능을 평가하기 위하여 피실험자에게 실험모델로부터 생성된 음성을 들려주고 1~5점의 품질 점수를 선택하도록 하는 실험(MOS TEST)을 진행합니다. 비교모델로 LSTM 기반 Parametric 모델과 Concatenative 모델을 사용합니다. 이 테스트에서는 타코트론 모델이 Parametric 보다는 좋은 평가점수를 받았습니다. 비록 Concatenative 모델보다 낮은 평가점수를 획득하였지만 타코트론은 텍스트를 분석하거나 음향 모델링과 같은 전문가의 손길 없이 구현이 가능하므로 고무적인 성과로 볼 수 있습니다.
결론 및 개인적인 생각
2020년 현재를 기준으로 타코트론을 한글에도 적용한 구현체 및 논문이 있어 참고하기 좋았습니다. 오디오 전처리 방법에 대해 깊게 고민하지 않아도 어느정도는 딥러닝 모델에서 보정해 주기 때문에 오디오 데이터 다루는 법을 잘 몰라도 구현이 가능해 보입니다. 하지만 성능을 향상시키기 위하여 오디오 특징들을 이해할 필요가 있어보입니다. 타코트론은 CBHG 모듈로 Sequence 정보를 추출하도록 구성하였지만 이 구조가 소리를 분석하는데 얼마나 효과적인지 더 많은 실험이 필요해 보입니다. 타코트론과 비슷한 다양한 모델들(Seq2Seq-Attention 기반)이 있는데 그 모델들과 비교평가가 있었더라면 좋겠다는 생각이 듭니다.
Reference
- [BLOG] [Speech Synthesis] Tacotron 논문 정리
- [BLOG] Text to speech Detailed Explanation
- [BLOG] Neural Machine Translation using Bahdanau Attention Mechanism
- [SLIDE] 책 읽어주는 딥러닝: 배우 유인나가 해리포터를 읽어준다면 DEVIEW 2017
- [PAPER] 한국어 text-to-speech(TTS) 시스템을 위한 엔드투엔드 합성 방식 연구
- [BLOG] MFCC 이해하기
- [GITHUB] Tacotron pytorch