[코드리뷰] - 타코트론2 TTS 시스템 1/2
최근 몇년간 TTS(Text to Speech)는 빠르게 발전하여 이제는 복잡한 작업 절차 없이 데이터를 이용하여 텍스트로부터 고품질의 음성을 생성할 수 있는 방법론이 개발되었습니다. 방법론 뿐만 아니라 코드와 데이터까지 Github, Kaggle 등과 같은 공개저장소에 공개되면서 이제는 개발과정조차 간소화되어 진정한 의미로 개인화 TTS를 개발할 수 있는 환경이 구축되었습니다.

하지만 딥러닝에 대해 잘 아는 사람들도 음성이라는 낯선 도메인 때문에 쉽게 접근하지 못하여 TTS 시스템을 개발하지 못하는 것이 현실입니다. 따라서 오늘 포스팅에서는 Tacotron2와 WaveGlow를 이용하여 간단하게 개인화 한글 TTS를 개발하는 파이프 라인을 설명드리도록 하겠습니다.
이글은 2018년 ICASSP 2018에서 공개된 Tacotron2 논문의 구현체를 기반으로 개인화 시스템을 만드는 방법에 대해 설명드리려고 합니다. 현재 기준으로 더 고도화 된 TTS논문들이 공개되었기 때문에 해당 논문들에 비하면 성능(음성 품질)이 떨어지고, 많은 데이터를 필요로 합니다. 따라서 좀 더 고품질의 음성 및 실제 활용화 할 수 있는 시스템을 원하시는 분들의 눈높이에 맞지 않을 수 있습니다.
이 글은 개인적인 의견을 담고 있기 때문에 실제 내용과 다를 수 있습니다. 또한 딥러닝 아키텍처에 대해 이해하고 python 프로그래밍 경험이 있는 분들은 대상으로 작성되었습니다. 따라서 기본적인 라이브러리 설치 및 가상환경 설정 방법에 대해 다루고 있지 않습니다.
딥러닝 아키텍처(타코트론2)에 대해 궁금하신 분이 계시다면 이전 글 또는 세미나 영상 을 참조하시기 바랍니다.
Short Summary
개인화 TTS 시스템을 만드는 과정을 크게 나누면 아래와 같습니다.
- 데이터 수집
- 음성 데이터 전처리
- 스크립트 전처리
- Tacotron2 모델 학습
- WaveGlow 모델 학습
글을 나누어서 1부에서는 데이터를 전처리하는 방법에 대해 다루도록 하겠습니다.
1. 데이터 수집
모델을 학습하는데 필요한 데이터(음성, 스크립트)를 수집하는 단계입니다. 데이터는 개인의 음성과, 음성의 발화 내용이 적혀있는 스크립트로 이루어져 있어야 합니다. 음성데이터는 개인의 음성을 녹음한 음성파일(.wav, .pcm, .raw, .mp3) 등을 의미합니다. 스크립트는 음성의 발화 내용이 적혀있는 .txt 파일을 의미합니다.
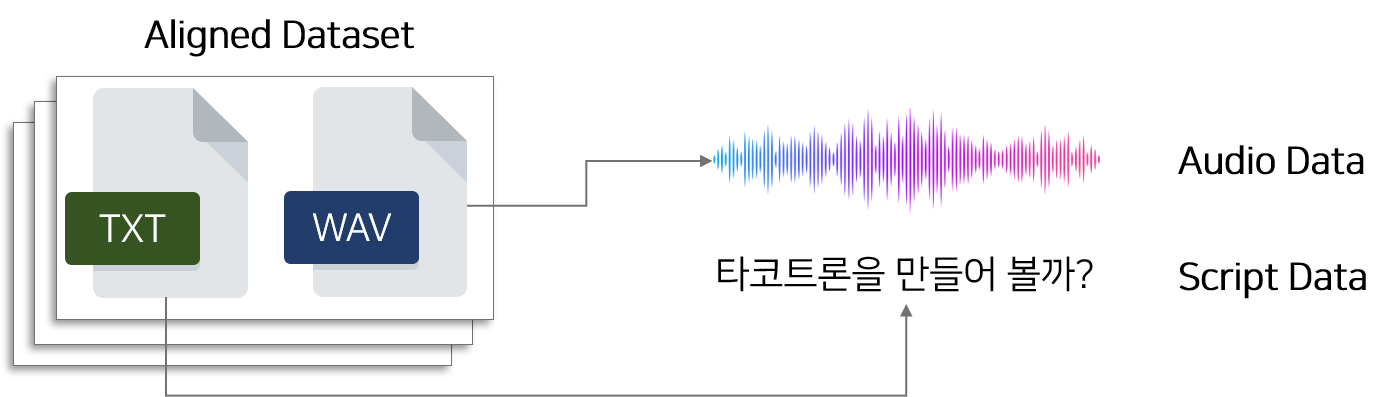
데이터를 수집하는 방법에는 다양한 형태가 있을 수 있습니다.
- 이미 구축된 데이터(음성, 스크립트)를 가져오는 방식
- 직접 음성을 녹음하고 스크립트를 제작하여 데이터를 만드는 방식
- 녹음된 음성 클립을 가져와서 스크립트를 제작하여 데이터를 만드는 방식
1.1 구축된 데이터 활용
너무나 당연한 이야기이지만 음성 데이터 안에 Noise가 적을 수록 모델은 음성과 텍스트 사이의 패턴을 잘 파악할 수 있습니다. 따라서 노이즈가 제거된 구축된 데이터를 활용하는 것이 가장 좋은 품질의 음성을 생성할 수 있습니다. 게다가 스크립트 데이터도 함께 주어지는 경우 데이터 수집으로 인해 발생하는 고된 전처리 작업을 피할 수 있는 장점을 갖고 있습니다.
외부에 공개된 TTS 데이터로는 LJ speech dataset(English), VCTK dataset (English), KSS dataset (Korean) 등이 있습니다. 특히 KSS 데이터는 전문 여성 성우 1명의 음성으로 제작된 데이터로써, 품질이 매우 좋고 약 12시간 분량의 풍부한 음성파일로 구성되어 있습니다.
1.2 직접 음성을 제작
개인화 TTS를 개발하는 대부분의 사람들은 본인의 음성 또는 지인의 음성으로 개발하기를 원하기 때문에 직접 음성을 제작하는 경우가 대부분입니다. 따라서 직접 음성을 제작하는 경우가 많은데 이는 노이즈가 없는 환경에서 음성을 제작할 수 있기 때문에 좋은 품질의 음성모델을 구축할 수 있습니다.
음성을 제작할 떄 음성을 녹음하고 스크립트를 만드는 방식도 좋지만 개인적으로 스크립트를 먼저 제작하고 음성을 녹음하는 방식이 더 효율적입니다. 스크립트를 따로 만드는 것보다 이미 구축된 스크립트(일정 길이의 문장)를 사용하는 것이 효율적이므로 외부 서적, KSS 데이터의 스크립트 등을 활용하여 제작하는 것을 추천드립니다.
주의할 점은 스크립트에 다양한 형태(평서문, 의문문, 명령문, 감탄문 등)의 문장이 포함되어 있어야합니다. 만일 평서문(일반적으로 ~~합니다.로 끝나는 문장)으로만 스크립트를 구성할 경우 모델은 명령문(일반적으로 ~~해. 로 끝나는 문장)을 재대로 발화하지 못하는 현상이 발생할 수 있습니다.

또한 스크립트를 만들 때 가능한 숫자나 영어, 특수문자를 한글로 변환하여 기록하는 것을 추천드립니다.
숫자의 경우 1을 ‘하나’로 발음하는 경우가 있고 ‘일’로 발음하는 경우가 있습니다. 이는 앞 뒤 단어에 따라 동일한 숫자가 다르게 발음되기 때문입니다. 많은 데이터가 있다면 모델이 이 숫자 패턴을 인식하여 잘 학습하겠지만 적은 데이터로는 모델의 학습을 방해하는 역할을 합니다. 따라서 데이터가 적다면 이 부분을 한글로 변환하는 작업이 필요합니다.
변환 작업은 스크립트 전처리 과정(수동 처리)이나 전처리 코드(자동 처리)에서 적용할 수 있습니다. 코드로 만들어서 처리하는 것이 실제 활용성 측면에서 더 좋지만, 모델을 더 잘 학습하는 측면에서는 직접 전처리(수동) 하는 것이 좋습니다. 따라서 직접 음성과 스크립트를 제작할 때 이를 반영하여 미리 영어, 숫자, 특수문자등을 한글로 작성하는 것을 추천드립니다.

1.3 녹음된 음성으로 데이터 제작
외부 녹음된 음성 클립으로 데이터를 제작하는 것은 사실상 매우 어려운 일입니다. 일단 녹음된 음성에 다양한 배경음악, 환경소음이 포함되어 있는 경우가 대부분이기 때문에 음성의 품질이 좋지 않습니다. 또한 녹음된 음성에 맞는 스크립트를 제작하는 것이 생각보다 고된 작업이기 때문입니다. 하지만 해당 작업을 통해 음성을 제작하고 싶다면 음성편집 및 스크립트 자동생성과 관련된 몇가지 Tool을 추천드립니다.
[1] Audacity : 음성 편집기(무료)
Audacity는 무료 음성 편집기 중 하나입니다. 간단하게 음성을 자를 수 있도록 편의성 있는 UI를 제공하기 때문에 간편하게 사용할 수 있습니다.
또한 데이터 전처리과정에서 필요한 배경 노이즈를 제거하는 기능을 포함하고 있으므로 활용성이 높습니다.
개인적인 의견을 덧붙이자면 여러개의 음성을 한꺼번에 작업(환경 소음 제거)할 수 있는 것이 이 프로그램의 가장 큰 장점입니다.
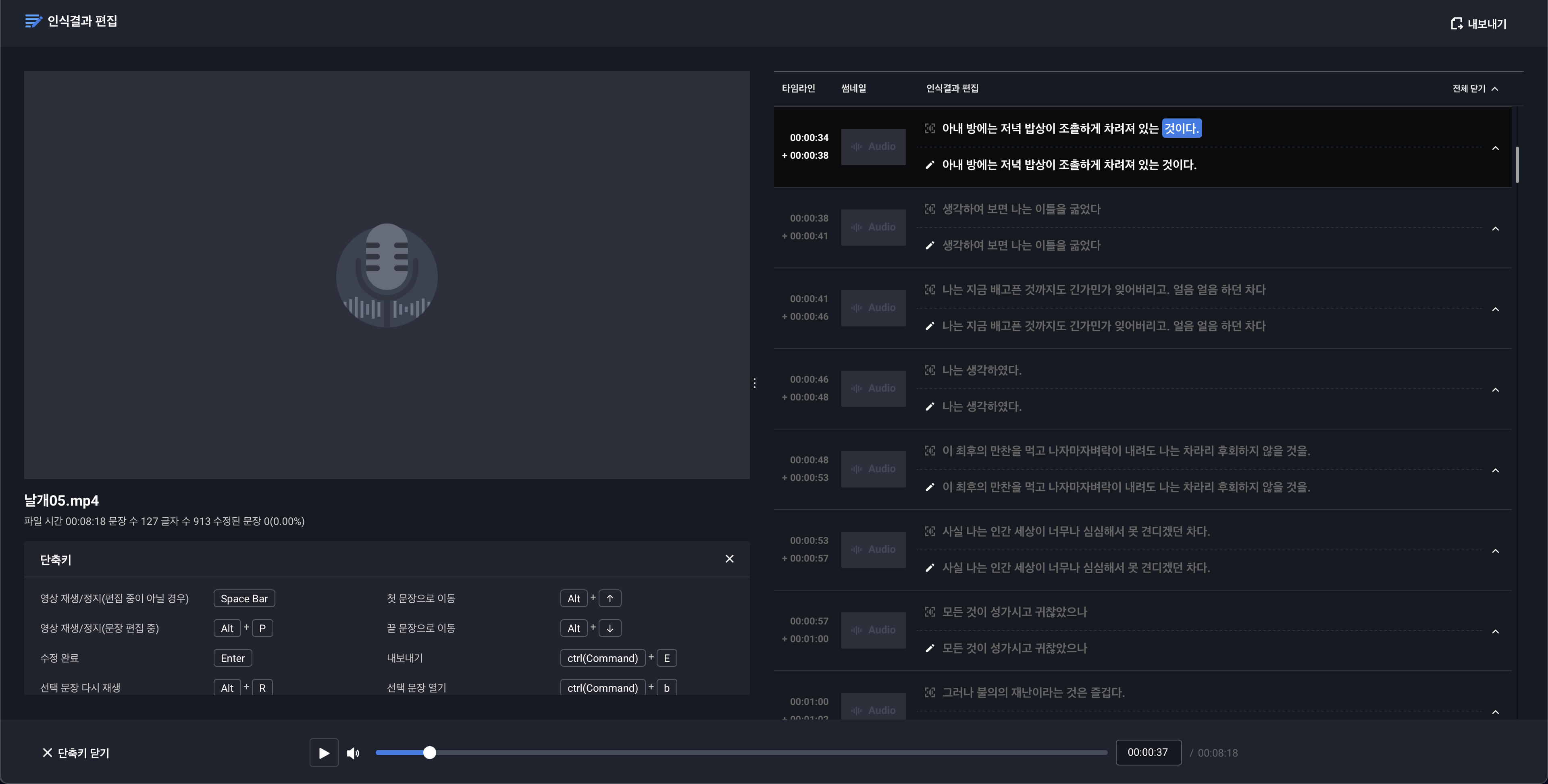
[2] Clova Speech : 자막 생성기(유료)
Clova에서 제공하는 자막 생성기입니다. 음성파일을 듣고 직접 스크립트를 생성하는 것은 많은 시간이 소요될 뿐만 아니라 고된 작업입니다.
Clova에서 제공하는 자막 생성기를 활용하면 비교적 빠른 시간 안에 음성에 맞는 자막을 생성할 수 있습니다.
또한 음성이 발화된 시간대를 표기하게 제공하므로 음성을 자르고 스크립트를 구성하는 작업이 빨라 질 수 있습니다.
생성된 자막품질은 대부분 우수하나 틀린 스크립트가 존재 할 수 있으므로 더 좋은 모델을 만들기 위해서는 검수과정이 필요할 수 있습니다.
게다가 유로 프로그램이기 때문에 생각보다 많은 비용이 필요할 수 있습니다.
[3] VREW : 자막 생성기(부분무료)
VREW는 보이저엑스(voyagerX) 인공지능 스타트업에서 만든 자막생성 프로그램입니다.
영상데이터서 음성자막을 추출할 수 있는 기능을 제공하며, 영상과 자막의 싱크를 맞출 수 있도록 편의성 있는 UI를 제공합니다.
영상데이터에서 음성과 스크립트를 생성해야 한다면 해당 프로그램을 활용하는 것이 데이터 제작 시간을 단축하는데 큰 역할을 할 수 있습니다.
다만 2021년 기준으로 매월 90분 정도 음성인식 기능을 무료로 제공한다고 하니, 긴 데이터 제작이 필요하다면 유로결제가 필요할 수 있습니다.
[4] ESPnet(한글) : 음성 인식 API(무료)
ESPnet은 음성인식 모델을 개발할 수 있도록 과련 개발 모델 및 파이프라인을 잘 정리한 오픈소스입니다.
최근 ETRI 에서 1000시간 분량의 한국어 음성 데이터 와 Espenet 오픈소스를 활용하여 모델을 만들고 학습 Checkpoint와 사용방법(Tutorial)을 공개하였습니다.
이 프로그램을 활용하면 무료로 음성으로부터 스크립트를 생성할 수 있습니다.
다만 프로그램을 활용하려면 Pytorch 및 Python 프로그래밍 능력이 필요하며, 스크립트 생성 품질이 유료 프로그램보다 떨어질 수 있습니다.
게다가 긴 길이의 음성은 직접 잘라서 프로그램에 넣어줘야 하는 불편함이 있으므로, 빠르게 데이터 생성 작업이 필요하다면 좋은 선택이 아닐 수 있습니다.
[5] 구글STT : 음성 인식 API(부분무료)
구글에서 제공하는 STT 시스템입니다. 음성인식이 매우 잘 되며 쉼표, 마침표, 물음표까지 달아주는 기능을 갖고 있습니다.
또한 오디오와 같은 콘텐츠가 중간에 삽입되어 있을 때 필터링 하는 기능을 갖고 있기 때문에 매우 강력합니다.
화자분할 기능도 포함하고 있으므로 여러명의 음성이 포함되어 있는 경우 구분이 가능하도록 STT를 제공합니다.
매달 60분은 무료이나 그 이후는 유료입니다.

2. 음성 데이터 전처리
음성 데이터에서 전처리를 하는 이유는 2가지 입니다.
- 배경소음(잡음)을 제거
- 불필요한 음성(백색소음&공백)을 제거
- 음성의 Sampling Rate를 변경

2.1 잡음 제거
만약 음성을 직접 녹음하였다면 방음이나 차음이 잘 되어있는 환경에서도 백색 소음 또는 잡음이 포함되어 있을 수 있습니다. 또한 외부 녹음된 음성 클립을 추출한 경우에는 거의 대부분 소음이 포함되어 있습니다.
이러한 소음을 제거하지 않고 모델을 학습하면 모델이 잘 수렴하지 않을 수 있으며, 학습된 모델에서 발화된 음성 뿐만아니라 듣기 싫은 음성이 포함될 수 있습니다. 따라서 목표로 하는 음성을 제외한 잡음을 제거하는 작업이 반드시 필요합니다.

잡음을 제거하기 위하여 사용할 수 있는 대표적인 프로그램으로 2가지 정도를 살펴보겠습니다.
[1] Adobe Audtion : 오디오 편집기(유료)
오디오 편집기 중 가장 유명한 Adobe 프로그램입니다.
유투브(잡음 제거 영상) 및 블로그(어도비 오디션 강좌) 등 다양한 곳에서 튜토리얼을 제공하고 있기 때문에 간편하게 음성 데이터에서 노이즈를 제거하는 방법을 배울 수 있습니다.
해당 프로그램을 이용하면 잡음 제거 뿐만 아니라 음성 보정(깨끗하고 선명하게)도 가능합니다. 다만 유료 프로그램이라는 단점을 갖고 있습니다.
[2] Audacity : 음성 편집기(무료)
음성 수집단계에서도 언급했던 Audacity는 유용한 무료 음성 편집기 입니다.
해당 편집기의 가장 큰 장점은 여러개의 음성을 한꺼번에 작업할 수 있다는 점 입니다.
일반적으로 음성을 동일한 환경에서 직접 생성하였다면 잡음의 패턴도 비슷하기 때문에 한꺼번에 작업(잡음제거)하는 것이 전처리 시간을 단축할 수 있습니다.
2.2 공백 자르는 작업
녹음 방법에 따라 음성의 시작과 끝에 아무런 음성이 포함되지 않는 공백이 존재할 수 있습니다. 이것들을 어느정도 자르지 않고 모델의 입력으로 사용하면, 학습된 모델의 출력에도 긴 공백이 포함되어 있을 수 있습니다. 또한 모델의 입력길이가 제한되어 있으므로 긴 공백은 학습 배치사이즈에 영향을 주므로 모델 학습시간을 증가시킬 수 있습니다. 이러한 문제를 해결하고자 공백을 자르는 작업이 필요합니다.
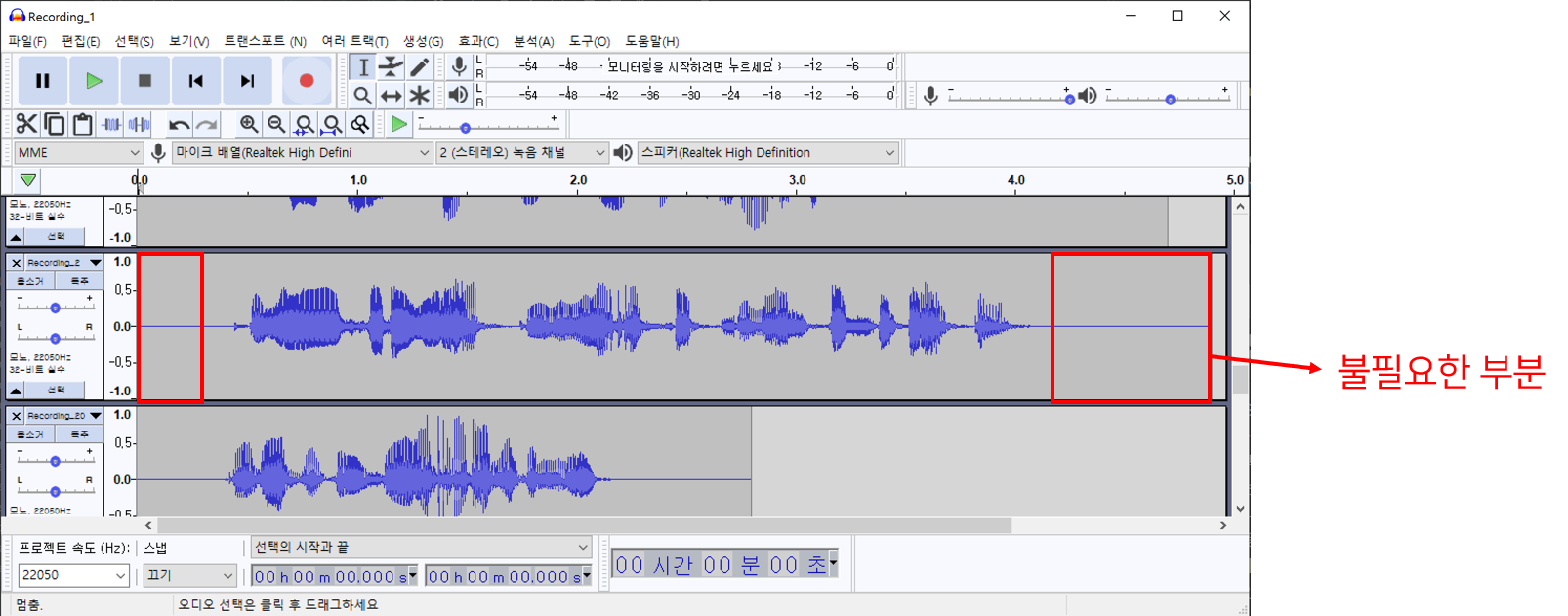
앞서 설명드린 Audacity, Adobe Audition 등을 활용하면 수동으로 공백을 자를 수 있습니다. 정확도가 높고, 혹시나 노이즈가 시작과 끝 부분에 있는 경우 제거 할 수 있다는 장점을 갖고 있습니다. 다만 긴 작업시간이 필요하다는 단점을 갖고 있습니다.
그렇기 때문에 db(decibel) 기준으로 앞 뒤를 자르는 코드를 만들어 활용하곤 합니다.
※ 주의할 점 ※
앞 뒤 공백을 너무 타이트하게 자르고 모델을 학습시키면 학습된 모델은 공백이 없는 음성을 출력하거나 앞에 단어를 묵음처리하여 학습될 가능성이 높습니다.
따라서 일정길이의 공백이 앞 뒤로 포함되도록 하는 것이 이상적인 형태인 것 같습니다.
아래 예시는 잘못 전처리한 데이터로 학습한 모델에서 ㄱ이 잘 발음되지 않는 음성 샘플입니다. “그녀는 매우 성실하다.” 라는 단어가 출력되야 하는데, “ㅡ녀는 매우 성실하다.” 라는 음성이 출력되었습니다. 이는 전처리할 때 음성을 너무 타이트하게 잘라서 학습된 모델이 ㄱ을 묵음처리한 것으로 판단됩니다.
/img/in-post/2021/2021-04-01/fault_audio_sample.wav
음성을 녹음하고 귀 기울여 듣다 보면 음성에 듣기 거북한 소리들이 존재할 수 있습니다. 예를 들어 “그녀의” 라는 단어의 앞부분만 들어보면, ㄱ라는 자음 때문에 파열음??(정확한 명칭을 잘 몰라요 댓글로 알려주세요) 이 발생하는 걸 확인 할 수 있는데, 이는 음성에서 큰 역할(치명적인, 없으면 잘 인식하지 못할 정도로)을 하지는 못하지만 이를 제거하고 모델을 학습시키면 모델은 처음 시작할 때 ㄱ을 묵음으로 처리할 가능성이 있습니다.
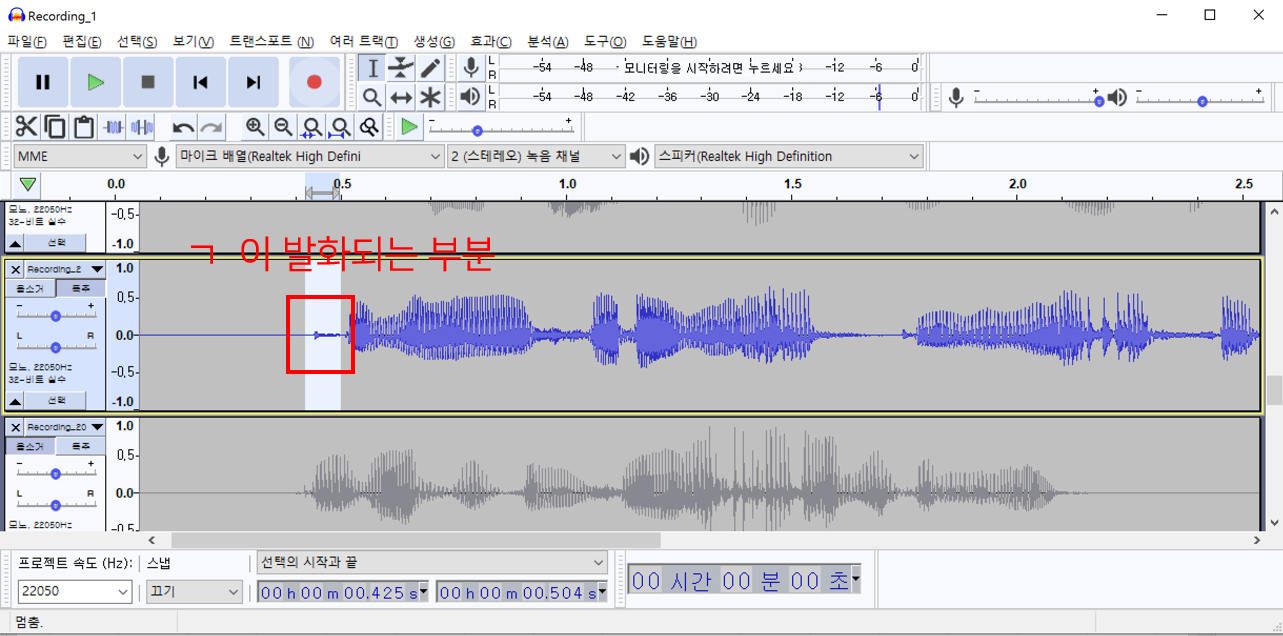
공백과 관련된 글(Trim을 이용하여 음성의 공백을 일정크기로 만들어야 한다)은 개인적인 의견입니다. 여러 음성으로 타코트론2 모델을 학습하면서 발생한 문제점(앞에 소리가 묵음으로 발생하는 현상)을 보고 원인을 파악하다 보니, 데이터 전처리에 있는 거 같아 개인적인 경험을 공유드리기 위해 해당 내용을 작성하였습니다. 따라서 이론적 background가 있지 않다는 점을 고려하고 글을 읽어주시기 바랍니다.
2.3 Sampling Rate 변경
전처리 작업 이후 TTS 시스템을 개발하는데 사용할 모델은 Tacotron2와 WaveGlow입니다. 해당 모델을 구현한 구현체의 대부분이 Sampling Rate ‘22050’으로 고정하고 있기 때문에 비슷한 환경에서 개발하기 위하여 녹음된 음성데이터의 Sampling Rate를 ‘22050’으로 변경할 필요성이 있습니다.
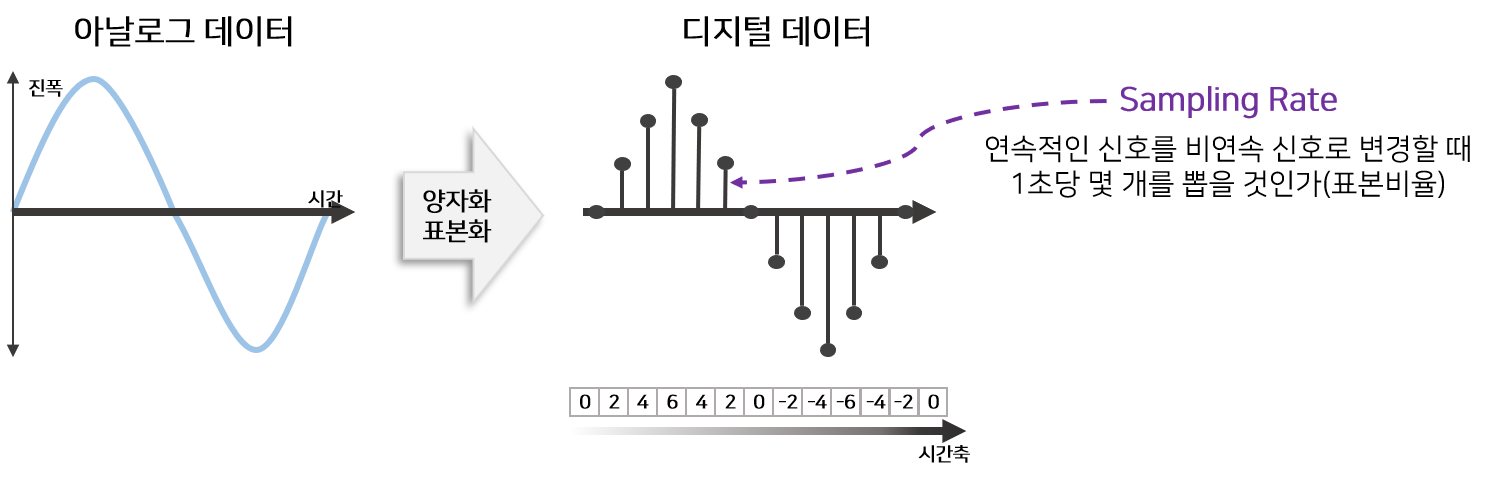
개인적인 궁금증 때문에 직접 3000개의 음성파일(약 90분)을 녹음하고 Sampling Rate를 변경하며 Tacotron2 모델을 학습시켜서 생성된 음성품질을 비교하였습니다. 제 실험에서는 Sampling Rate가 16000, 22050, 44100 음질에서 큰 차이점을 느낄수 없었습니다.
3. 스크립트 전처리
스크립트 전처리 작업은 스크립트 안에 있는 특수문자, 영어, 숫자를 한글로 변환하는 작업을 의미합니다. 앞서 한번 설명드렸던 것 처럼 데이터가 많으면 특수문자, 영어, 숫자 안에 있는 패턴을 모델이 잘 학습할 수 있습니다. 하지만 일반적으로 데이터 양이 적기 때문에 모델의 학습하는데 방해하는 역할을 합니다.
이를 해결하기 위하여 전처리 작업이 필요합니다. 전처리 하는 방법은 크게 2가지로 분류 할 수 있습니다.
- Case 별로 코드를 개발하여 전처리
- 직접 듣고 스크립트를 전처리
유연성을 생각한다면 코드로 개발하는 것이 더 효율적이며, 나중에 Inference할 때 한글만 적어야 한다는 제약을 없앨 수 있습니다. 하지만 모든 case에 따라 전처리 코드를 개발할 수 없으므로, 가능하면 2번 방법을 선택하여 직접 듣고 스크립트를 전처리 하는 것이 모델 학습 측면에서 좋습니다.

혼합해서 활용하는 것도 좋을 것 같습니다. 어느정도는 직접 듣고 직접 전처리를 하고, 전처리 코드도 개발하여 infernece 단계에서 유연하게 작동하도록 대처합니다.
전처리 작업 예시
실제 데이터를 활용하여 전처리 하는 작업에 대해 상세히 설명드리겠습니다.
Step1.1 데이터 수집하기
저는 제 음성을 발화할 수 있는 TTS 시스템을 만들기 위해서 직접 녹음하여 데이터를 구축하였습니다. 먼저 KSS 데이터 에 포함되어 있는 스크립트를 활용하기 위하여 데이터를 다운받았습니다.

그리고 그 스크립트를 그대로 읽어서 핸드폰 녹음기를 활용하여 약 3000개의 음성 데이터(약 100분)를 생성하였습니다.

Step2.1 잡음 제거
Audacity 프로그램을 활용하여 잡음 제거 하는 예시입니다. Audacity(한글버전)을 설치한 후 메뉴에서 파일(F)->가져오기(I)->오디오(A)를 순서대로 클릭하여 여러개의 오디오파일을 한꺼번에 불러옵니다.
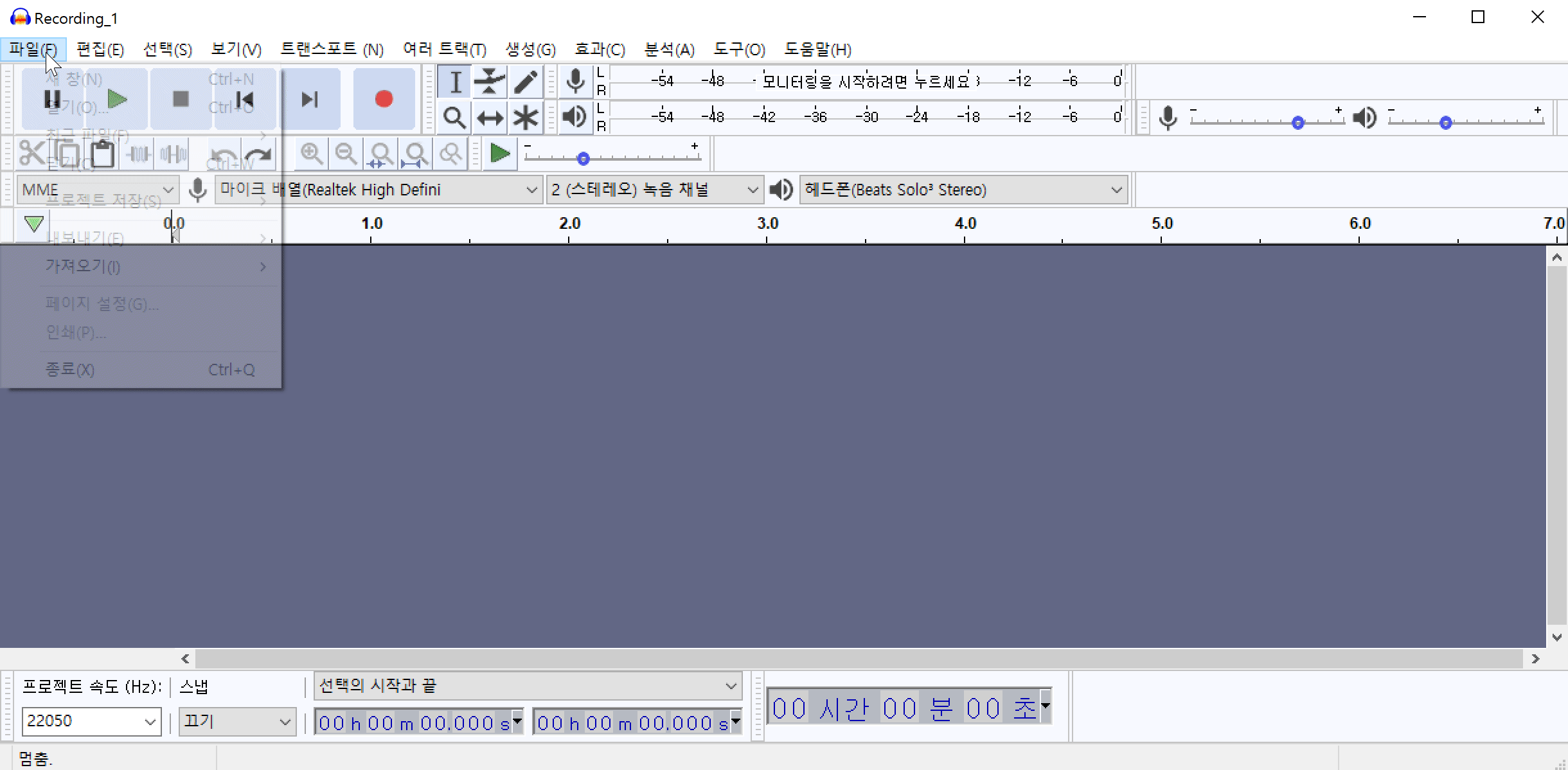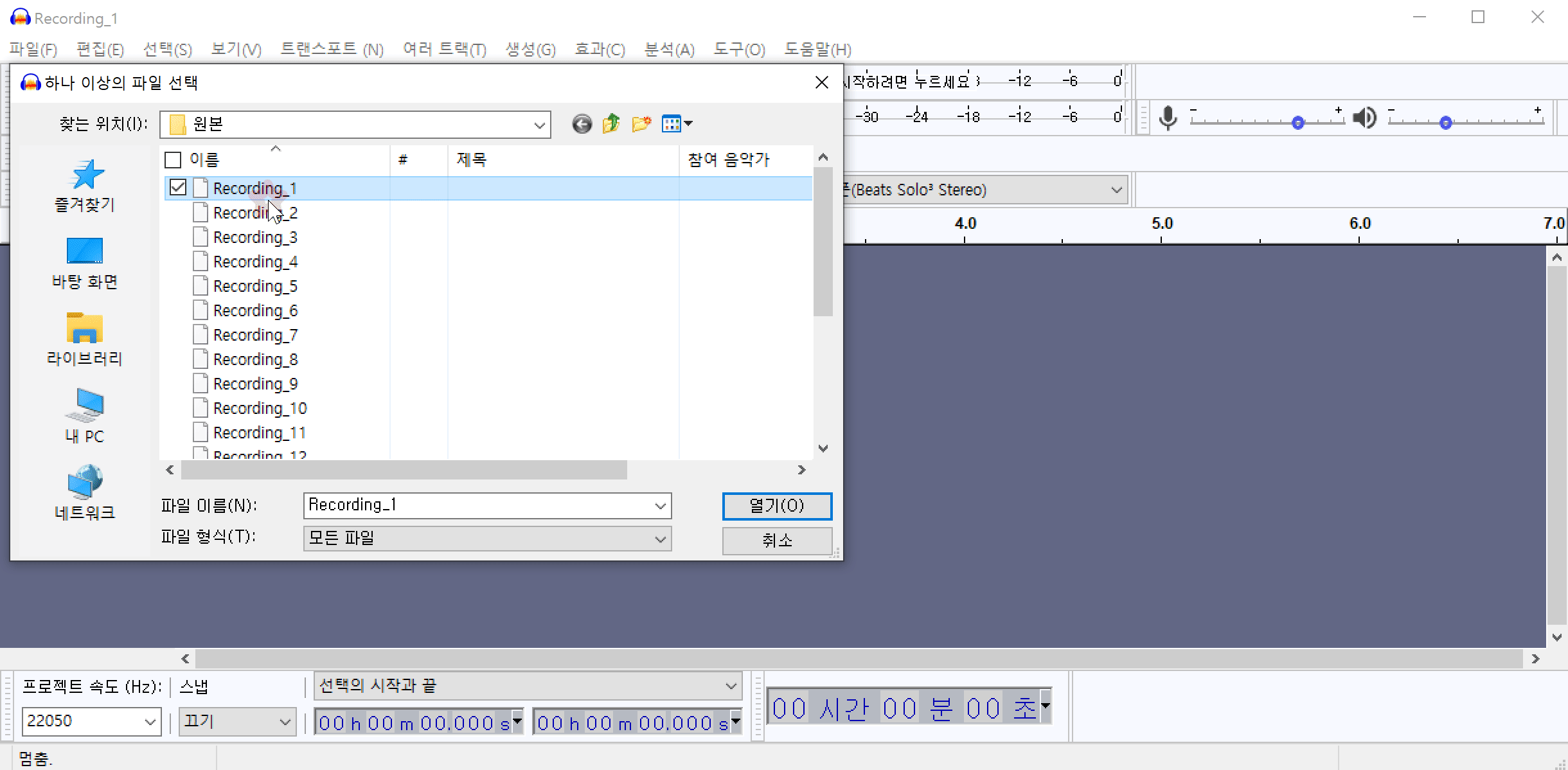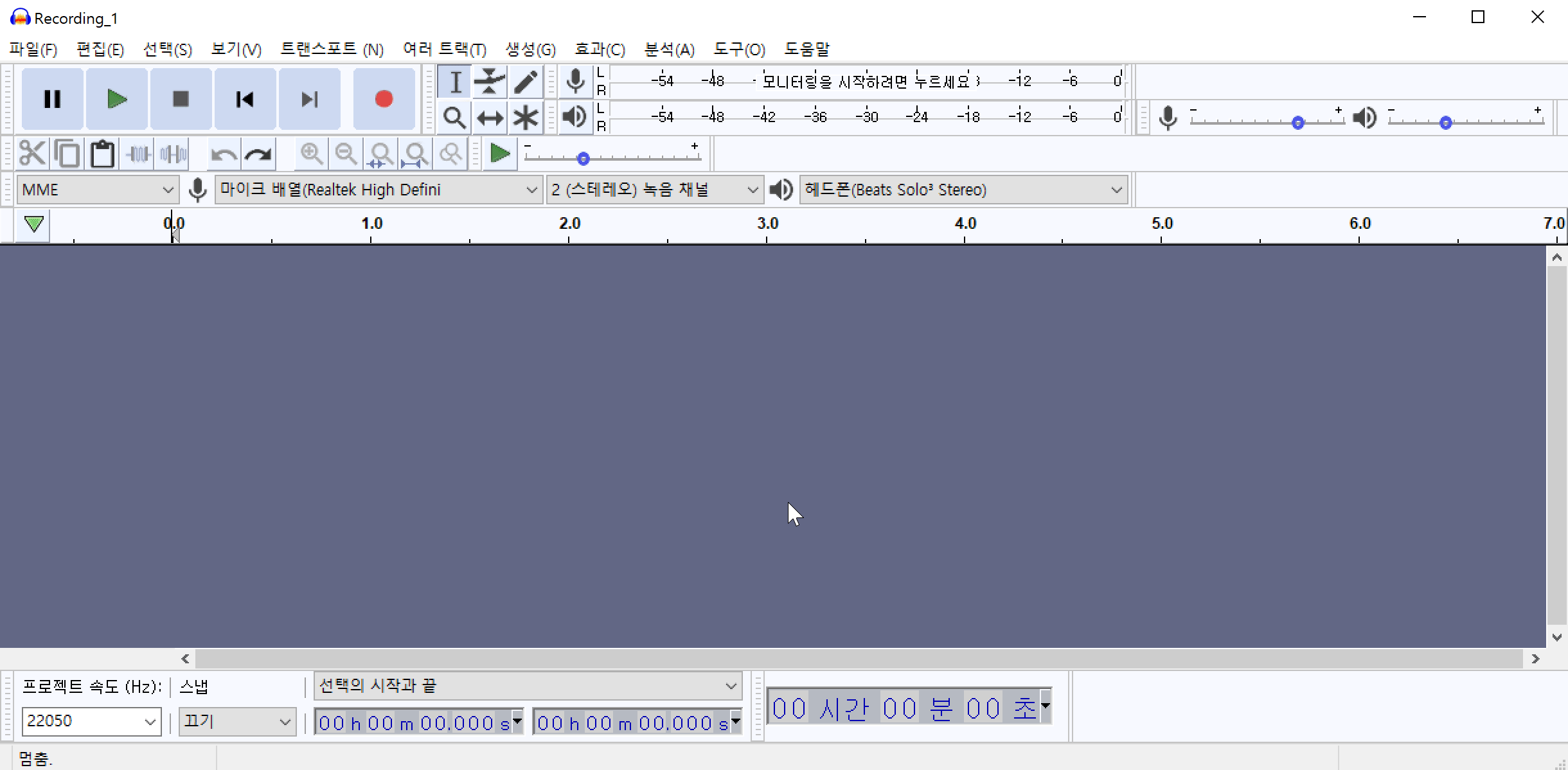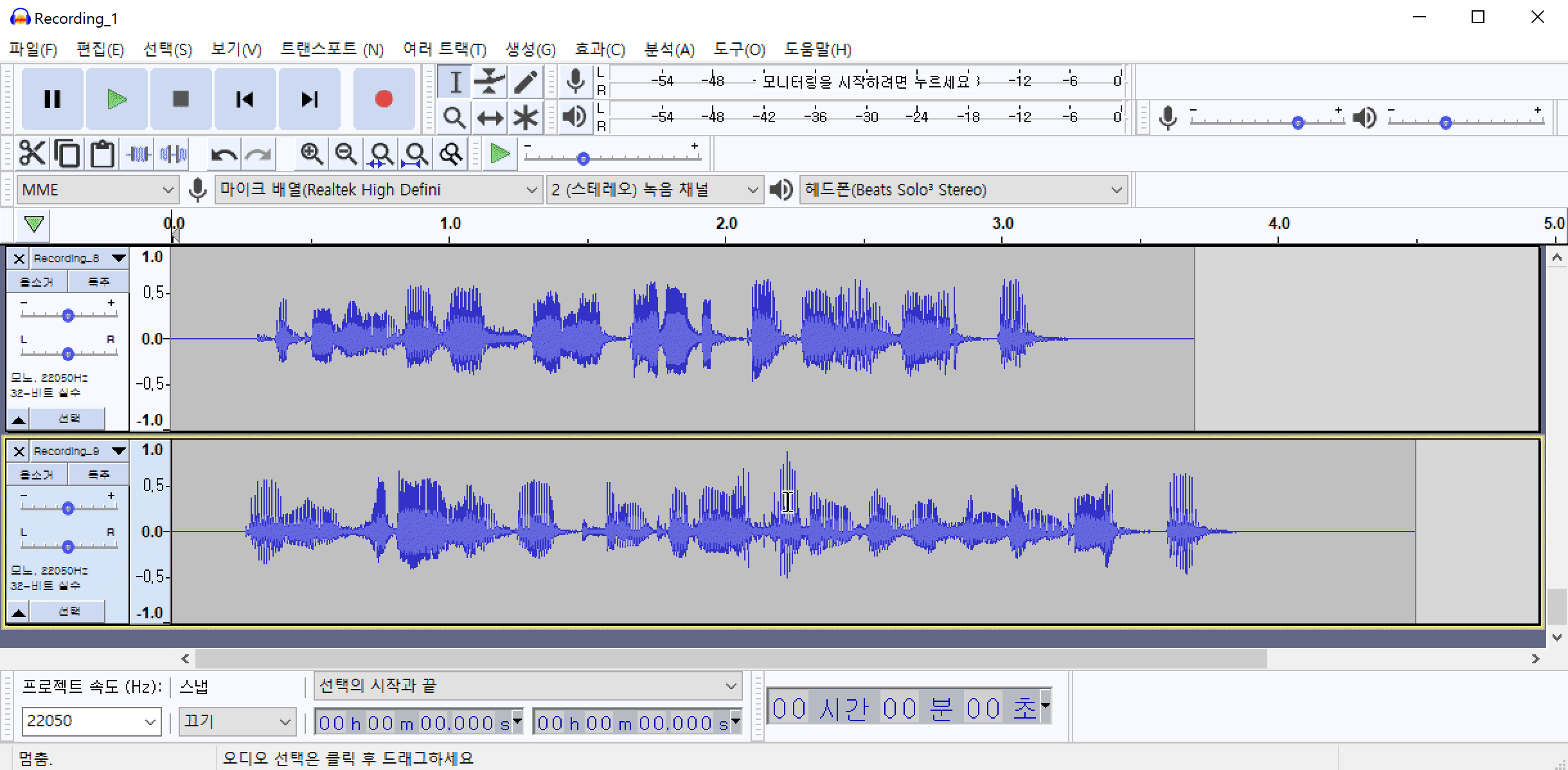
해당 데이터는 최대한 조용한 환경(집)에서 녹음하였기 때문에 겉보기에는 잡음이 전혀 없는 것처럼 보입니다. 하지만 음성이 발화되지 않는 부분만 선택하여 들어보면 잡음(소음)이 들리는 것을 확인할 수 있습니다. 여러개의 파일을 불러온 상태에서 특정 음성만 듣기 위해서는 특정음성의 왼쪽에 위치한 독주 버튼을 클릭하고 마우스를 드래그하여 음성의 일부분을 선택한 다음 재생 버튼을 클릭합니다.
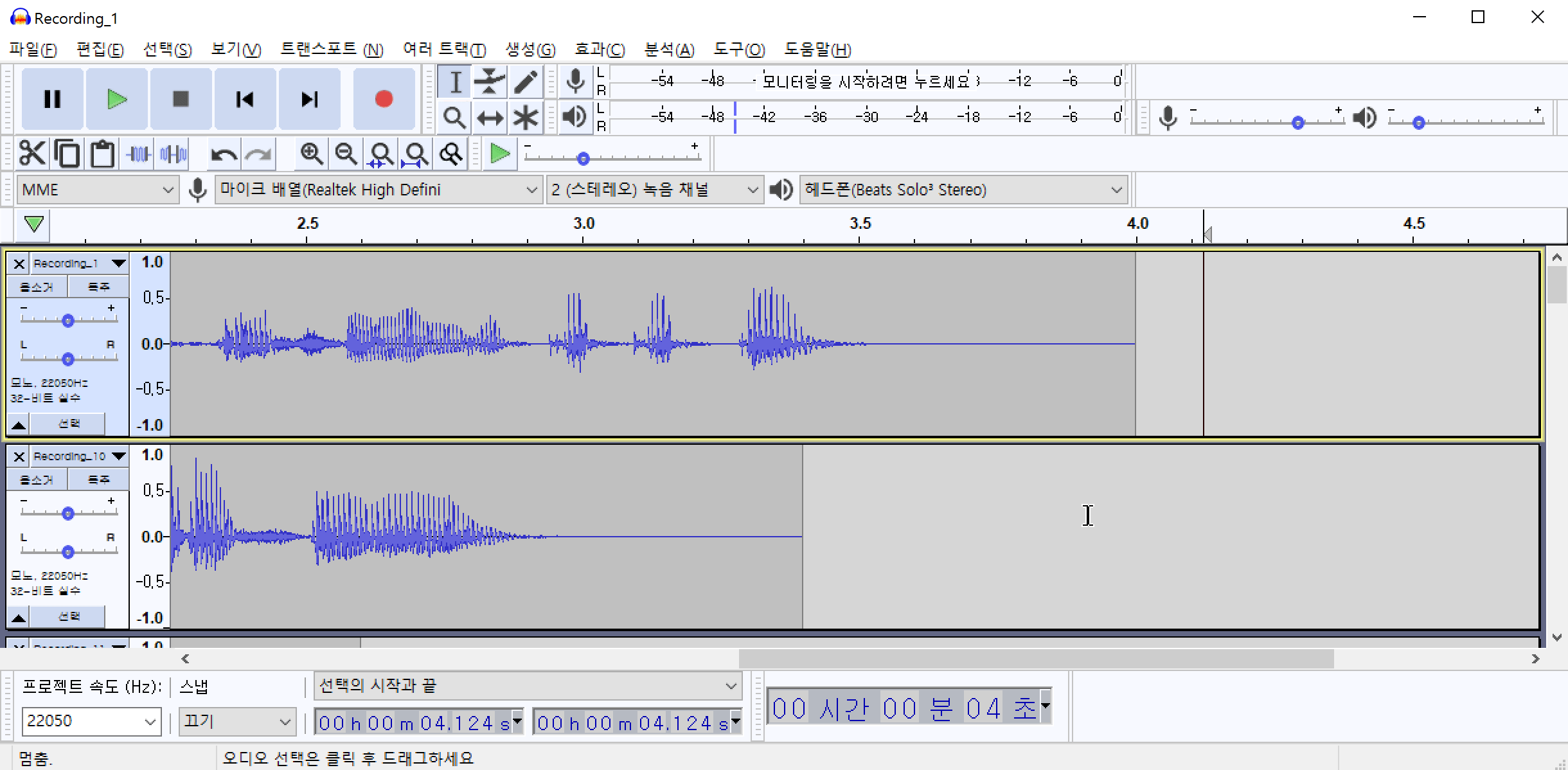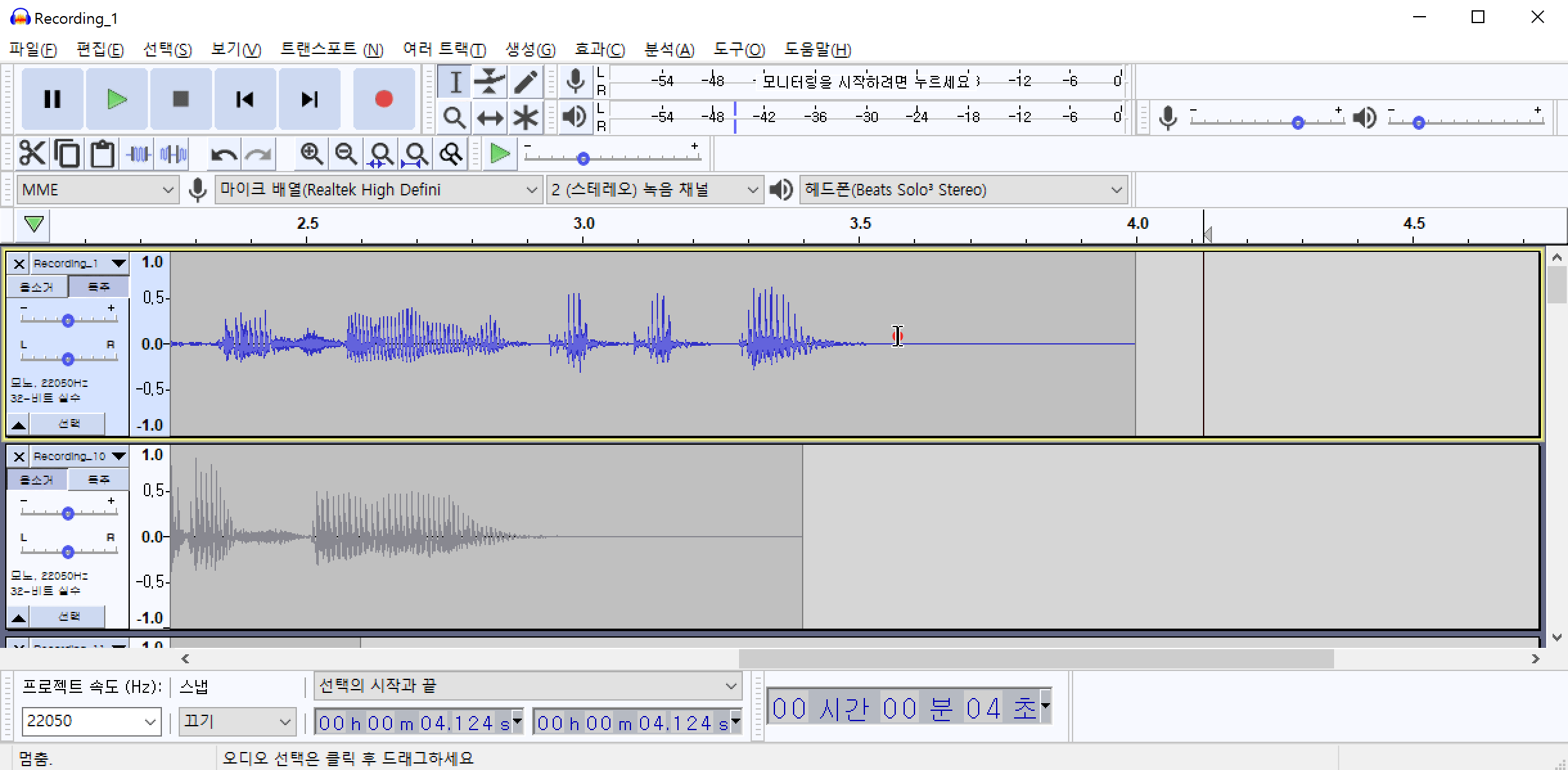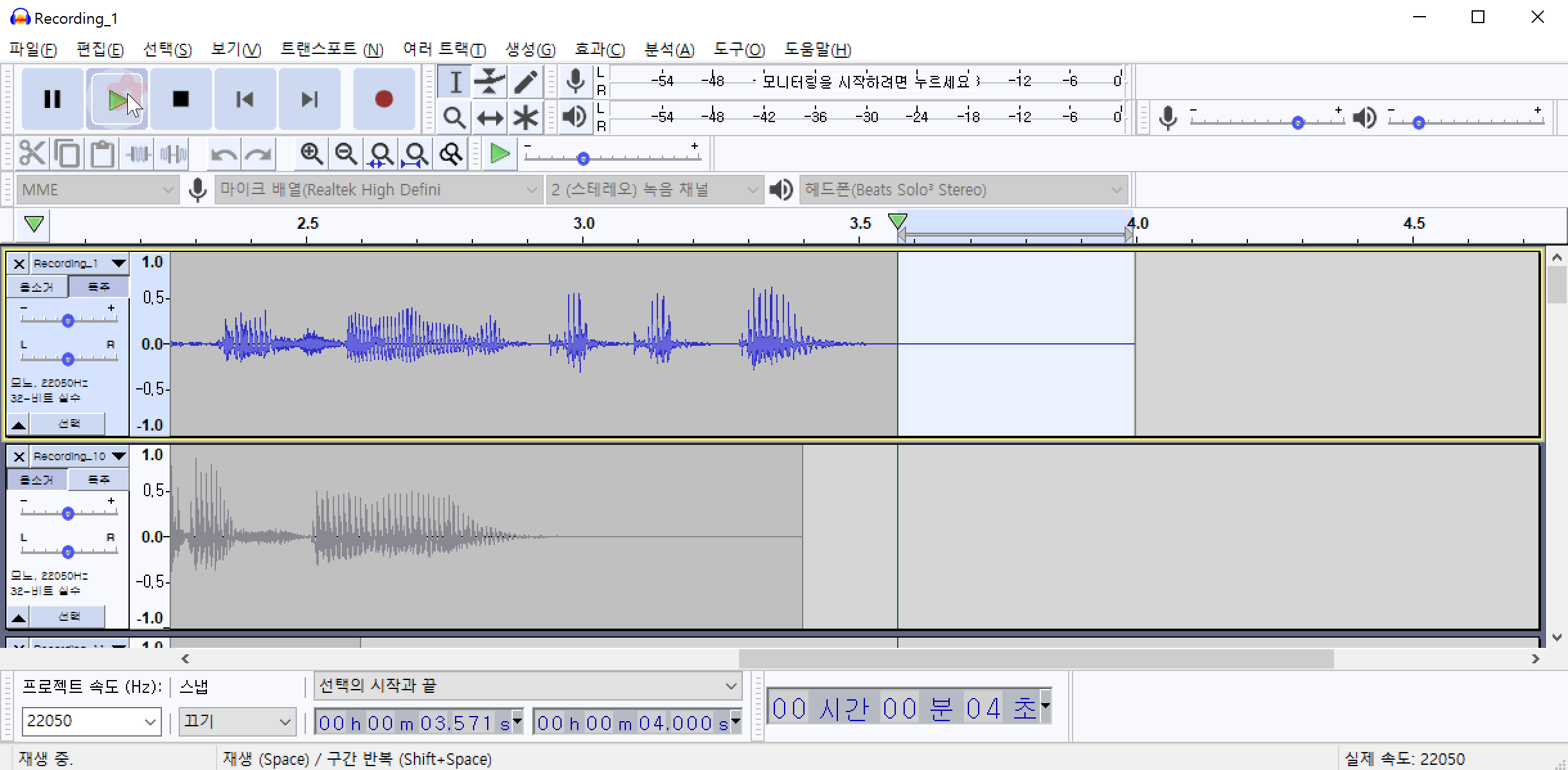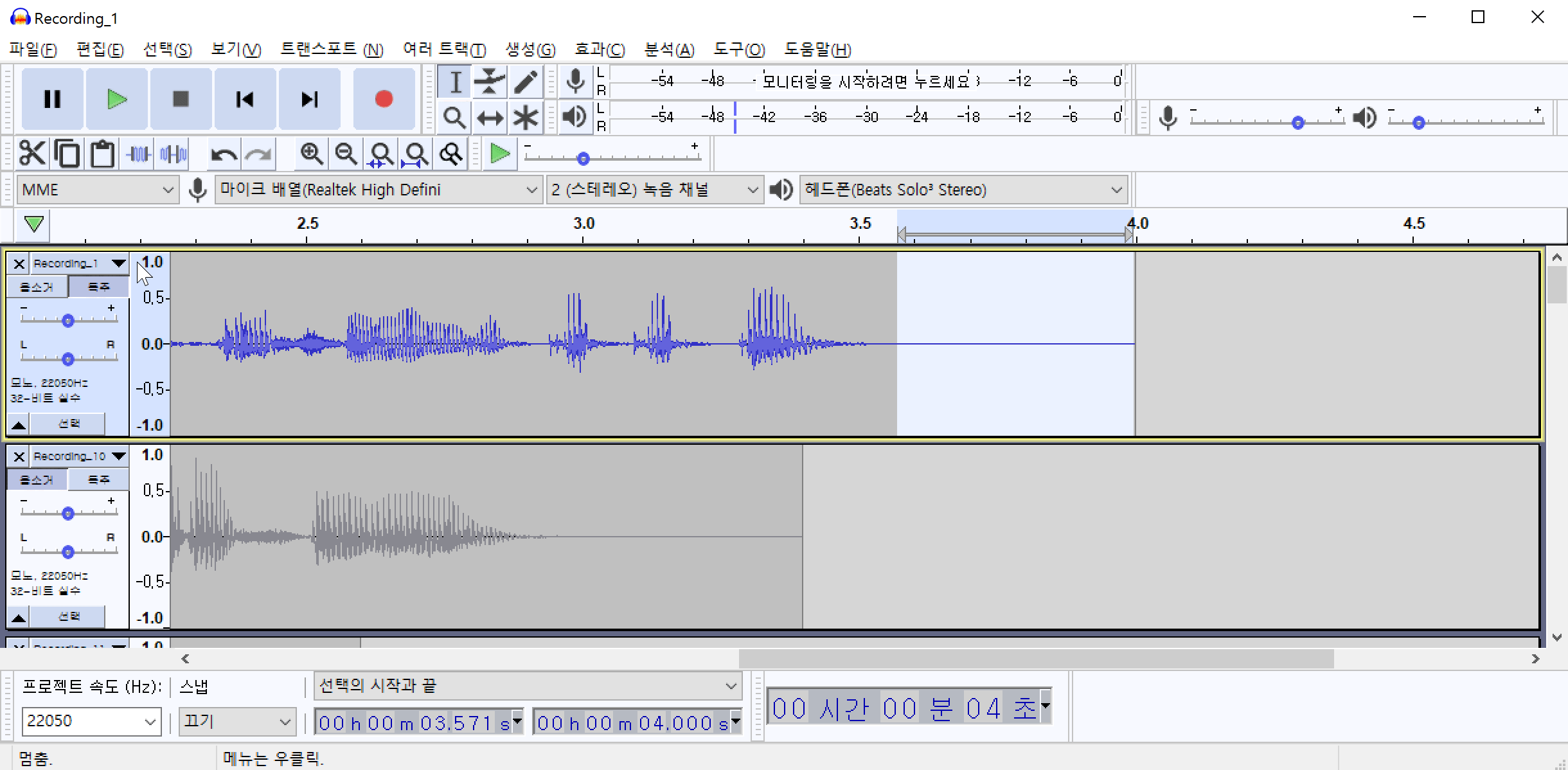
/img/in-post/2021/2021-04-01/noise_sample.wav
이 소음은 녹음기 주변 공기의 압력변화에 때문에 발생하는 백색소음(어쩔 수 없는) 일 가능성도 있고, 실제 환경에 소음이 있을 가능성도 있습니다. 이 소음을 제거하기 위하여 해당 위치의 음성 패턴을 추출해야 합니다. 먼저 노이즈(백색소음)가 발생한 부분을 드래그 하여 영역을 지정합니다. 그 다음 메뉴에서 효과(C)->노이즈 리덕션(잡음 감쇄)->노이즈 프로파일 구하기 를 차례로 클릭하여 노이즈 패턴을 추출합니다.
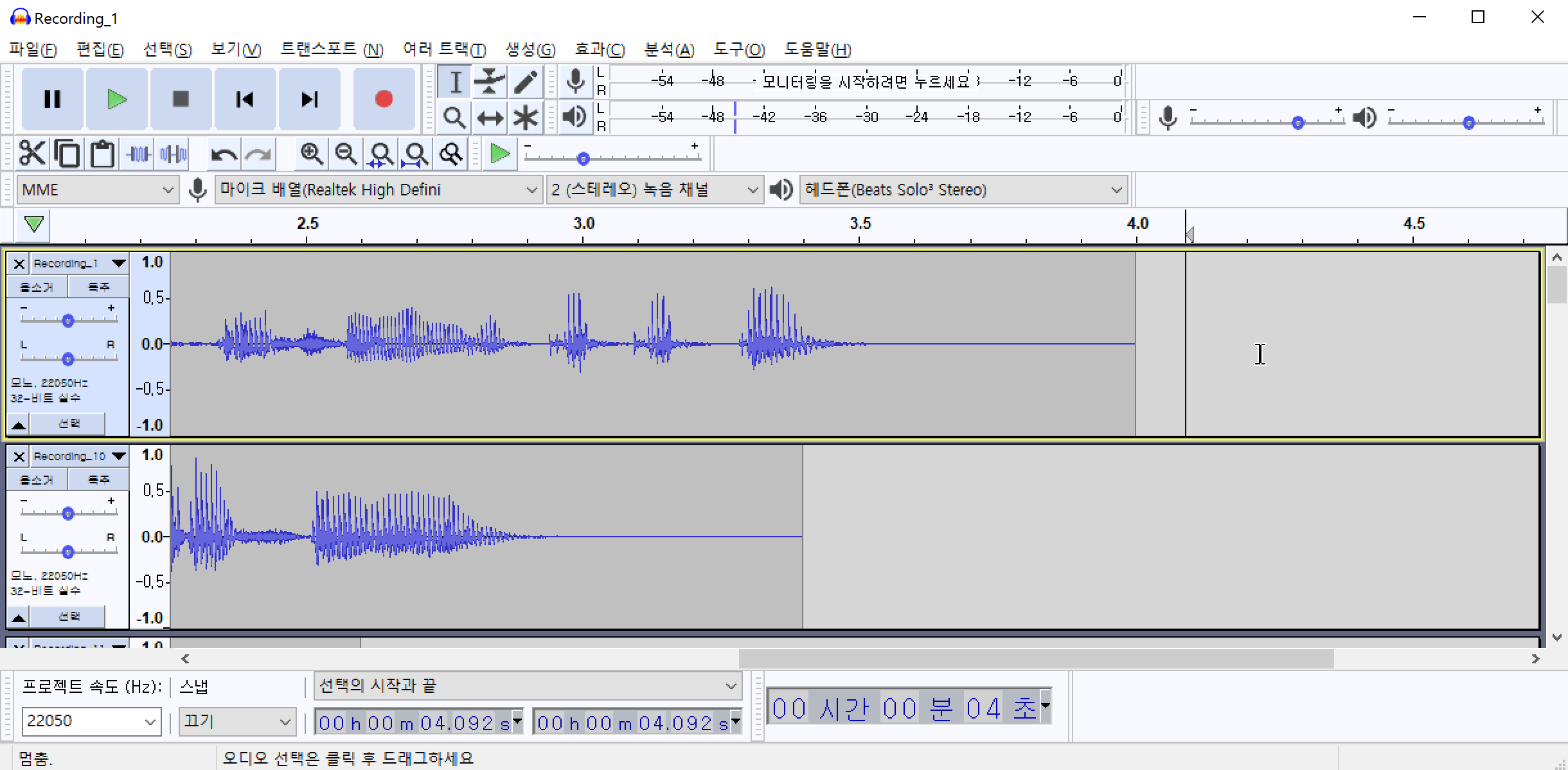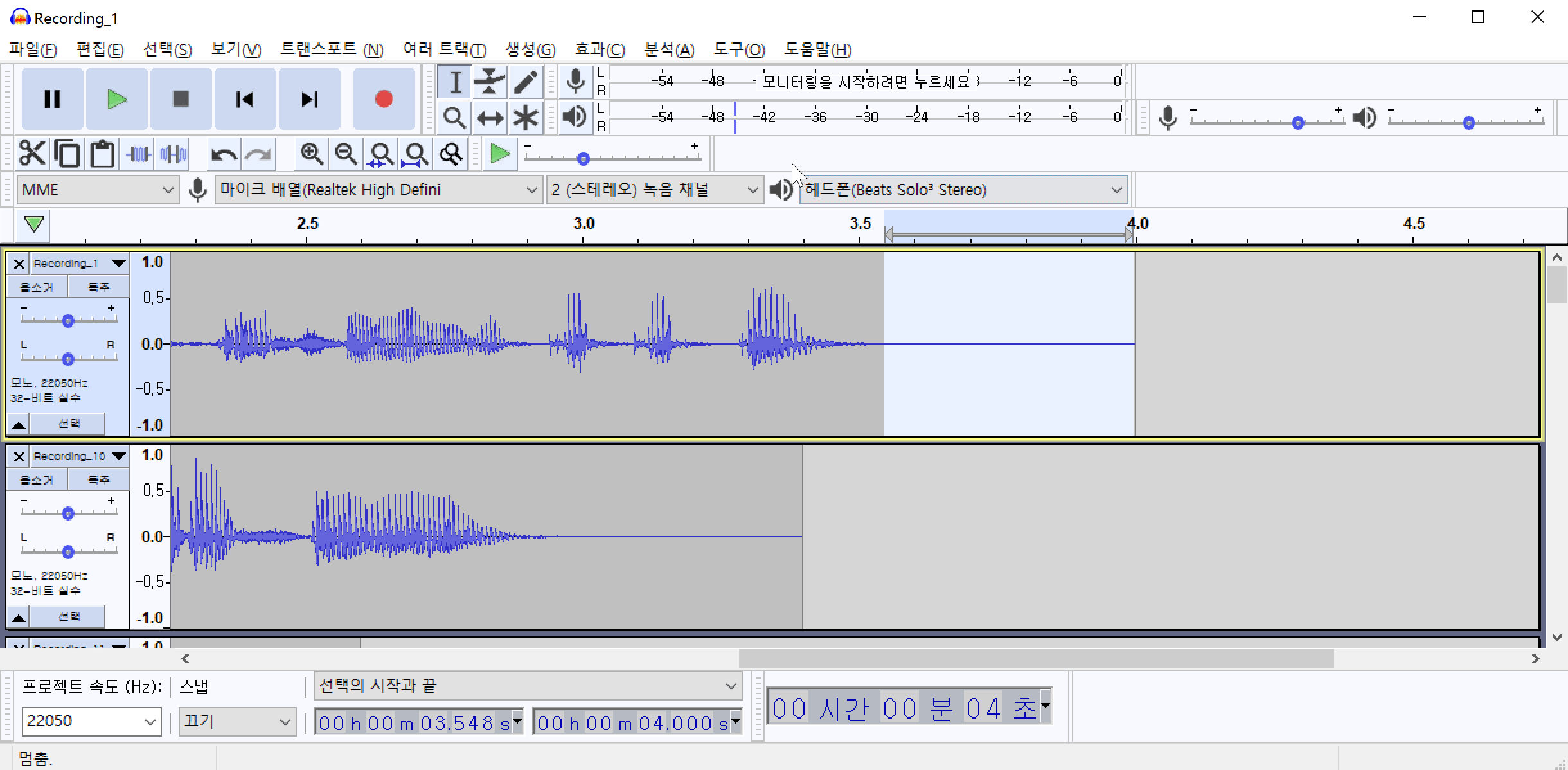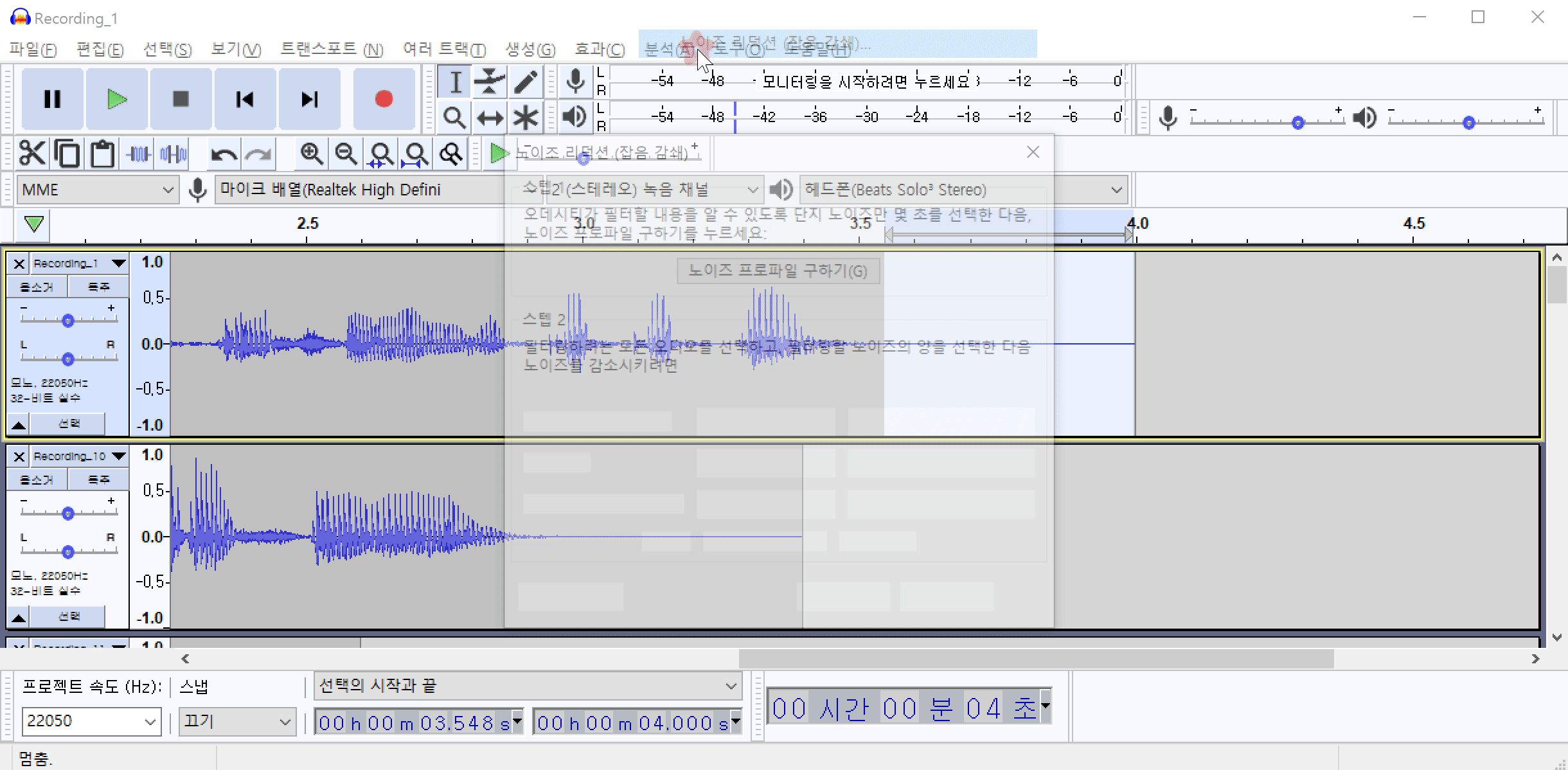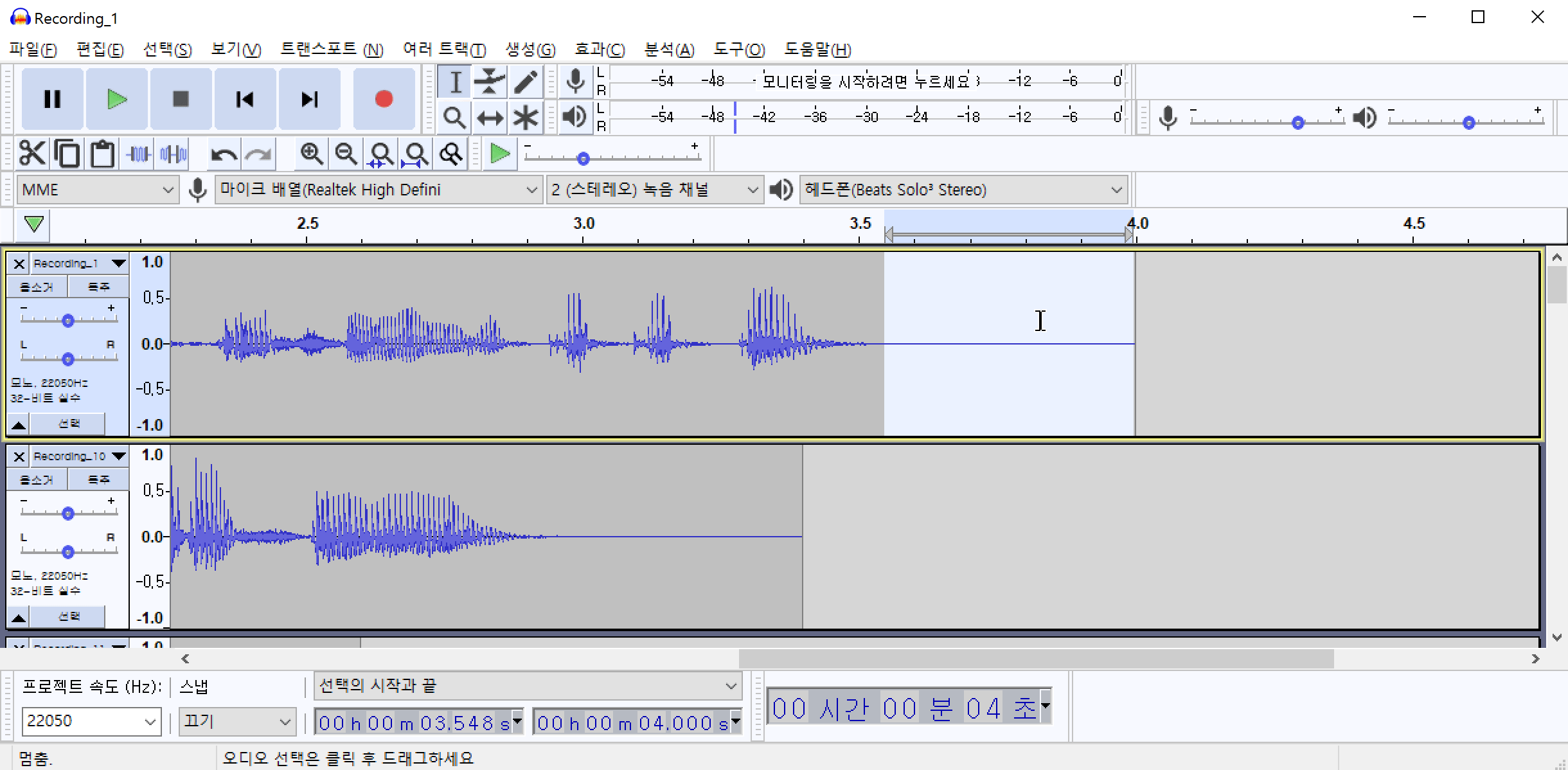
노이즈 패턴을 추출했으면 추출된 패턴을 모든 파일에 적용하여야 합니다. Ctrl+A 를 눌러서 전체 파일을 선택합니다. 그리고 다시 효과(C)->노이즈 리덕션(잡음 감쇄)->확인 버튼을 차례로 클릭하여 전체 파일에 포함된 노이즈를 제거합니다.
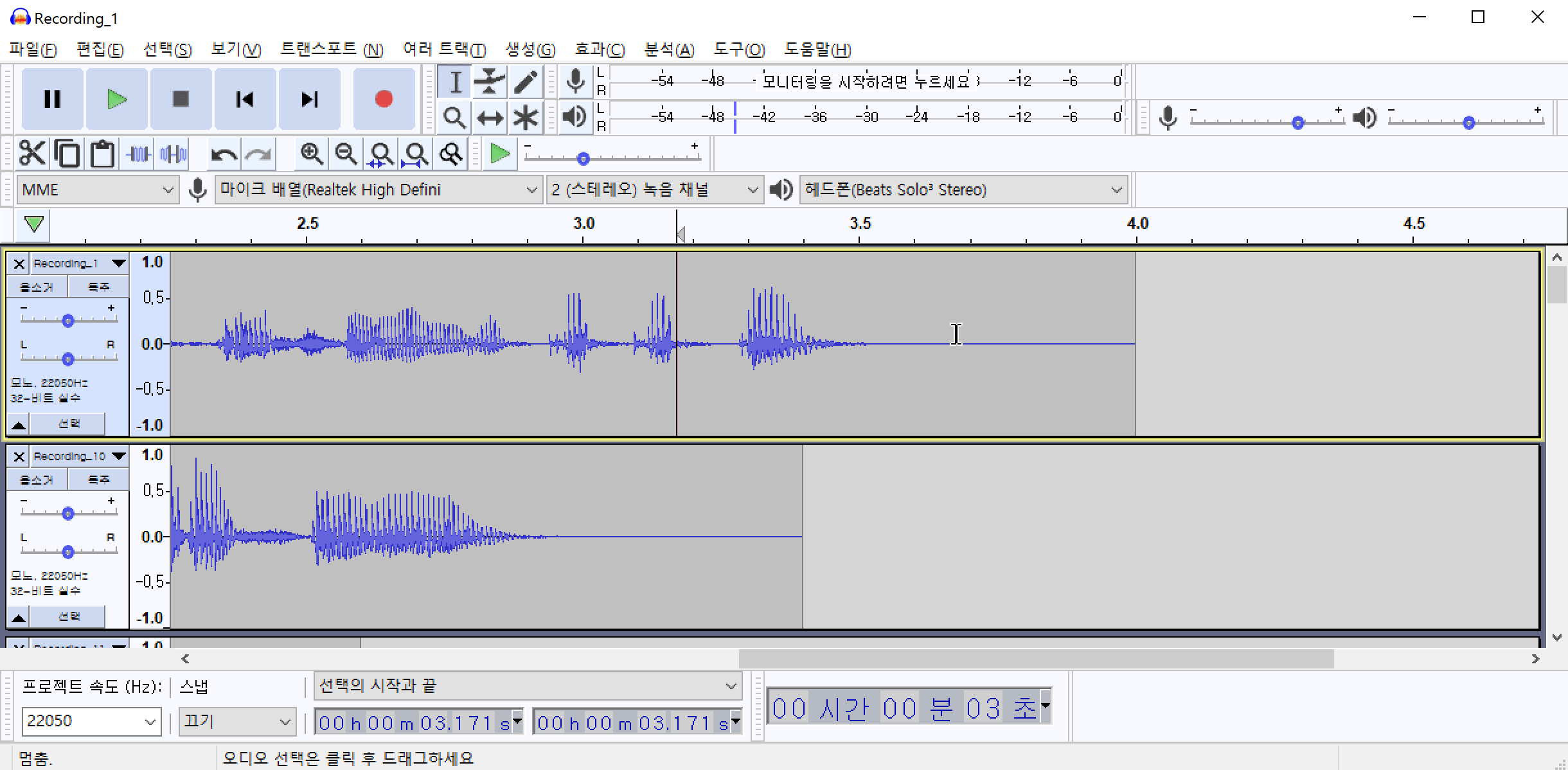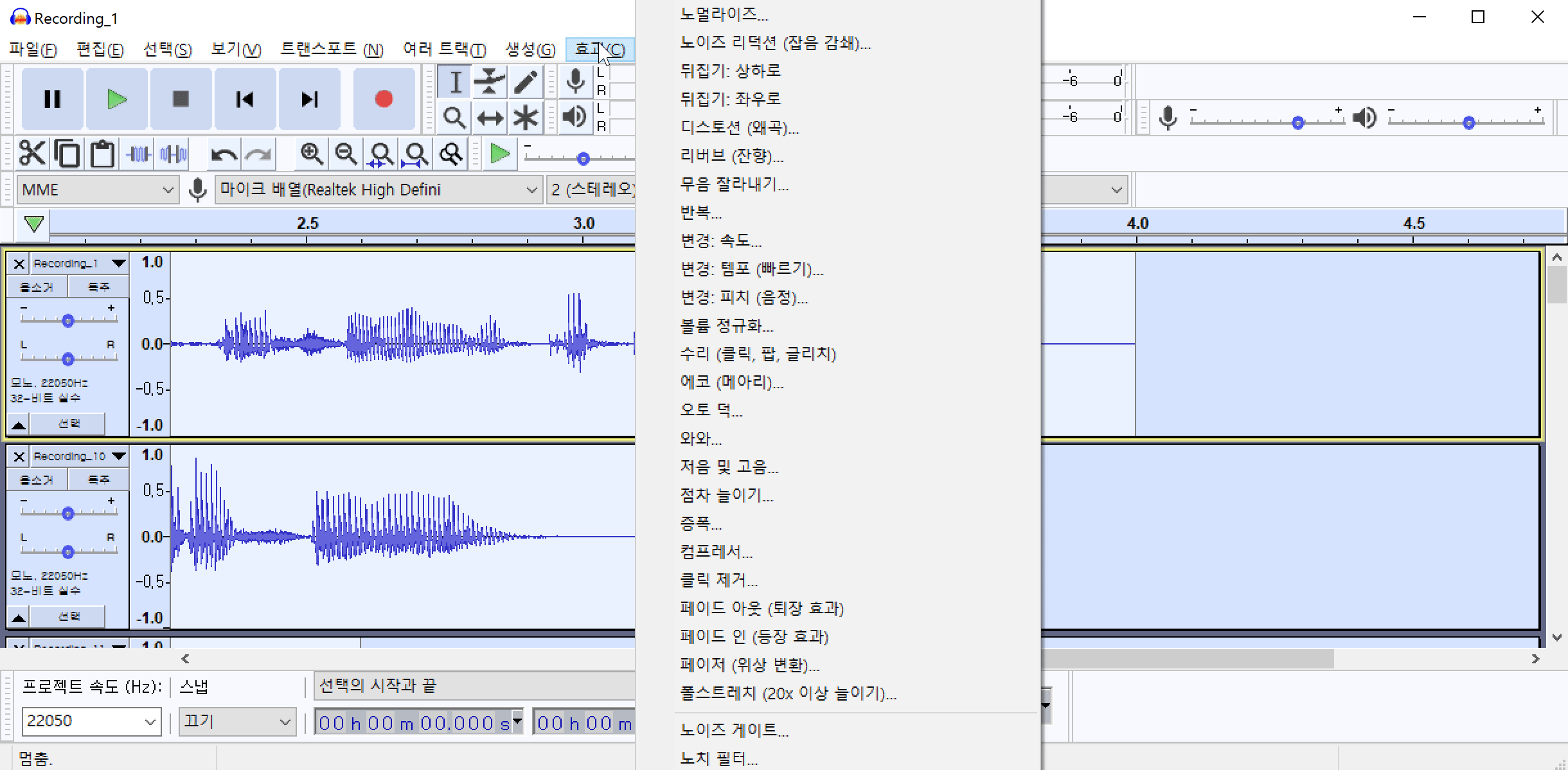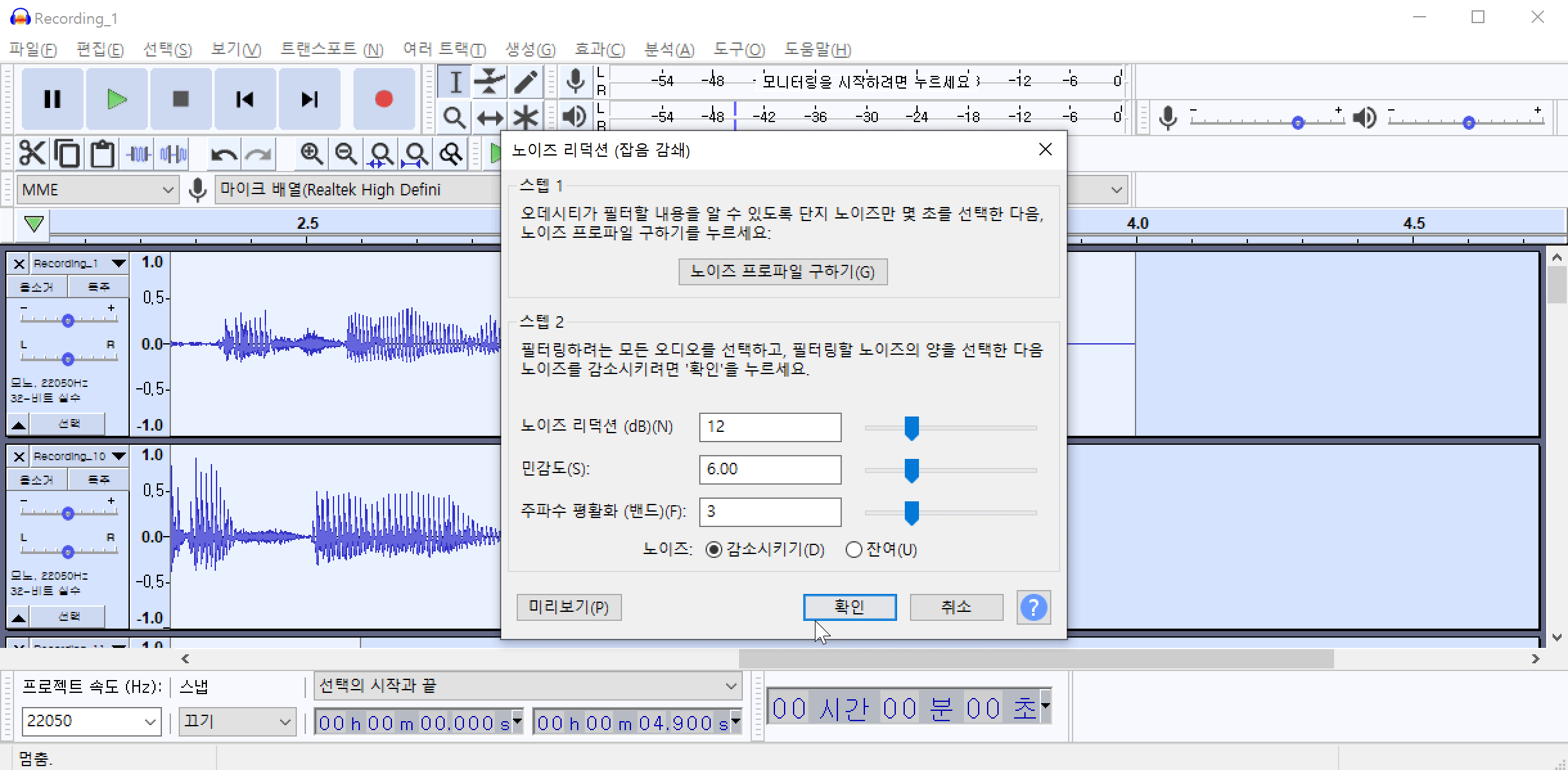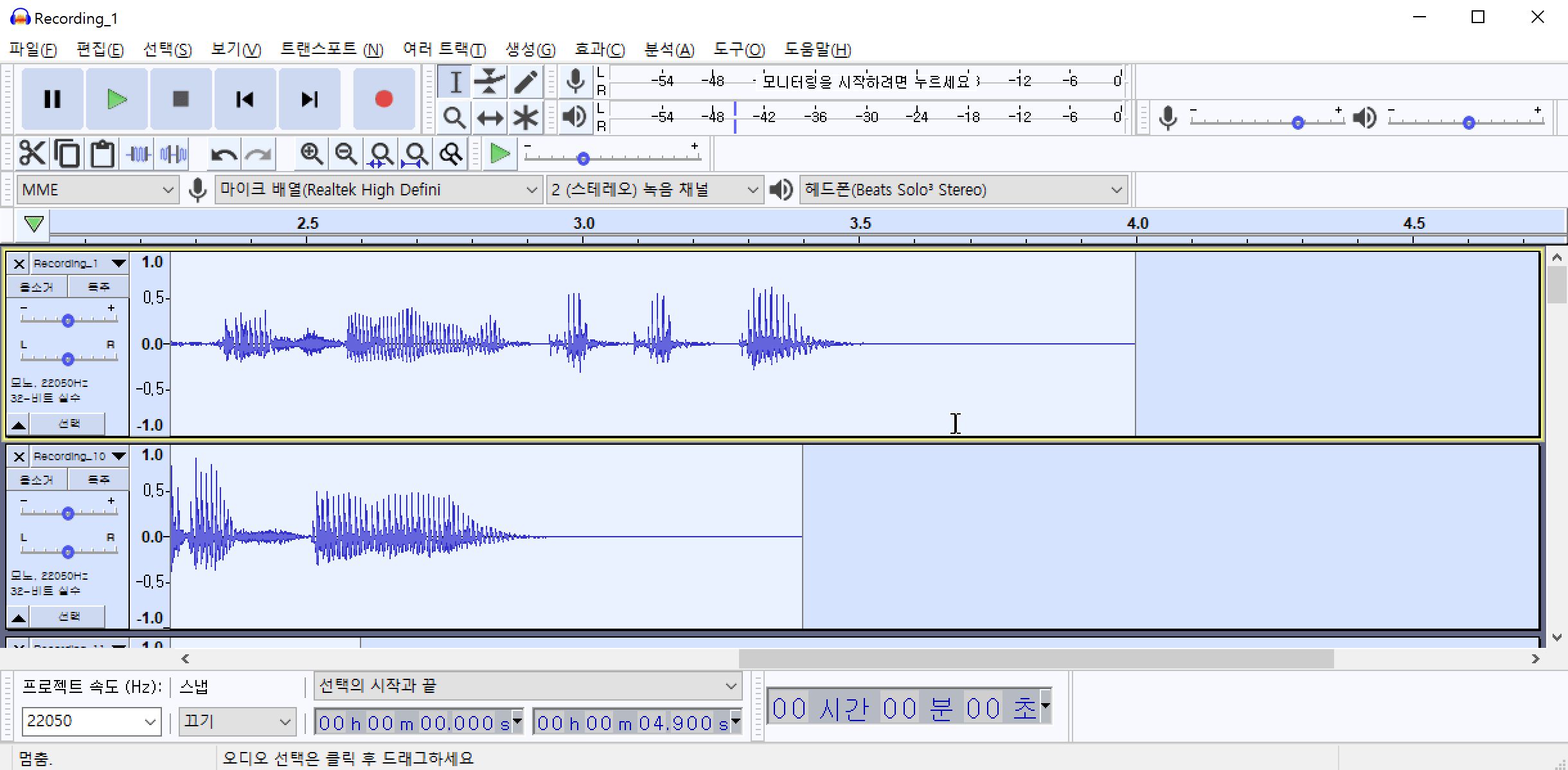
이 과정을 통해 제거되지 않은 노이즈가 존재할 수 있습니다. 노이즈 패턴 추출, 노이즈 제거 과정을 반복하면 음성에 남아있는 노이즈를 제거할 수 있습니다.
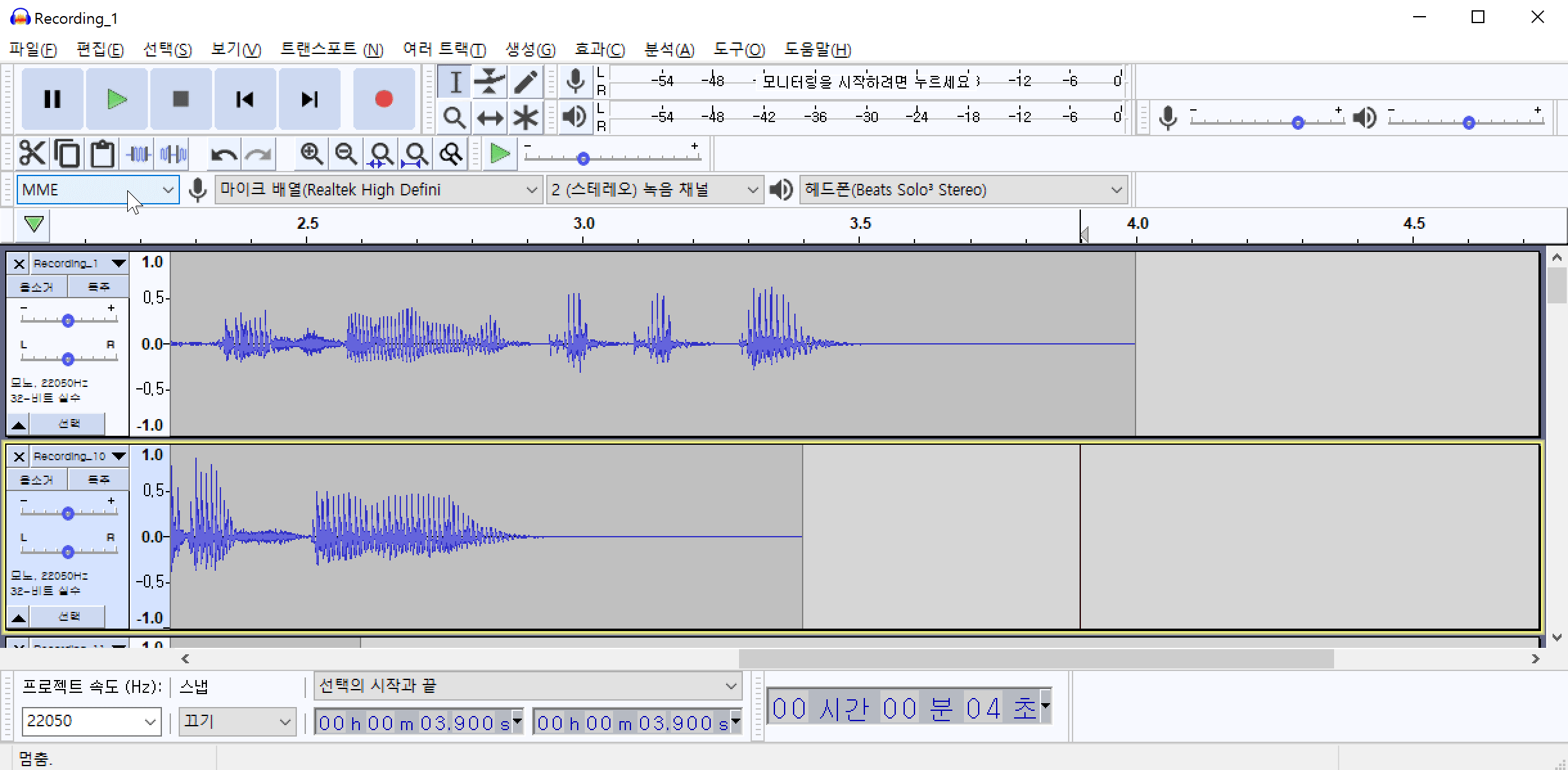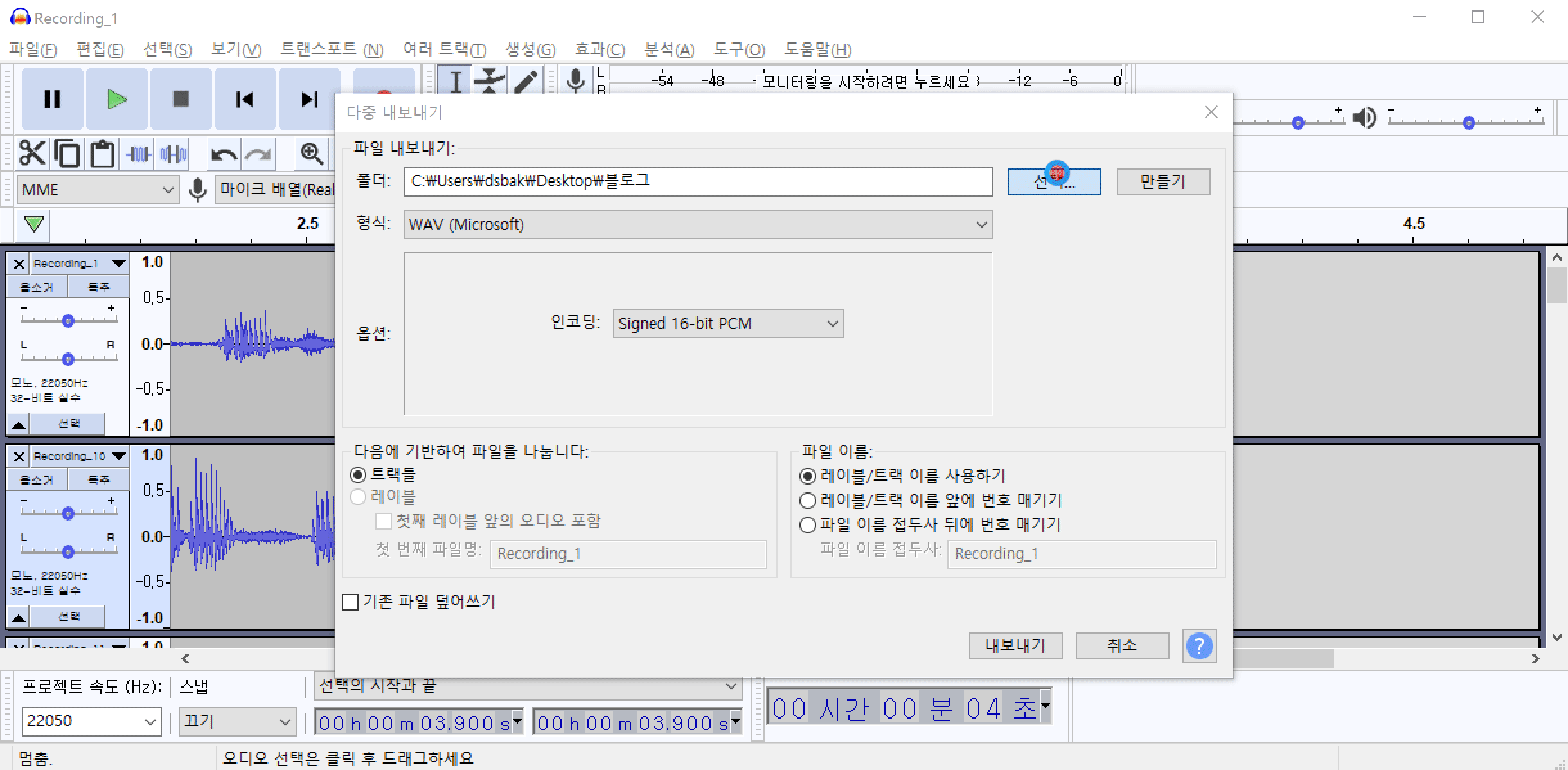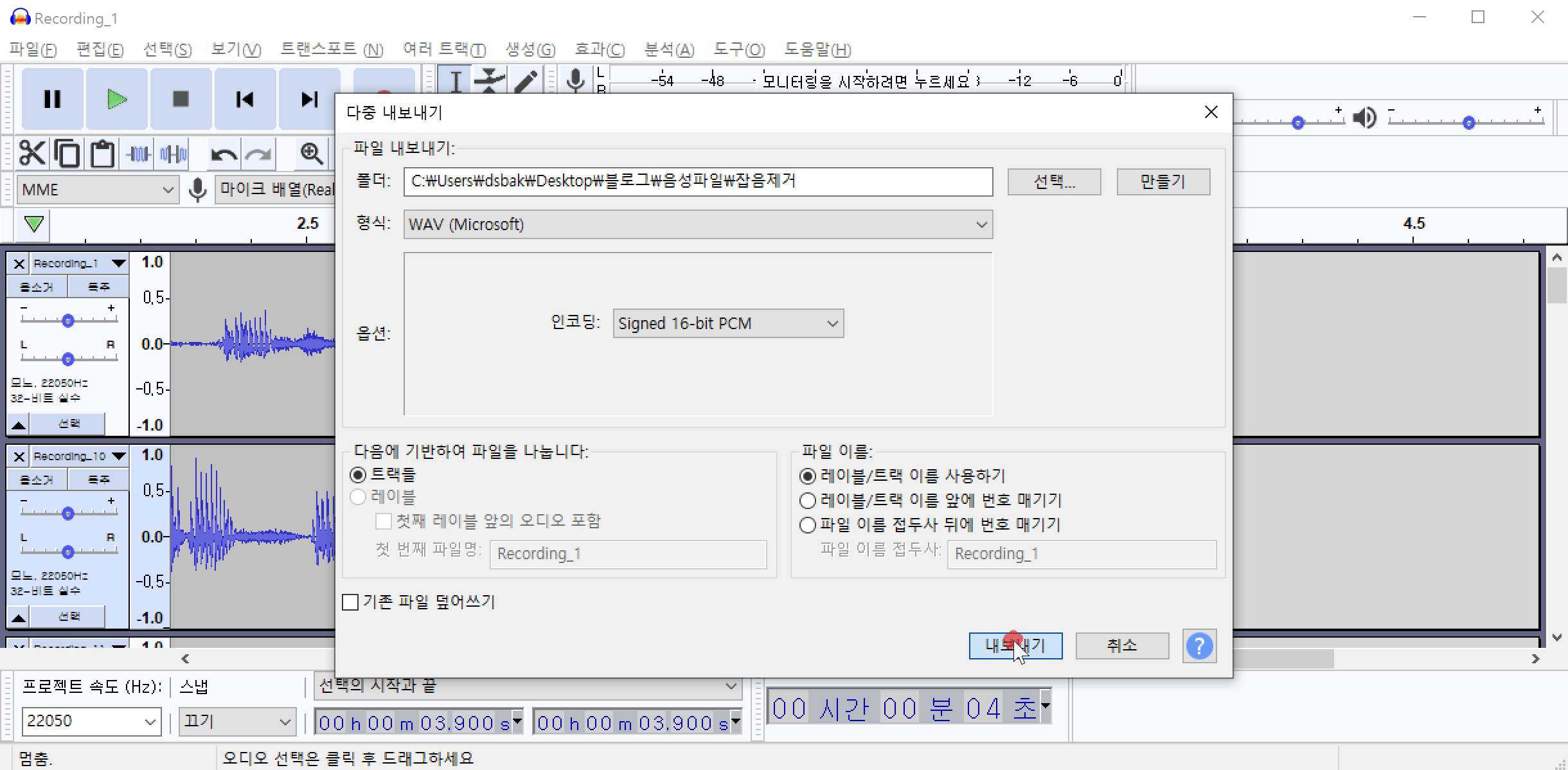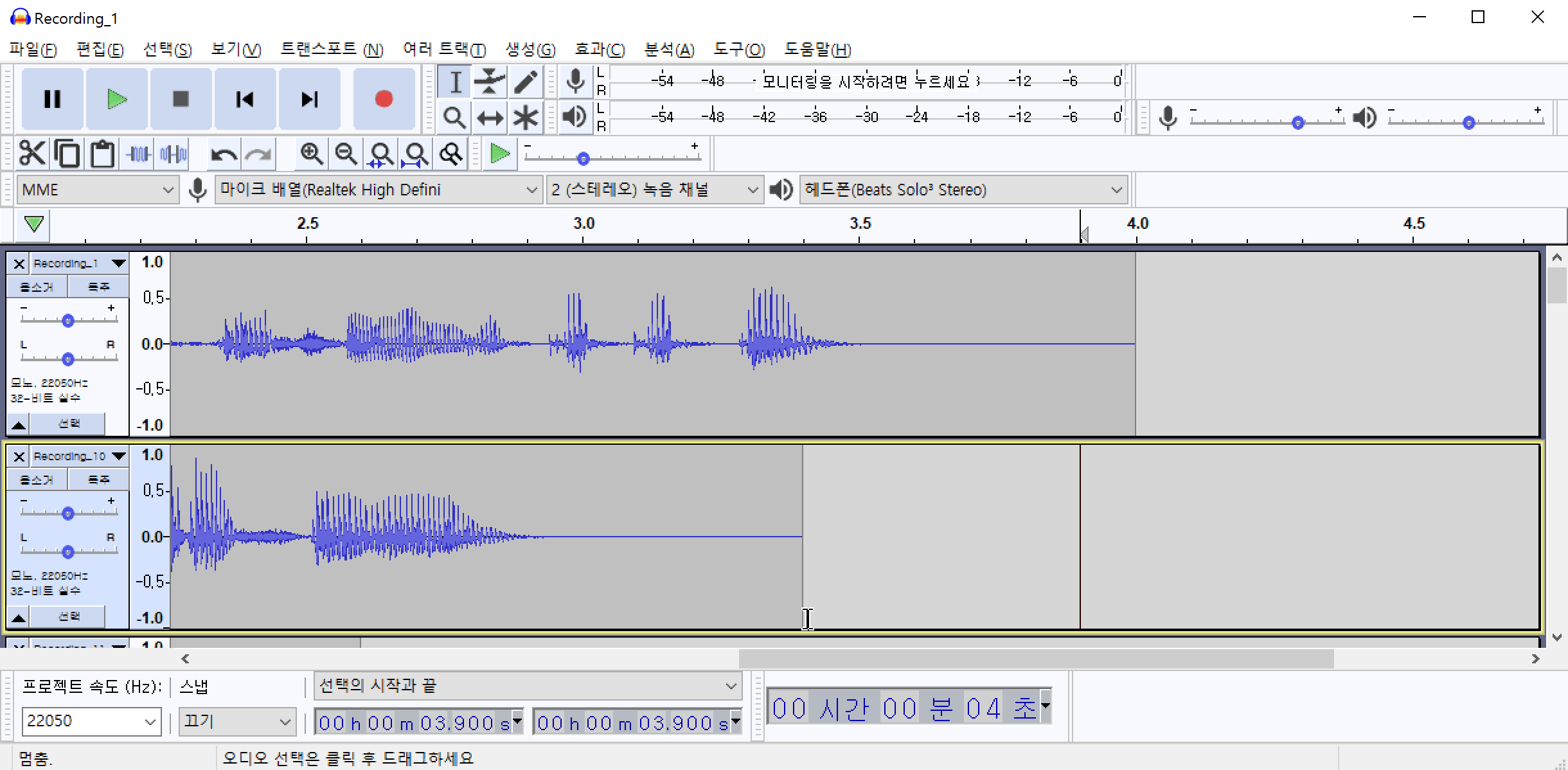
다음은 모든 노이즈가 제거된 파일을 한꺼번에 저장하는 방법에 대해서 알아보겠습니다. 메뉴에서 파일(F)->내보내기(E)->다중 내보내기(M)를 클릭합니다. 다중 내보내기 옵션에서 파일들을 저장할 폴더를 선택하고 내보내기를 클릭하면 현재 노이즈가 제거된 모든 파일을 한꺼번에 저장할 수 있습니다.
Step2.2 공백 자르기 & Sampling Rate 변경
공백을 제거하고 앞 뒤로 일정한 공백을 추가하는 코드입니다. 코드 안에 Sampling Rate를 변경하여 저장하는 기능이 포함되어 있습니다. Jupyter Notebbook 파일로 해당 작업이 가능하도록 코딩한 예시는 아래와 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
## 라이브러리 Import
import numpy as np
import os
from tqdm.notebook import tqdm
import librosa
from pathlib import Path
import matplotlib.pyplot as plt
import IPython.display as ipd
import glob
import soundfile as sf
## 함수 설정
## 파일 읽어오기(지정한 Sampling Rate로)
def load_audio(file_path, sr=22050):
"""
file_path : 파일위치
sr : 오디오를 읽을 때 Sampling rate 지정
"""
## 확장자 추출
ext = Path(file_path).suffix
## 파일 읽기
if ext in ['.wav', '.flac']:
wav, sr = librosa.load(file_path, sr=sr)
elif ext == '.pcm':
wav = np.memmap(file_path, dtype='h', mode='r').astype('float32') / 32767
elif ext in ['.raw', '.RAW']:
wav, sr = sf.read(file_path, channels=1, samlerate=sr, format='RAW', subtype='PCM_16')
else:
raise ValueError("Unsupported preprocess method : {0}".format(ext))
return wav, sr
## 공백 자르기(패딩 추가)
def trim_audio(wav, top_db=10, pad_len=4000):
"""
"""
## 최대 db에 따라 음성의 자를 위치 판별
non_silence_indices = librosa.effects.split(wav, top_db=top_db)
start = non_silence_indices[0][0]
end = non_silence_indices[-1][1]
## 음성 자르기
wav = wav[start:end]
## padding 추가
wav = np.hstack([np.zeros(pad_len), wav, np.zeros(pad_len)])
return wav
## WAV 그려보기
def plot_wav(wav, sr):
## 그려보기
plt.figure(1)
plot_a = plt.subplot(211)
plot_a.plot(wav)
plot_a.set_xlabel('sample rate * time')
plot_a.set_ylabel('energy')
plot_b = plt.subplot(212)
plot_b.specgram(wav, NFFT=1024, Fs=sr, noverlap=900)
plot_b.set_xlabel('Time')
plot_b.set_ylabel('Frequency')
plt.show()
## 시작하기
## 타코트론2는 기본적으로 22050 sampling rate에서 동작
sampling_rate = 22050
## 개인설정에 따라 특정 소리보다 작은 음성을 삭제하도록 설정
decibel=10
## Wav 파일 읽어오기 pcm 또는 다른 확장자도 사용 가능.
root_path = '잡음제거'
file_list = glob.glob(os.path.join(root_path, "*.wav"))
#file_list = glob.glob(os.path.join(root_path, "*.pcm"))
## 저장할 위치 선택
save_path = 'temp'
os.makedirs(save_path, exist_ok=True)
for file_path in tqdm(file_list):
## 파일 불러오기(타코트론2는 기본적으로 22050 sampling rate에서 동작)
wav, sr = load_audio(file_path, sr=sampling_rate)
## 오디오 자르기(패딩 추가)
trimed_wav= trim_audio(wav, top_db=decibel)
filename=Path(file_path).name
temp_save_path = os.path.join(save_path, filename)
## 저장하기
sf.write(temp_save_path, trimed_wav, sampling_rate)
앞 뒤 공백을 제거한다고 적었지만 음성 데이터에서 0인 값은 거의 없습니다. 즉 아주 작은 소리가 담겨 있는데 그 음성은 백색소음(white noise)으로 볼 수 있습니다. 이를 제거하기 위해서는 decibel 등의 기준을 만들고 그 기준에 따라 특정 크기 이하의 소리를 백색 소음으로 지정한 뒤 삭제해야 합니다.
해당 코드는 librosa에서 제공하는 기능을 활용하여 특정 decibel 이하의 소리를 앞 뒤로 제거하도록 구성하였습니다.
백색소음의 크기(decibel)은 음성을 녹음한 환경에 따라 다르므로 직접 몇가지 테스트를 해서 정해야 합니다.
코드를 이용하기 전과 후의 결과를 시각화 한 후 코드의 효과를 말씀드리겠습니다.
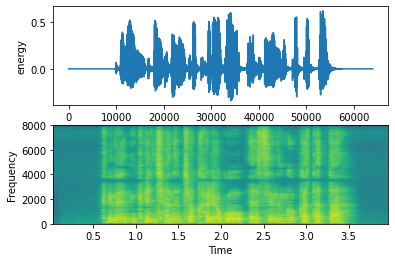
Trim을 사용하기 전 음성은 앞 뒤로 공백이 있는 것을 확인 할 수 있습니다. 또한 앞 뒤의 공백 크기가 일정하지 않은 것을 볼 수 있습니다.
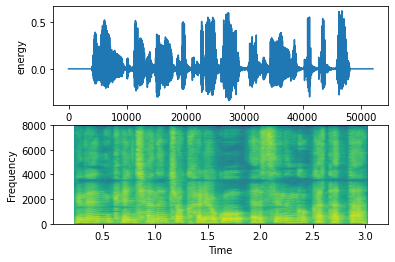
위 코드를 사용한 후 비교적 공백의 길이가 짧아졌고, 앞뒤 공백의 길이가 일정한 것을 확인 할 수 있습니다.
해당 코드에는 음성을 불러올 때 특정 Sampling Rate를 지정하도록 되어 있습니다. 그리고 공백을 제거한 후 지정한 Sampling Rate로 저장하도록 작성되어 있으므로 저장된 음성의 Sampling Rate는 원본의 Sampling Rate와 다를 수 있다는 것을 참고바랍니다.
위 코드와 관련된 파일은 Jupyter Notebook 링크 를 눌러 다운받으실 수 있습니다.