[코드리뷰] - 타코트론2 TTS 시스템 2/2
지난 글에서는 TTS 시스템을 개발하기 위하여 데이터를 전처리하는 방법에 대해서 다루었습니다. 이번 글에서는 전처리된 데이터를 활용하여 Tacotron2 모델과 WaveGlow 모델을 학습시키는 방법에 대해서 말씀드리도록 하겠습니다.
딥러닝 아키텍처(타코트론2)에 대해 궁금하신 분이 계시다면 이전 글 또는 세미나 영상 을 참조하시기 바랍니다.
TTS 시스템을 개발하기 위하여 어떤 모델을 선택하느냐에 따라 내부 구성요소들이 크게 달라질 수 있습니다. 이 글처럼 Tacotron2를 활용하여 TTS 시스템을 구성할 때에는 Vocoder가 필요합니다. Vocoder는 Tacotron2를 통해 추출된 Mel-Specotrogram 또는 Spectrogram을 음성(Raw Audio)로 변환하는 프로그램을 의미합니다. 이 글에서는 WavGlow를 Vocoder로 활용하는 방법에 대해서 다루도록 하겠습니다.

Short Summary
개인화 TTS 시스템을 만드는 과정을 크게 나누면 아래와 같습니다.
- 데이터 수집
- 음성 데이터 전처리
- 스크립트 전처리
- Tacotron2 모델 학습
- WaveGlow 모델 학습
4. Tacotron2 모델
TTS 시스템을 만들기 위해 다양한 모델을 선택할 수 있지만 이 글에서는 Tacotron2 모델을 활용하는 방법에 대해 다루고 있습니다. Tacotron2 모델을 직접 개발하는 것도 좋지만 현재 개발되어 공개저장소(github)에 공개된 프로그램을 활용하는 것이 더 빠르고 신뢰성 있는 모델을 개발할 수 있는 방법입니다. 대부분 영어만 지원하지만 한글 프로그램도 존재합니다.
Github에 공개된 유용한 프로그램을 알아보겠습니다.
[1] Tacotron2-Wavenet-Korean-TTS(Pytorch)
hccho2님께서 개발하신 Tacoton2(한글 지원) 모델입니다.
다중화자를 지원할 수 있도록 기본 Taconton2 모델을 변경하였으며, Vocoder로 Wavenet을 구현하여 제공하고 있습니다.
개발된 모델에서 성능을 간접적으로 평가할 수 있는 샘플로 손석희 아나운서와 문재인 대통령의 음성을 제공하고 있는데, 매우 깔끔하게 음성이 생성된 것을 확인할 수 있습니다.
Pytorch로 개발되었기 때문에 Pytorch에 익숙한 유저분들에게 추천드립니다.
[2] Multi-Speaker-Tacotron(Tensorflow)
carpedm20님께서 개발하신 Tacotron(한글 지원) 모델입니다. 다중화자를 지원할 수 있도록 Tacotron 모델을 변경하였으며, 개발을 간편하게 할 수 있도록 프로그램을 잘 정리한 것이 특징입니다.
DEVIEW 2017 에서 해당 내용을 발표하였으니 영상도 함께 참고하시기 바랍니다.
pre-trained Model Checkpoint를 함께 제공하고 있기 때문에 Checkpoint를 Base로 Transfer Learning하여 모델을 빠르게 학습시킬 수 있습니다.
Tensorflow로 개발되었기 때문에 Tensorflow에 익숙한 유저분들께 추천드립니다.
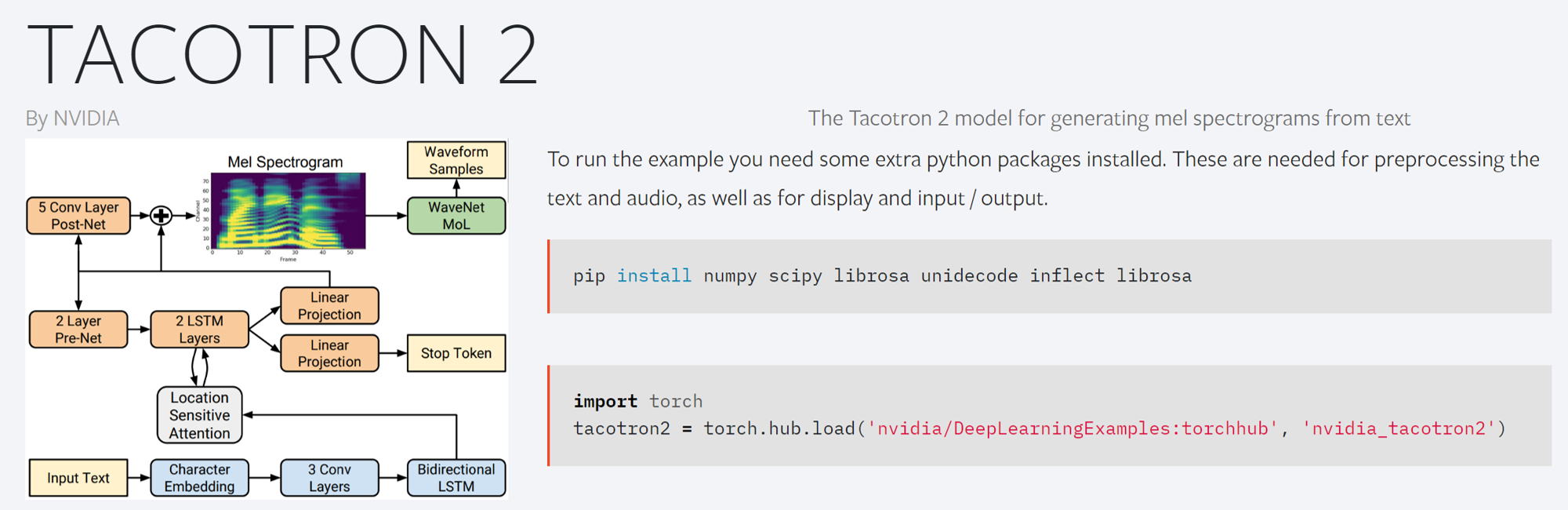
[3] Nvidia-Tacotron2(Pytorch)
영어만 지원하는 Tacotron2 모델입니다. NVIDIA에서 만들었기 때문에 Apex, AMP 등을 지원하도록 프로그램을 구성하였습니다.
따라서 비교적 빠른 속도로 모델을 학습할 수 있으며 사용하기 간편합니다. 영어 Checkpoint(학습된 모델)을 제공하고 있으므로 영어 데모를 테스트해보기 간편합니다.
torch hub를 이용하여 모델을 간단하게 활용하는 방법에 대해 리뷰를 제공하는 블로그 글 이 있으니 해당글을 참고하시면 프로그램을 이해하기 더 수월합니다.
5. WaveGlow 모델
WaveGlow는 Glow와 WaveNet의 아이디어를 합쳐 만든 Vocoder입니다. AutoRegression 형태의 아키텍처를 사용하지 않기 때문에 WaveNet보다 빠른 속도로 고품질의 음성을 합성할 수 있으며, 간단한 Cost Function을 구성(Glow Idea)하여 빠르고 안정적이게 학습할 수 있다는 장점을 갖고 있습니다. WaveGlow를 통해 생성된 음성은 WaveNet보다는 약간 품질이 떨어질 수 있으나 거의 차이가 없습니다.
Github에 공개된 WaveGlow 리소스가 많지만 이 글에서는 NVIDIA WaveGlow만 소개하겠습니다.
[1] NVIDIA WaveGlow(Pytorch)
NVIDIA에서 공개한 WaveGlow입니다.
Pytorch 기반으로 개발되었으며, 코드 및 사용 설명도 매우 깔끔하게 정리되어 있어 사용하기 간편합니다.
영어데이터 LJ Speech Data 로 개발된 CheckPoint를 제공하고 있습니다.
약 8GB 정도 용량의 GPU를 갖고 있으면 기본 설정된 파라미터로 음성 생성모델을 학습할 수 있습니다.

Tacotron2 모델을 이용하여 학습 예시
Tacotron2를 이용하여 모델을 학습하기 위해 아래 작업이 필요합니다.
- 타코트론2 리소스(코드) 다운
- 학습 정보 파일 생성
- 타코트론2 모델 학습하기
Step4.1 타코트론2 리소스 다운
이 글에서는 NVIDIA에서 제공하는 타코트론2 모델을 활용하여 한국어를 학습하는 방법에 대해 다루고자 합니다.
그 이유는 NVIDIA에서 Tacotron2와 WavGlow를 결합하여 프로그램을 만드는 방법에 대해서 자세히 가이드를 제공하고 있으며, 데모 페이지에 업로드한 샘플 음성이 퍽 인상깊었기 때문입니다. 또한 대부분의 깃허브에서 공유되는 Tacotron2모델은 Wavenet을 Vocoder로 활용하는 방법에 대해서 다루고 있는데, Wavenet 모델은 Auto-Regressive 형태의 모델이기 때문에 학습 및 추론하는데 오랜 시간이 필요합니다. WaveGlow는 Wavenet과 비교하면 매우 빠르기 때문에 활용성 측면에서 WaveGlow를 활용하고자 해당 Github 리소스를 선택하였습니다.
원본 NVIDIA 타코트론2 코드를 Git 관리 프로그램 을 이용하여 다운 받는 방법은 아래와 같습니다.
1
2
## 타코트론2 다운로드
git clone https://github.com/NVIDIA/tacotron2.git
리소스에 도커 파일(Dockerfile)과 설치 항목(requirements.txt)을 포함하고 있으므로 이를 활용하면 학습 환경을 구축할 수 있습니다.
상세한 설치 카이드는 리소스 내 안내파일(read.md) 에서 제공하고 있습니다.
원본 NVIDIA 코드는 한국어를 지원하지 않기 때문에 약간의 코드 수정이 필요합니다. 코드 수정이 필요한 부분은 바로 한국어를 전처리하는 부분입니다. 한국어 전처리에는 숫자, 특수문자, 영어 등을 한글로 변환하는 작업 뿐만아니라 음절로 되어 있는 단위를 음소로 변환하는 작업을 포함합니다. 음소로 변환다는 것을 쉽게 설명하면 초성,중성,종성 으로 한글문자를 잘게 자르는 작업을 의미합니다.

음절은 19개의 자음으로 구성된 초성, 21개의 모음으로 구성된 중성, 27개의 자음으로 구성된 종성으로 이루어져 있습니다. 즉 음소 조합으로 만들 수 있는 음절은 $19 \times 21 \times 27 = 10,773$개 입니다. 따라서 데이터가 충분하지 않다면 학습데이터에 많은 음절들이 누락되기 때문에 새로운 음절에 대해 모델이 대응하지 못하는 현상이 발생합니다. 이를 방지하고자 음소를 기본 입력 단위로 모델을 학습시킵니다.
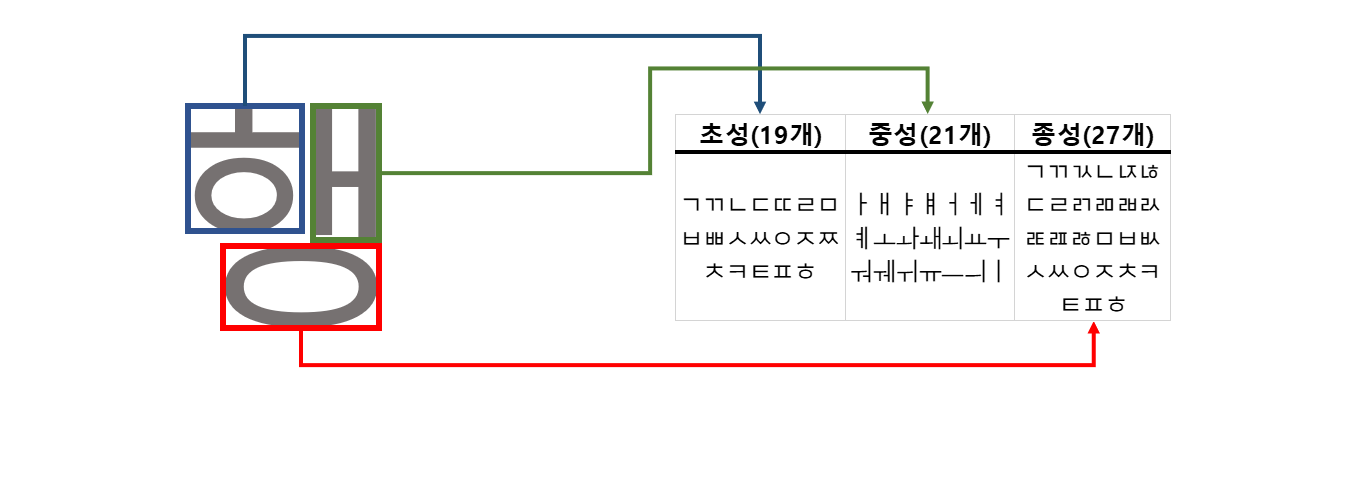
앞서 학습용 데이터(스크립트)는 직접(수동) 숫자, 특수문자, 영어등을 한글로 변경 했기 때문에 추가적인 전처리가 필요하지 않지만 추론(inference) 단계에서 모델을 잘 작동시키기 위해 전처리 코드를 추가가 필요합니다.
어떻게 한국어 전처리 코드를 추가해야 하는가?
다행히 한국어 버전 Tacotron2인 hccho2 리소스와 영어 버전 Tacotron2인 Nvidia 리소스는 모두 keithito 코드 를 기반으로 개발되었기 때문에 서로 호환이 가능합니다. 즉 hccho2 리소스 에서 한국어 전처리 코드 부분을 복사하여 Nvidia 리소스 에 붙여넣기 하는 방식으로 간단하게 한국어 전처리 코드를 추가할 수 있습니다.
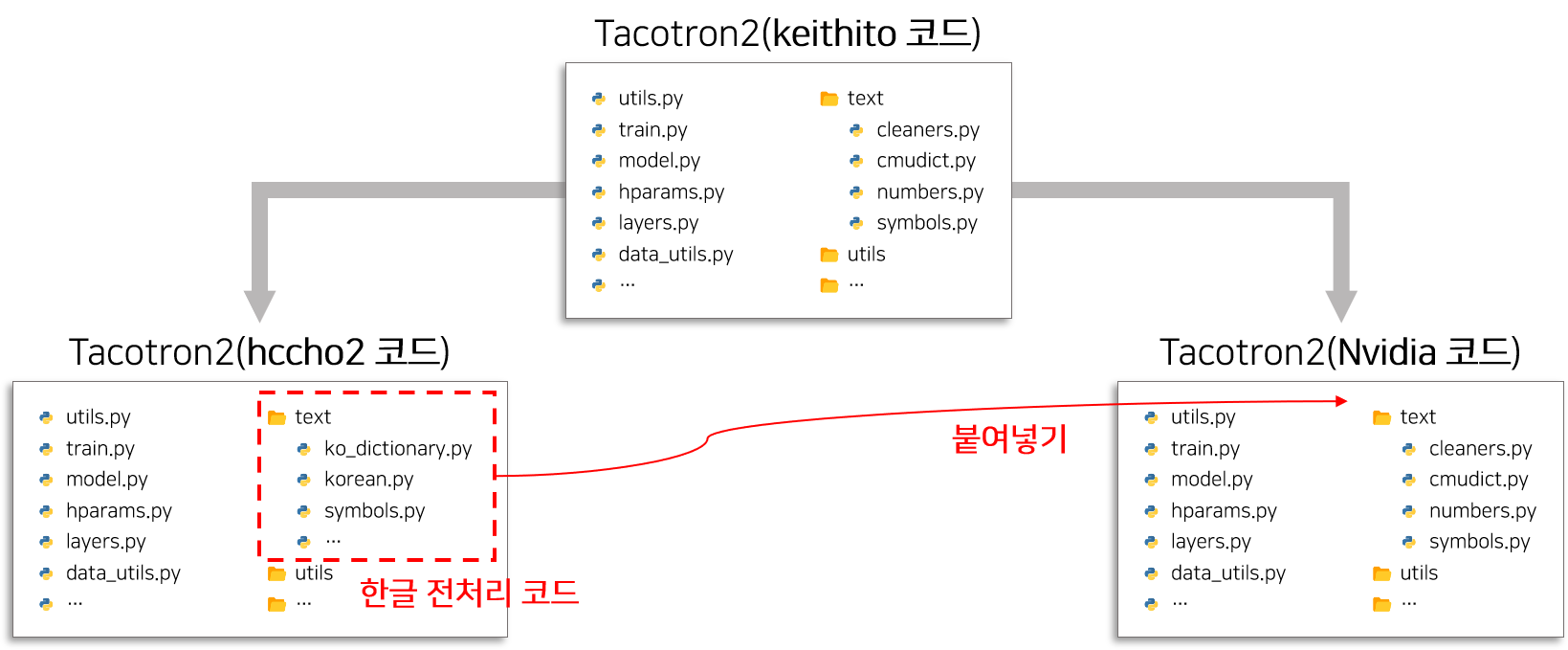
NVIDIA Tacotron2 코드를 forked 한 뒤 위 그림과 같은 방법으로 전처리 리소스를 추가한 코드는 아래의 명령어를 통해 다운받을 수 있습니다.
1
2
## 타코트론2 다운로드(한국어 전처리 코드 추가 version)
git clone https://github.com/JoungheeKim/tacotron2
리소스에 도커 파일(Dockerfile)과 설치 항목(requirements.txt)을 포함하고 있으므로 이를 활용하면 학습 환경을 구축할 수 있습니다.
Step4.2 학습 정보 파일 생성
학습 정보 파일이란 학습에 필요한 정보(음성 파일 위치, 스크립트)를 타코트론2 모델에게 전달하기 위해 정리한 문서를 의미합니다. 음성 파일의 위치와 해당 음성의 발화 스크립트로 구성된 병렬 데이터이며, 학습 및 검증용으로 train_data와 valid_data 2개가 필요합니다.

생성한 학습 정보 파일을 타코트론2 프로젝터 내 filelists 폴더에 위치시킵니다.
설정파일(hparams.py)에서 학습 파일 위치를 설정하기 때문에 파일 위치는 변경 가능합니다.
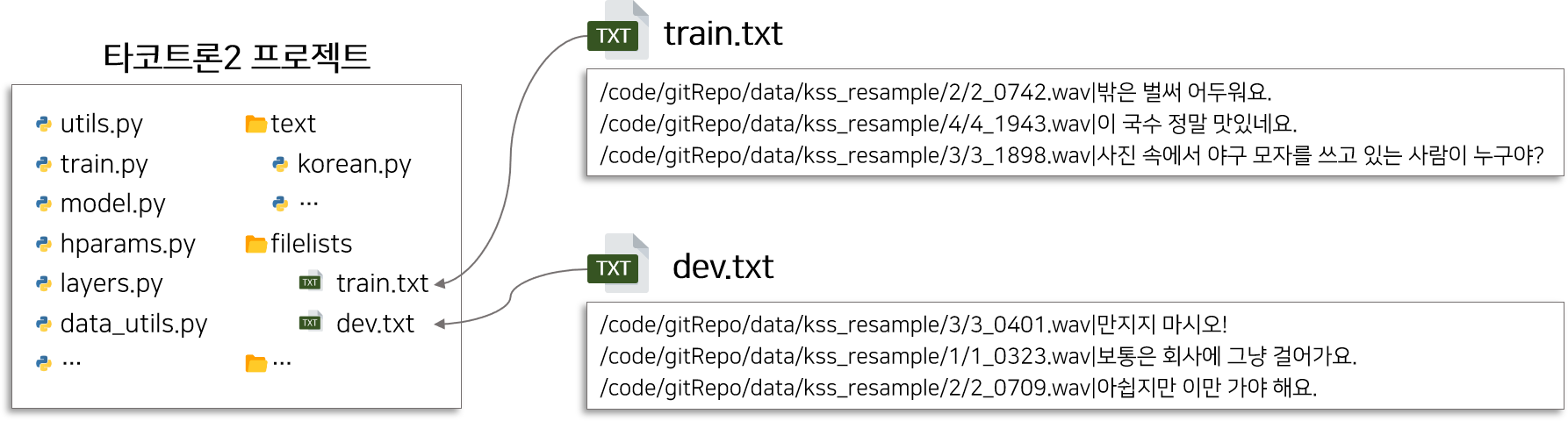
Step4.3 모델 학습하기
학습 정보 파일을 기반으로 타코트론2 모델을 학습시키기 간단한 명령어는 아래와 같습니다.
1
2
3
4
5
6
7
python train.py \
--output_directory=output \
--log_directory=log \
--n_gpus=1 \
--training_files=filelists/train_filelist.txt \
--validation_files=filelists/train_filelist.txt \
--epochs=500
Hyper-parameter종류output_directory: 학습된 모델의 Checkpoint를 저장할 폴더 위치log_directory: 학습 로그를 저장할 폴더 위치n_gpus: 사용할 GPU 개수training_files: “학습용 정보 파일” 위치validation_files: “검증용 정보 파일” 위치epochs: 데이터를 학습할 횟수sampling_rate: 음성 데이터의 Sampling Rateiters_per_checkpoint: checkpoint를 저장하는 iteration 단위text_cleaners: 전처리 프로세스 선택(한글 or 영어)checkpoint_path: Pre-trained Tacotron2 모델의 checkpoint 위치- …
위에서 기술한 것 이외에도 다양한 하이퍼파라미터 설정이 가능합니다.
설정 가능한 하이퍼파라미터의 종류와 Default Setting을 확인하시려면 hparams.py 파일을 확인 바랍니다.
음성 생성모델을 학습할 때 가장 많이 받는 질문 중 하나는 얼마나(epoch or max steps) 모델을 학습시켜야 하냐는 것 입니다. 저에게 정답이 있는 건 아니지만 개인적인 의견을 남겨보자면 데이터가 풍부할 때에는 모델이 과적합 될 수 있도록 오래 학습하는 것이 좋다고 생각합니다. 음성 모델의 개발 목적은 특정 인물의 음성의 특징을 나타내는 음성을 생성하는 것이므로 과적합을 시키는 것이 음성의 특징을 더 잘 나타낼 수 있는 모델을 만드는데 도움이 됩니다. 따라서 epoch을 크게 설정하고 학습하되, 학습 중간마다 생성된 Checkpoint로 음성을 생성하여 직접 들어보고 학습을 중단할지 결정하는 것이 좋아보입니다.
WaveGlow 모델을 이용하여 학습 예시
WaveGlow를 이용하여 Vocoder 모델을 학습하기 위해 아래 작업이 필요합니다.
- WaveGlow 리소스(코드) 다운
- 학습 정보 파일 생성
- WaveGlow 모델 학습하기
Step5.1 WaveGlow 리소스 다운
원본 NVIDIA WaveGlow 코드를 Git 관리 프로그램 을 이용하여 다운 받는 방법은 아래와 같습니다.
1
2
## WaveGlow 다운로드
git clone https://github.com/NVIDIA/waveglow.git
리소스에 도커 파일(Dockerfile)과 설치 항목(requirements.txt)을 포함하고 있으므로 이를 활용하면 학습 환경을 구축할 수 있습니다.
상세한 설치 카이드는 리소스 내 안내파일(read.md) 에서 제공하고 있습니다.
설치 항목에 tensorflow가 있지만 실제 쓰이고 있지는 않습니다. 참고하시기 바랍니다.
Step5.2 학습 정보 파일 생성
WaveGlow는 Mel-Spectrogram(멜 스펙토그램)을 통해서 Raw Audio(음성) 생성합니다. 따라서 학습 정보 파일에 음성 파일 위치만 필요합니다.
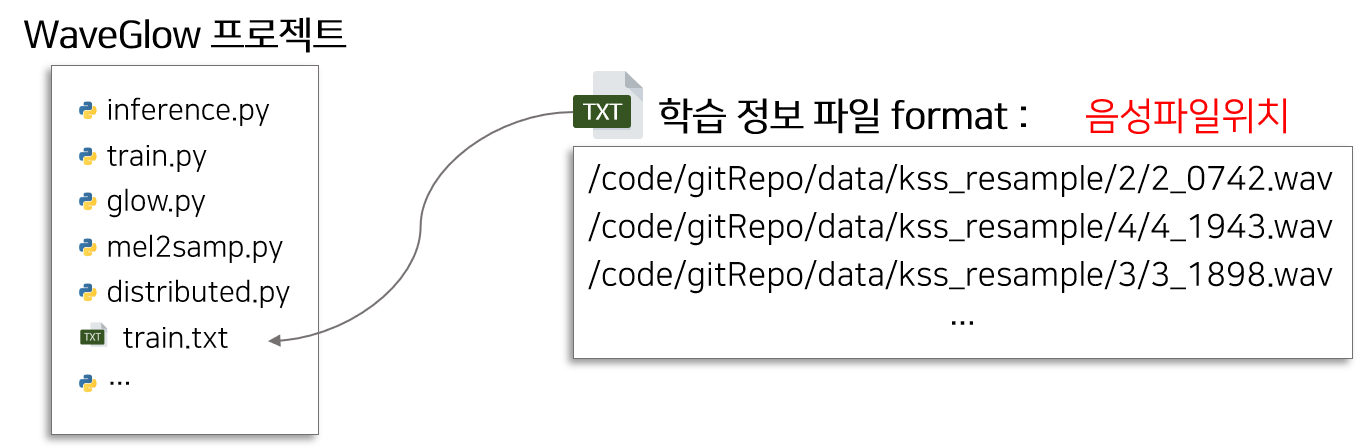
해당 파일 위치는 하이퍼파라미터의 인수로 들어가므로 편한 곳에 위치시키면 됩니다.
Step5.3 WaveGlow 모델 학습하기
WaveGlow는 학습에 필요한 하이퍼파라미터를 실행 명령어 인자로 받지 않고, json 형태의 파일로 받습니다.
기본적인 학습정보(하이퍼파라미터 정보)는 config.json 파일에 저장되어 있으며, 해당파일을 변경하여 실험이 가능합니다.
이 항목 중에서 training_files은 학습 정보 파일의 위치를 의미하므로 Step5.2에서 생성된 파일의 위치로 수정하여
WaveGlow가 음성파일을 인식할 수 있도록 합니다.
Hyper-parameter종류output_directory: 학습된 모델의 Checkpoint를 저장할 폴더 위치training_files: “학습용 정보 파일” 위치checkpoint_path: Pre-trained WaveGlow 모델의 checkpoint 위치- …
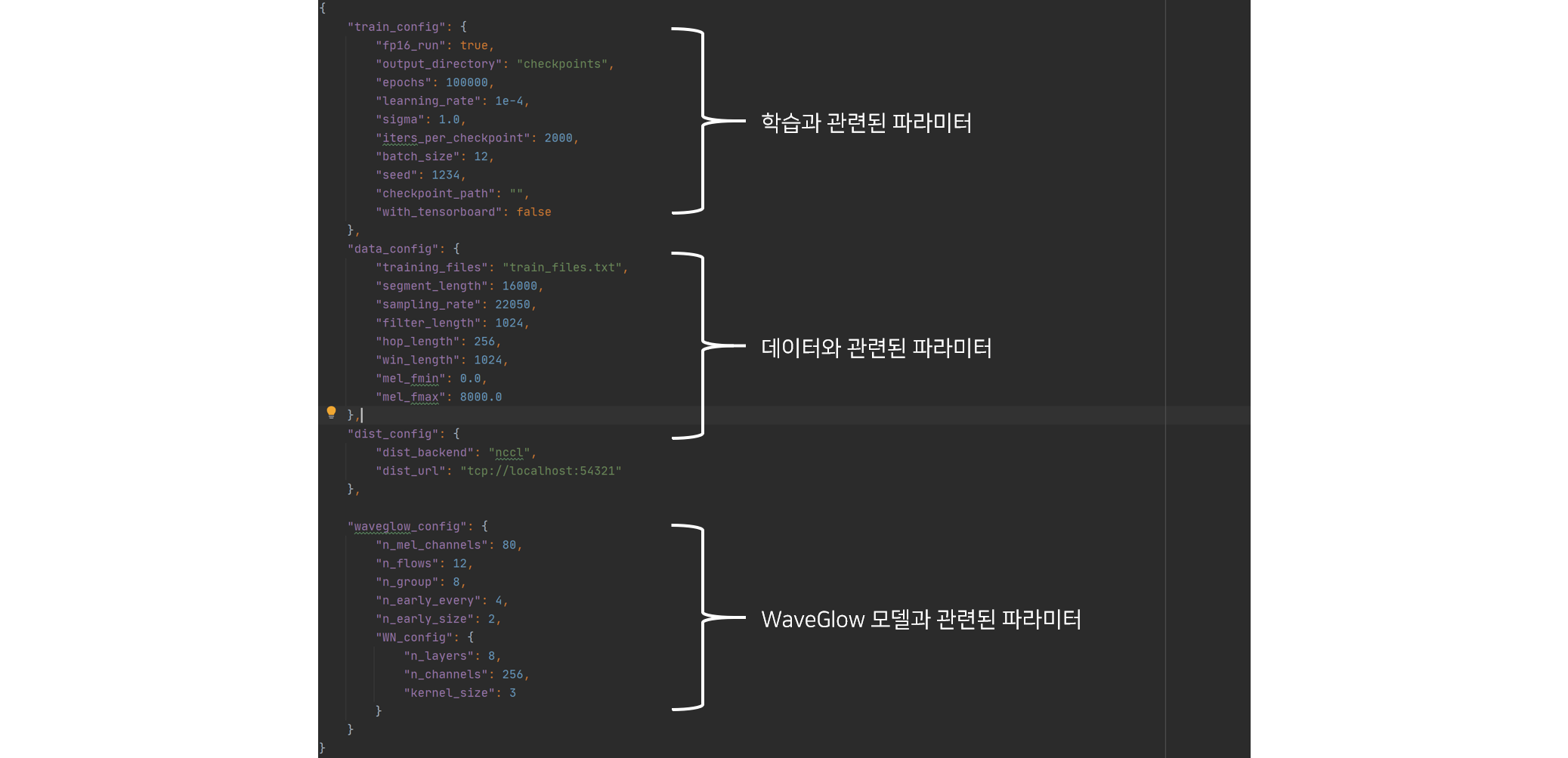
위 config.json 파일을 기반으로 WaveGlow 모델을 학습시키기 간단한 명령어는 아래와 같습니다.
1
python train.py -c config.json
Hyper-parameter종류config: 학습에 필요한 정보를 json 형태로 저장한 파일의 위치
Tacotron2 & WaveGlow Inference
Tacotron2와 WaveGlow 모델을 학습하면 각각 모델의 checkpoint가 생성됩니다. 아래 코드는 이 checkpoint를 활용하여 음성을 합성하는 방법입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
## 기본 라이브러리 Import
import sys
import numpy as np
import torch
import os
import argparse
## WaveGlow 프로젝트 위치 설정
sys.path.append('waveglow/')
## Tacontron2 프로젝트 위치 설정
sys.path.append('tacotron2/')
## 프로젝트 라이브러리 Import
from hparams import defaults
from model import Tacotron2
from layers import TacotronSTFT, STFT
from audio_processing import griffin_lim
from tacotron2.train import load_model
from text import text_to_sequence
from scipy.io.wavfile import write
import IPython.display as ipd
import json
import sys
from waveglow.glow import WaveGlow
from denoiser import Denoiser
from tqdm.notebook import tqdm
## dict->object 변환용
class Struct:
def __init__(self, **entries):
self.__dict__.update(entries)
def load_checkpoint(checkpoint_path, model):
assert os.path.isfile(checkpoint_path)
checkpoint_dict = torch.load(checkpoint_path, map_location='cpu')
model_for_loading = checkpoint_dict['model']
model.load_state_dict(model_for_loading.state_dict())
return model
class Synthesizer:
def __init__(self, tacotron_check, waveglow_check):
hparams = Struct(**defaults)
hparams.n_mel_channels=80
hparams.sampling_rate = 22050
self.hparams = hparams
model = load_model(hparams)
model.load_state_dict(torch.load(tacotron_check)['state_dict'])
model.cuda().eval()#.half()
self.tacotron = model
with open('waveglow/config.json') as f:
data = f.read()
config = json.loads(data)
waveglow_config = config["waveglow_config"]
waveglow = WaveGlow(**waveglow_config)
waveglow = load_checkpoint(waveglow_check, waveglow)
waveglow.cuda().eval()
self.denoiser = Denoiser(waveglow)
self.waveglow = waveglow
def inference(self, text):
assert type(text)==str, "텍스트 하나만 지원합니다."
sequence = np.array(text_to_sequence(text, ['korean_cleaners']))[None, :]
sequence = torch.autograd.Variable(torch.from_numpy(sequence)).cuda().long()
mel_outputs, mel_outputs_postnet, _, alignments = self.tacotron.inference(sequence)
with torch.no_grad():
audio = self.waveglow.infer(mel_outputs_postnet, sigma=0.666)
audio = audio[0].data.cpu().numpy()
return audio, self.hparams.sampling_rate
## \n으로 구성된 여러개의 문장 inference 하는 코드
def inference_phrase(self, phrase, sep_length=4000):
texts = phrase.split('\n')
audios = []
for text in texts:
if text == '':
audios.append(np.array([0]*sep_length))
continue
audio, sampling_rate = self.inference(text)
audios.append(audio)
audios.append(np.array([0]*sep_length))
return np.hstack(audios[:-1]), sampling_rate
def denoise_inference(self, text, sigma=0.666):
assert type(text)==str, "텍스트 하나만 지원합니다."
sequence = np.array(text_to_sequence(text, ['korean_cleaners']))[None, :]
sequence = torch.autograd.Variable(torch.from_numpy(sequence)).cuda().long()
mel_outputs, mel_outputs_postnet, _, alignments = self.tacotron.inference(sequence)
with torch.no_grad():
audio = self.waveglow.infer(mel_outputs_postnet, sigma=0.666)
audio_denoised = self.denoiser(audio, strength=0.01)[:, 0].cpu().numpy()
return audio_denoised.reshape(-1), self.hparams.sampling_rate
## 체크포인트 설정
tacotron2_checkpoint = 'C:/Users/dsbak/Desktop/gitRepo/tacotron2/base80/checkpoint_190000'
waveglow_checkpoint = 'C:/Users/dsbak/Desktop/gitRepo/tacotron2/waveglow/base80/waveglow_374000'
## 음성 합성 모듈 생성
synthesizer = Synthesizer(tacotron2_checkpoint, waveglow_checkpoint)
## 문장 생성
sample_text = '샘플 음성을 생성할 수 있습니다.'
audio, sampling_rate = synthesizer.inference(sample_text)
## 음성 저장하기
sf.write('문장.wav', audio, sampling_rate)
## 구문 생성
sample_phrase = """
타코트론 모델은 음성 생성 길이가 제한되어 있습니다.
즉 구문을 구성하려면 여러개의 문장을 생성한 후 합쳐야 합니다.
"""
audio, sampling_rate = synthesizer.inference_phrase(sample_phrase)
## 음성 저장하기
sf.write('구문.wav', audio, sampling_rate)
학습이 잘 되지 않은 모델(타코트론)은 문장을 여러번 반복하는 문제가 있습니다. 따라서 이를 방지하고자 모델이 특정길이(약 11초) 이상의 음성을 생성하지 못하도록 제한하고 있습니다. 즉 구문을 만들기 위해서는 여러개의 문장 각각 생성한 다음 이어 붙이거나 코드 수정이 필요합니다.
이 가이드라인을 통해 생성한 음성 샘플입니다.
/img/in-post/2021/2021-04-02/jhee_sample.wav
/img/in-post/2021/2021-04-02/kss_sample.wav
/img/in-post/2021/2021-04-02/tak_sample.wav
위 코드와 관련된 파일은 Jupyter Notebook 링크 를 눌러 다운받으실 수 있습니다.
자세히 들어보면 음성에 노이즈가 포함되어 있는 것을 확인할 수 있습니다. 후처리 모듈을 추가하여 제거하는 방법이 필요한데 해당 포스팅에서는 관련 내용은 다루지 않습니다.
개인화 TTS 모델 생성 전략
간단한 예제를 통해서 Tacotron2 모델과 WaveGlow를 활용하여 개인 TTS 시스템을 만드는 방법에 대해 말씀드렸습니다. 하지만 여전히 데이터가 충분하지 않은 경우 모델이 수렴할 수 있을 정도로 학습시키는 것은 매우 어려운 일입니다. 모델이 수렴한다는 것은 결국 음성과 텍스트 사이의 위치를 관계를 모델이 잘 파악할 수 있다는 것을 의미합니다.
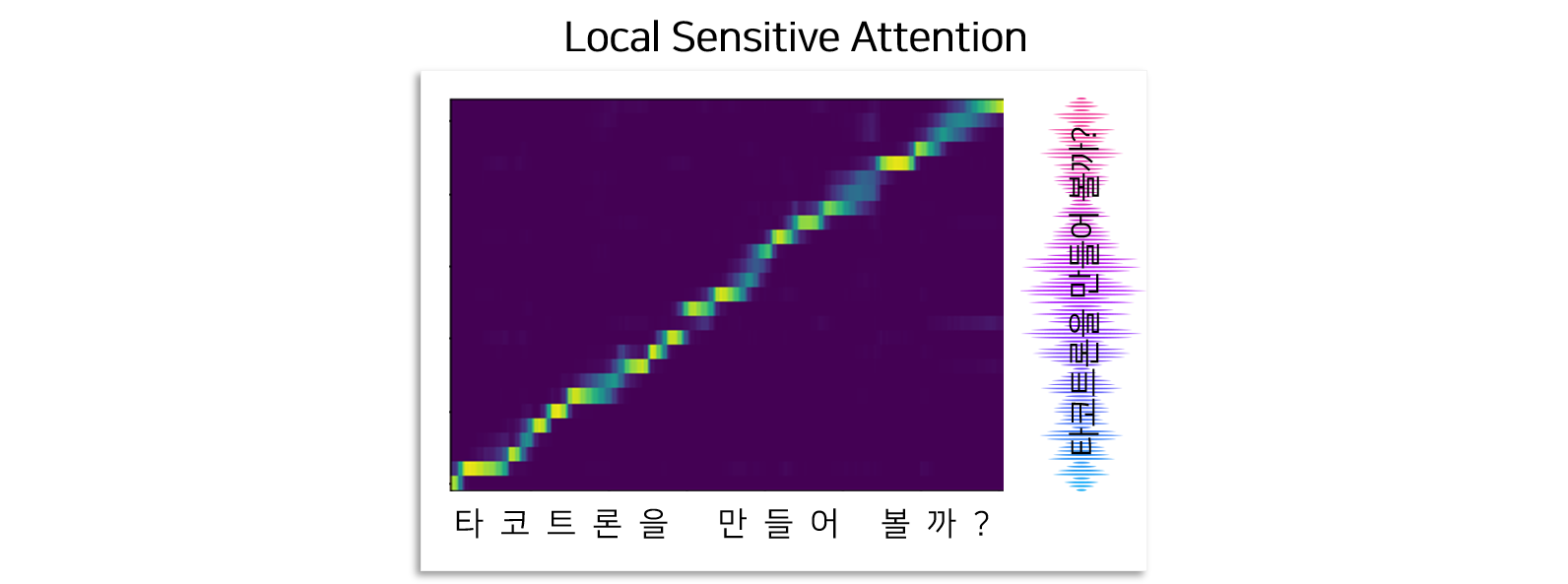
충분히 학습하지 못한 경우, 데이터가 충분하지 않은 경우, 데이터의 질이 좋지 못한 경우 등 다양한 사유로 인해 학습된 타코트론2 모델은 음성과 텍스트 사이의 관계를 잘 찾지 못합니다. 이러한 문제점은 Inference 할 때 모델이 동일한 문장을 반복하는 음성을 생성하는 결과로 이어집니다. 즉 음성의 품질이 대폭 하락하는 문제점을 야기시킵니다.
이 현상을 타코트론2 모델 안에 있는 Attetnion Map을 보면서 해석을 해보면, 모델이 충분히 학습되지 못할 경우 입력인 텍스트와 출력인 음성 사이의 Attention 잘 만들어지 지지 않아서 발생한다고 볼 수 있습니다.
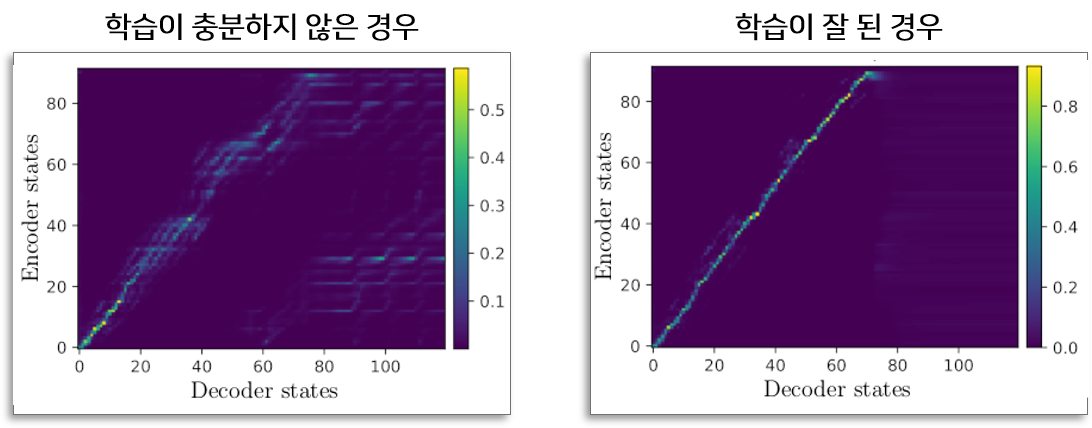
이 문제를 해결하기 위하여 다양한 방법을 적용할 수 있습니다.
- 모델 내부 아키텍처를 변경(Attention과 관련된)
- Augmentation 방법론을 적용하여 데이터 양 확보
- Transfer Learning 방법론을 적용
가장 쉬운 방법은 아무래도 Transfer Learining 방법론을 적용하는 것 입니다. 즉 먼저 외부의 정제된 데이터를 많이 모아서 모델을 학습(pre-training)시키고, 그 다음 학습된 모델을 목표로 하는 데이터로 다시 학습(fine-tuning) 시키는 것입니다.
많은 데이터를 이용하여 모델이 보편적인 발화라는 Task를 학습할 수 있도록 하여 모델 안의 Attetion이 제기능(initialization)을 갖추면, 이후 그 Checkpoint(pretrained model)를 활용하여 적은 양의 데이터로도 안정적이게 학습할 수 있습니다.
어떤 정제된 데이터를 활용할 수 있을까?
KSS 데이터셋은 그 양이 많을 뿐더러 잡음이 없어서 가장 잘 정제되어 있는 데이터 중 하나입니다. 따라서 먼저 KSS 데이터셋을 활용하여 모델을 pre-training하고, 그 다음 원하는 음성 데이터로 fine-tuning하는 방식으로 Transfer Learning을 적용할 수 있습니다.
![]()
동일하게 WaveGlow도 KSS 데이터셋을 활용하여 모델을 pre-training하고, 그 다음 원하는 음성데이터로 fine-tuning하는 방식이 안정적으로 모델을 학습시킬 수 있습니다.
KSS 데이터로 약 300000 Step 정도 pre-training하면 모델 안에 Attetnion 모듈이 음성과 텍스트 사이의 정렬 규칙을 잘 찾습니다. 그 Checkpoint를 활용하여 원하는 데이터로 약 500000 ~ 800000 step정도 fine-tuning하면 썩 괜찮은 음성생성모듈을 개발 할 수 있습니다. 위 파이프라인을 활용한다면 GPU 2080ti 한장으로 Tacotron2 모델을 학습하는데 약 3일~6일, WaveGlow 모델을 학습하는데 약 3일~6일 정도 소요됩니다.