[논문리뷰] - TACOTRON2 : Natural TTS Synthesis By Conditioning WAVENET On Mel Spectrogram Predictions, ICASSP 2018
WaveNet, Tacotron 등 딥러닝 방법론이 적용되면서 최근 몇년간 TTS(Text to Speech)은 빠르게 발전하였습니다. 따라서 이제는 복잡한 작업 절차 없이 데이터를 학습하여 텍스트로부터 고품질의 음성을 생성할 수 있게 되었습니다.
그에 따라 오늘날 음성합성은 다양한 방향으로 적용되고 있습니다. 예를들어 네이버에서는 “유인나가 읽어주는 오디오북” 서비스를 출시하였고 이제는 배우 유인나의 목소리로 다양한 이야기를 들을 수 있게 되었습니다. 또한 유투버들은 각각 개인의 특성을 살린 음성합성 프로그램(TTS)을 만들어 음성 도네이션 목소리로 활용하고 있습니다.
오늘 포스팅에서는 현재시점으로 대중적인 TTS(Text to Speech)모델인 타코트론2 or Tacotron2에 대해 상세하게 리뷰하겠습니다.
이 글은 Tacotron2 논문 을 참고하여 정리하였음을 먼저 밝힙니다.
논문 그대로를 리뷰하기보다는 생각을 정리하는 목적으로 제작하고 있기 때문에 논문 이외의 내용을 포함하고 있으며 사실과 다른점이 존재할 수 있습니다.
혹시 제가 잘못 알고 있는 점이나 보안할 점이 있다면 댓글 부탁드립니다.
Short Summary
이 논문의 큰 특징 3가지는 아래와 같습니다.
- Attention 기반 Seq-to-Seq TTS 모델 구조를 제시합니다.
- <문장, 음성> 쌍으로 이루어진 데이터만으로 별도의 작업없이 학습이 가능한 End-to-End 모델입니다.
- 음성합성 품질 테스트(MOS)에서 높은 점수를 획득하였습니다. 합성품질이 뛰어납니다.
모델 전체 구조
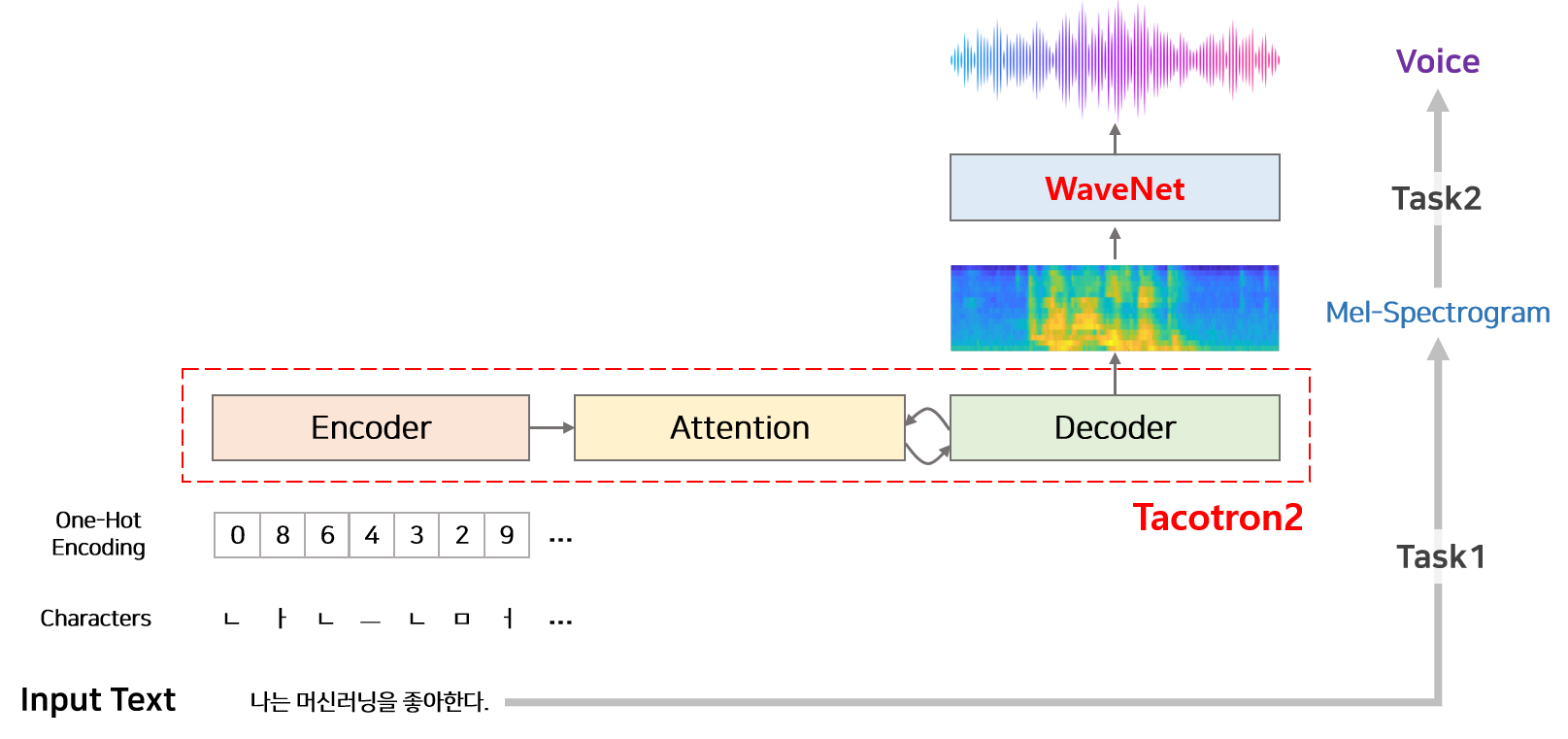
모델은 텍스트를 받아 음성을 합성합니다. 따라서 최종 Input과 Output은 텍스트와 음성입니다. 하지만 텍스트로부터 바로 음성을 생성하는 것은 어려운 Task이므로 타코트론2 논문에서는 TTS를 두단계로 나누어 처리합니다.
- Task1 : 텍스트로부터 Mel-spectrogram을 생성하는 단계
- Task2 : Mel-spectrogram으로부터 음성을 합성하는 단계
첫번째 단계는 Sequence to Sequence 딥러닝 구조의 타코트론2 모델이 담당하고 있습니다. 두번째 단계는 Vocoder로 불리며 타코트론2 논문에서는 WaveNet 모델을 변형하여 사용합니다.
1 타코트론2(Seq2Seq)
타코트론2 모델의 input은 character이고, output은 mel-Spectrogram 입니다. 모델은 크게 Encoder, Decoder, Attention 모듈로 구성되어 있습니다. Encoder는 character를 일련 길이의 hidden 벡터(feature)로 변환하는 작업을 담당합니다. Attention은 Encoder에서 생성된 일정길이의 hidden 벡터로부터 시간순서에 맞게 정보를 추출하여 Decoder에 전달하는 역할을 합니다. Decoder는 Attention에서 얻은 정보를 이용하여 mel-spectrogram을 생성하는 역할을 담당합니다.
1.1 전처리
모델을 학습하기 위해서 input과 output(label)이 한쌍으로 묶인 데이터가 필요합니다. 텍스트와 음성이 쌍으로 묶인 데이터가 있다면 이를 모델의 input과 output(label)의 형태로 가공하여야 합니다. 즉 텍스트는 character로 만들어야 하고 음성은 Mel-spectrogram으로 변형해야 합니다.
우선 영어라면 띄어쓰기가 포함하여 알파벳으로 나누는 작업을 통해 텍스트를 character로 변경할 수 있습니다. 예를들어 ‘I love you’ 텍스트는 character sequence 즉 ‘i’, ‘ ‘, ‘l’, ‘v’…, ‘u’ 로 변경 됩니다. 이후 one-hot encodding을 적용하여 character sequence를 정수열로 변경한 뒤 모델의 input으로 활용합니다.
타코트론2에 한글을 적용한 구현체의 대부분이 텍스트를 character로 변활할 때에는 음절을 이용합니다. 즉 초성(19개), 중성(21개), 종성(27개)으로 나눕니다. 초성과 종성은 자음으로 구성되어 있어 동일하게 표기될 수 있으나 구분하여 활용합니다.
[한국어 타코트톤 적용 참고자료]
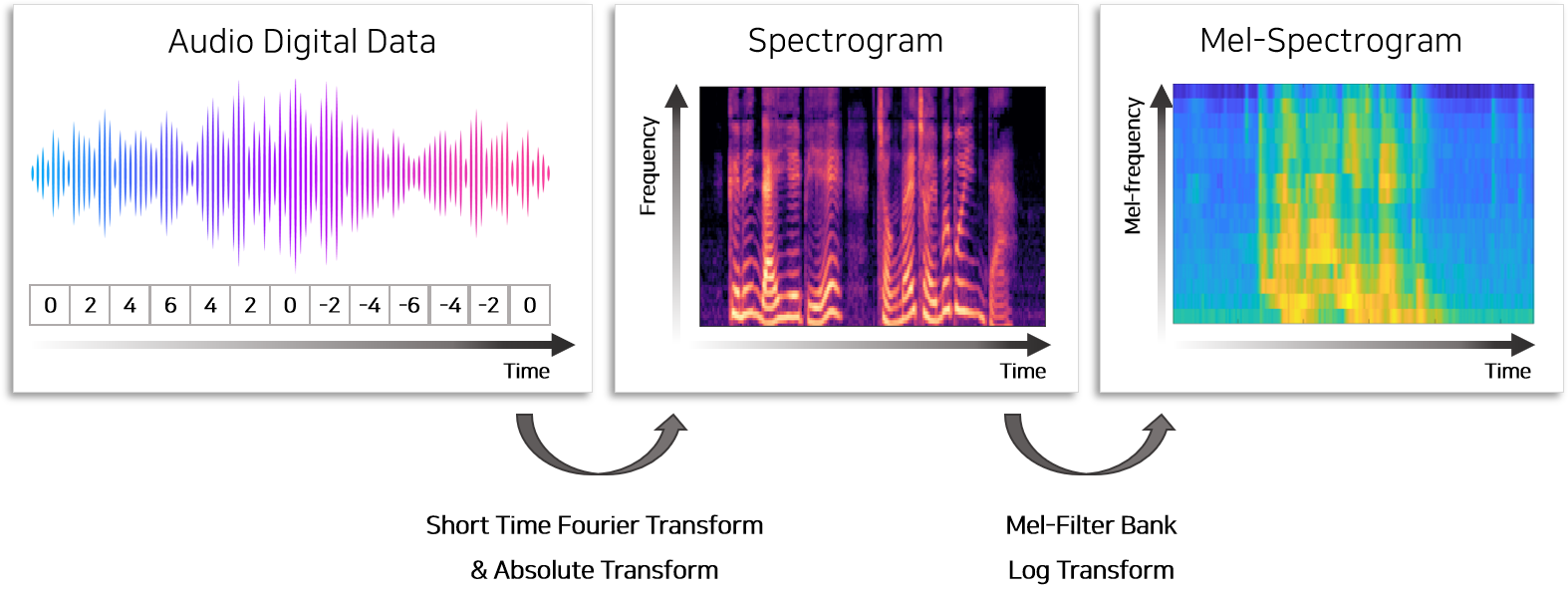
음성데이터로부터 mel-spectrogram을 추출하여 output으로 활용하기 위하여 총 3가지 전처리 작업이 필요합니다.
- Short-time Fourier Transform(STFT)
- 80개의 mel filterbank를 이용하여 Mel scaling
- Log transform
오디오데이터에는 여러개의 오디오(frequency)가 섞여 있으므로 여러개의 오디오를 분리하여 표시하기 위하여 Fourier transform을 활용합니다. 다만 모든데이터에 Fourier transform을 적용하면 시간에 따른 오디오의 변화를 반영할 수 없으므로 sliding window를 이용하여 오디오를 특정길이로 잘라 Fourier Transform을 적용합니다. 이 결과물을 spectrogram이라고 하며 오디오로부터 spectrogram을 만드는 과정을 short-time Fourier Transform이라고 지칭합니다.
두번째 단계는 spectrogram에 mel-filter bank라는 비선형 함수를 적용하여 저주파(low frequency) 영역을 확대하는 작업입니다. 사람의 귀는 고주파보다 저주파에 민감하므로 저주파의 영역을 확대하고 고주파의 영역을 축소하여 feature로 사용합니다. 이는 더 명료한 음성을 생성하기 위하여 feature를 사람이 쉽게 인지 가능한 scale로 변환하는 작업입니다.
이후 log를 취해 amplitude 영역에서의 log scaling을 진행하면 mel-spectrogram이 생성되며 모델의 output(label)으로 활용합니다.
1.2 Encoder
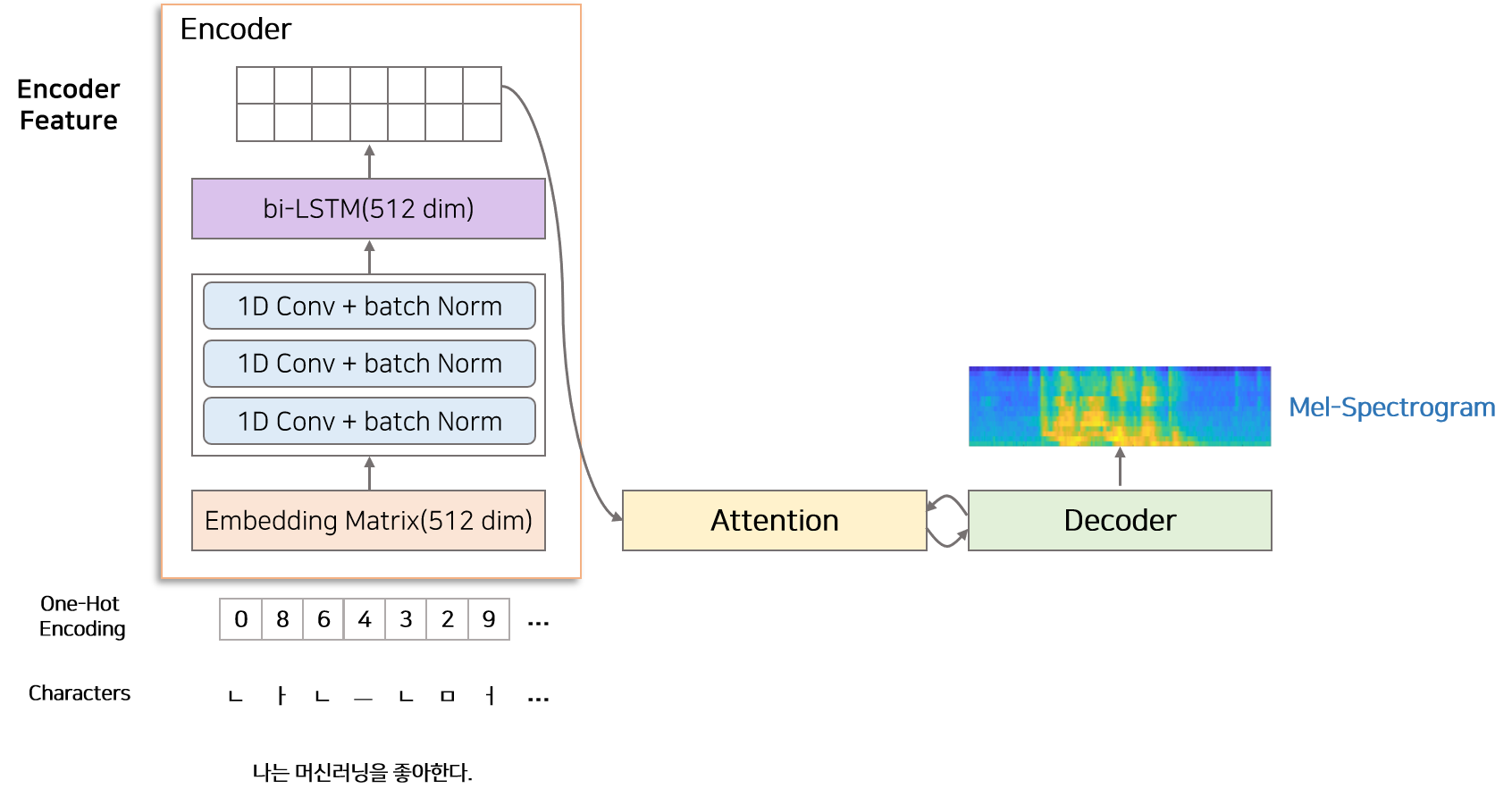
Encoder는 character 단위의 one-hot verctor를 encoded feature로 변환하는 역할을 합니다. Encoder는 Character Embedding, 3 Convolution Layer, Bidirectional LSTM으로 구성되어 있습니다.
input으로 one-hot vector로 변환된 정수열이 들어오면 Embedding matrix를 통해 512차원의 embedding vector로 변환됩니다. embedding vecotor는 3개의 conv-layer(1d convolution layer + batch norm)를 지나 bi-LSTM layer로 들어가서 encoded feature로 변환됩니다.
1.3 Attention
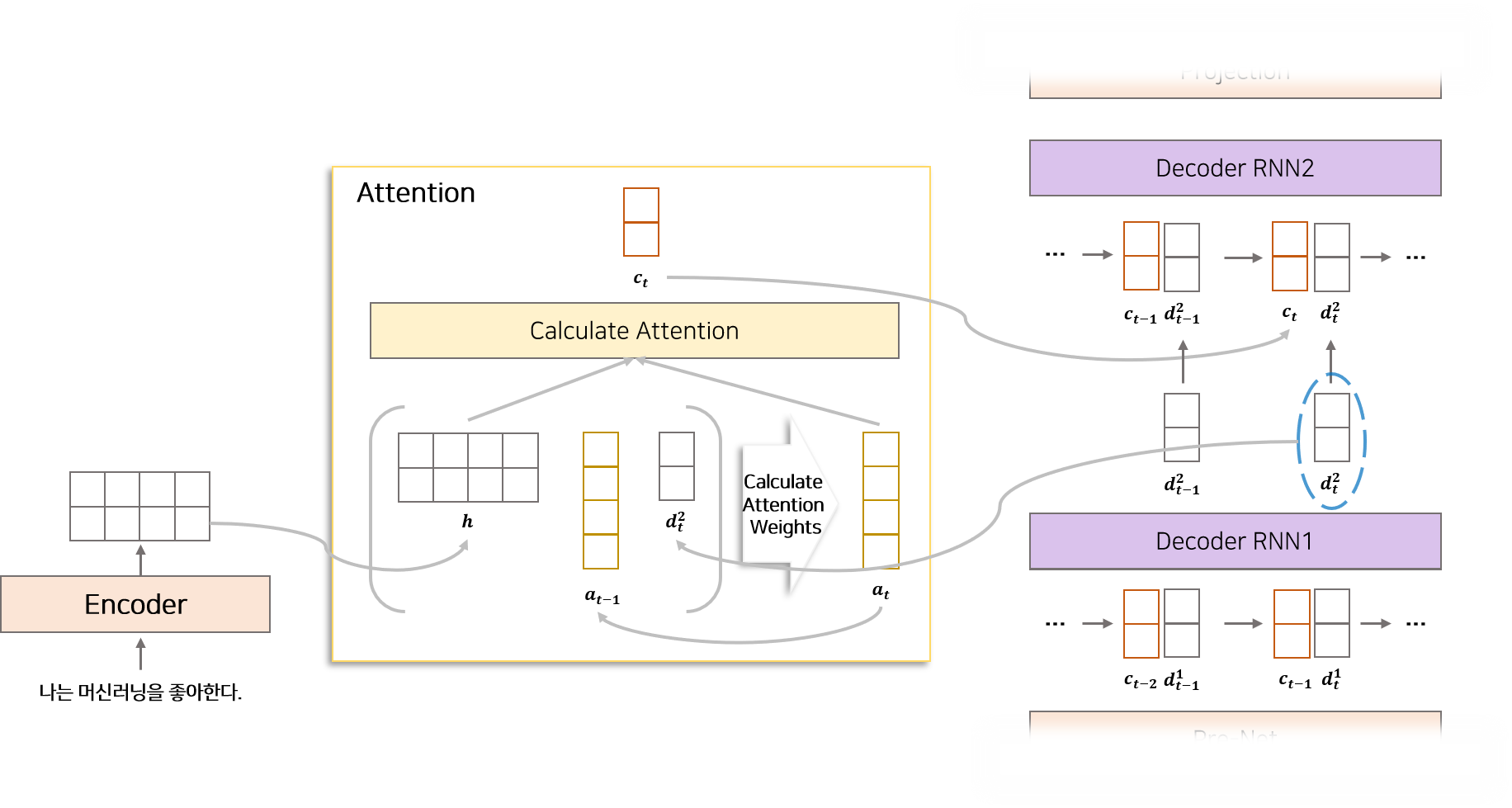
Attention은 매 시점 Deocder에서 사용할 정보를 Encoder에서 추출하여 가져오는 역할을 합니다.
즉 Attention Mechanism은 Encoder의 LSTM에서 생성된 feature와 Decoder의 LSTM에서 전 시점에서 생성된 feature를 이용하여 Encoder로 부터 어떤 정보를 가져올지 alignment하는 과정을 의미합니다.
타코트론2 모델은 Location Sensitive Attention 을 사용합니다.
Location Sensitive Attention 이란 Additive attention mechanism(Bandau Attetnion)에 attention alignment 정보를 추가 한 형태입니다.
Additive Attention
$W, V$ : 학습이 가능한 matrix weights
$w, b$ : 학습이 가능한 bector weights
$h_{i}$ : Encoder bi-LSTM에서 생성된 $i$번째 feature
$d_{t}$ : Decoder LSTM에서 생성된 $t$번째 feature
$s_{t, i}$ : $t$ 시점에서 hidden $i$ 에 대한 attention score
$\alpha_{t, i}$ : $t$ 시점에서 hidden $i$ 에 대한 alignment(0~1)
$c_{t}$ : $t$시점에서 Attetnion 모듈로 부터 추출한 context vector
Addictive Attention 은 Encoder RNN으로부터 생성된 feature($h$)와 Decoder RNN의 한 step 전 결과물($d_{t-1}$) 을 이용하여 attention alignment($\alpha_{t}$)를 구합니다.
Location Sensitive Attention
$U$ : 학습이 가능한 matrix weights
$F$ : Convolution Filter
Location Sentitive Attention은 이전 시점($t-1$)에서 생성된 attention alignment($\alpha_{t-1}$)를 이용하여 다음 시점($t$) Attention alignment($\alpha_{t}$)를 구할 때 추가로 고려한 형태입니다. k개의 filter를 갖고 있는 1D convolution을 이용하여 Attention alignment($\alpha_{t-1}$)를 확장하여 $f_{i}$ matrix를 생성합니다. 이후 학습이 가능한 weights($U$)와 내적한 후 Addictivae attention의 구성에 포함하여 계산합니다.
논문에서 Attention과 관련하여 자세한 구조를 설명하고 있지 않습니다. 따라서 Pytorch 구현체 를 보고 자료를 구성하였습니다.
1.4 Decoder
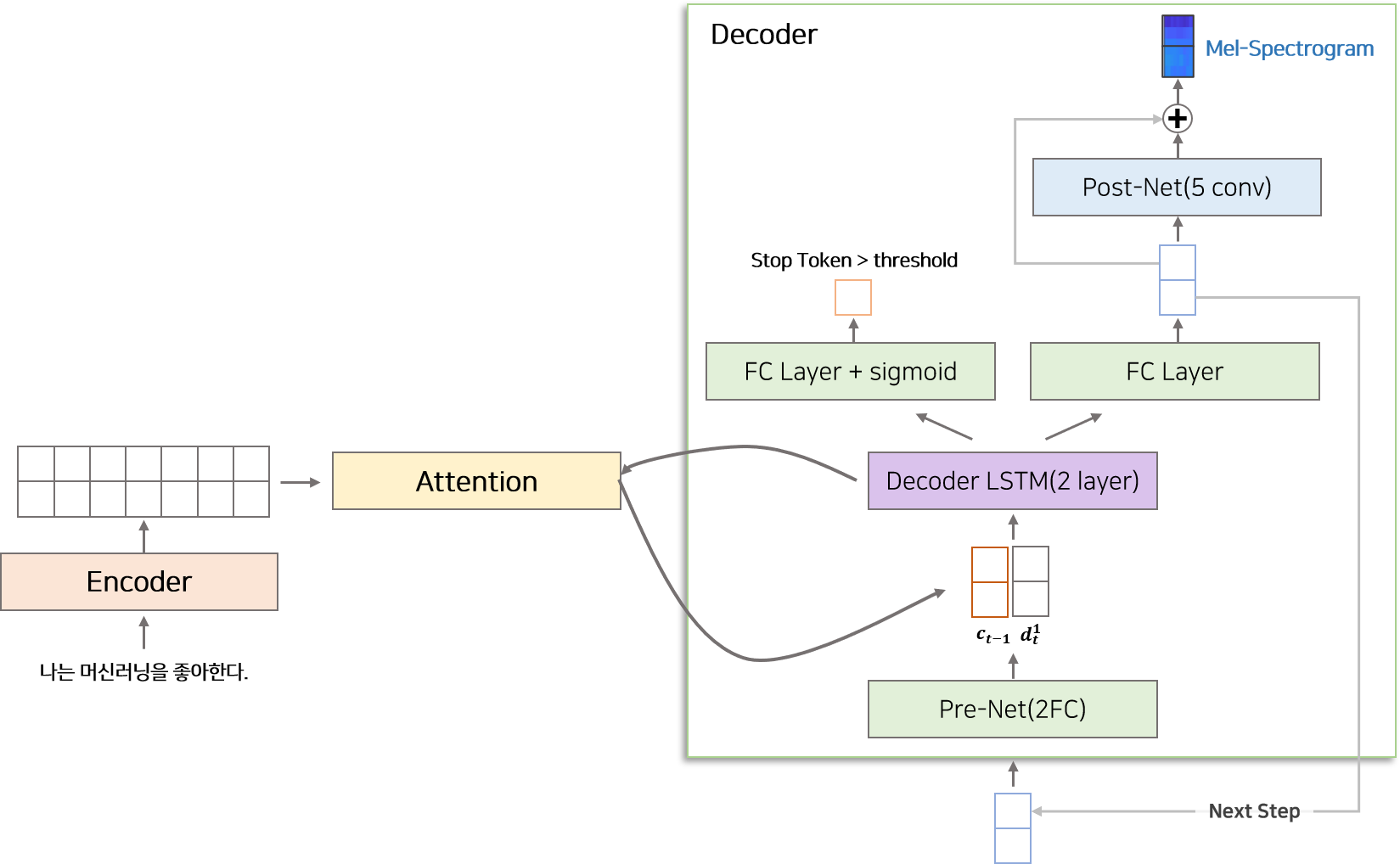
Decoder는 Attention을 통해 얻은 alignment feature와 이전 시점에서 생성된 mel-spectrogram 정보를 이용하여 다음 시점 mel-spectrogram을 생성하는 역할을 합니다. Decoder는 Pre-Net, Decoder LSTM, Projection Layer, Post-Net으로 구성됩니다.
Pre-Net은 2개의 Fully Connected Layer(256 dim) + ReLU 으로 구성되어 있습니다. 이전 시점에서 생성된 mel-spectrogram이 decoder의 input으로 들어오면 가장먼저 Pre-Net을 통과합니다. Pre-Net은 bottle-neck 구간으로써 중요 정보를 거르는 역할을 합니다.
Decoder LSTM은 2개의 uni-directional LSTM Layer(1024 dim) 으로 구성되어 있습니다. Pre-Net을 통해 생성된 vector와 이전 시점($t-1$)에서 생성된 context vector($c_{t-1}$)를 합친 후 Decoder LSTM을 통과합니다. Decoder LSTM은 Attention Layer의 정보와 Pre-Net으로부터 생성된 정보를 이용하여 특정 시점($t$)에 해당하는 정보를 생성합니다.
Decoder LSTM에서 생성된 매 시점($t$) vector는 두개로 분기되어 처리됩니다.
- 종료 조건의 확률을 계산하는 경로
- mel-spectrogram을 생성하는 경로
종료 조건의 확률을 계산하는 경로는 Decoder LSTM으로부터 매 시점 생성된 vector를 Fully Connected layer를 통과시킨 후 sigmoid 함수를 취하여 0에서 1사이의 확률로 변환합니다. 이 확률이 Stop 조건에 해당하며 사용자가 설정한 threshold를 넘을 시 inference 단계에서 mel-spectrogram 생성을 멈추는 역할을 합니다.
mel-spectrogram을 생성하는 경로는 Decoder LSTM으로부터 매 시점 생성된 vector와 Attention에서 생성된 context vector를 합친 후 Fully Connected Layer를 통과시킵니다. 이렇게 생성된 mel-vector는 inference 단계에서 Decoder의 다음 시점의 input이 됩니다.
Post-Net은 5개의 1D Convolution Layer로 구성되어 있습니다. Convolution Layer는 512개의 filter와 5×1 kernel size를 가지고 있습니다. 이전 단계에서 생성된 mel-vector는 Post-Net을 통과한 뒤 다시 mel-vector와 구조(Residual Connection)로 이루어져 있습니다. Post-Net은 mel-vector를 보정하는 역할을 하며 타코트론2 Task1의 최종 결과물인 mel-spectrogram의 품질을 높이는 역할을 합니다.
1.5 타코트론2 Loss
타코트론2로부터 생성된 mel-spectrogram과 실제 mel-spectrogram의 MSE(mean squared error)를 이용하여 모델을 학습합니다.
2 WaveNet Vocoder
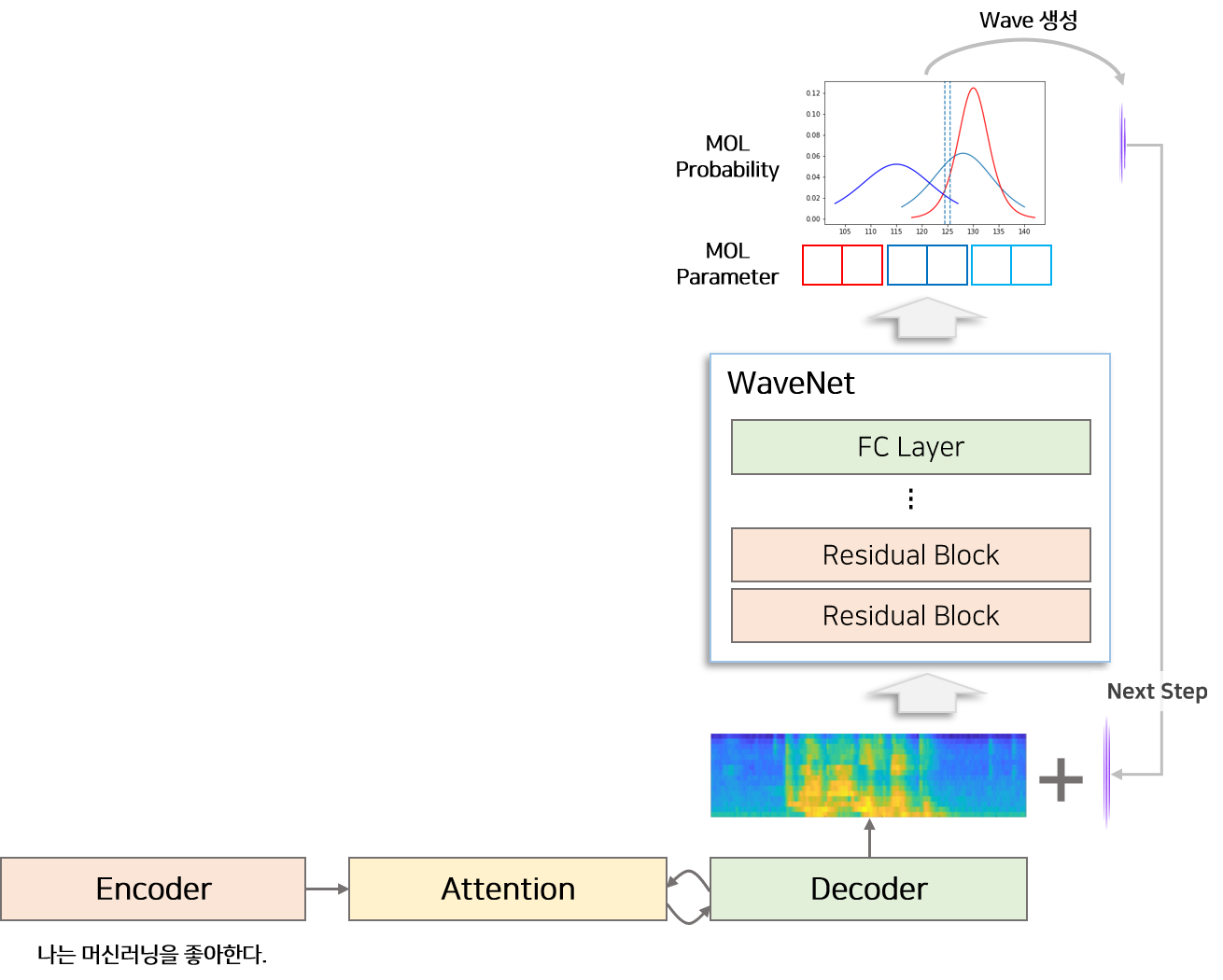
Vocoder는 mel-spectrogram 으로부터 waveform(음성)을 생성하는 모듈을 의미합니다. 타코트론2 논문에서는 WaveNet의 구조를 조금 변경한 모델을 Vocoder로 사용합니다. WaveNet 논문 에서 제시한 모델은 Softmax 함수를 이용하여 매 시점 $-2^{15}$ ~ $2^{15}+1$ 사이의 숫자가 나올 확률을 추출하고 waveform 생성합니다. 이를 수정하여 PixelCNN++ 처럼 mixture of logistic distribution(MoL) 을 이용하여 매 시점 $-2^{15}$ ~ $2^{15}+1$ 사이의 숫자가 나올 확률을 생성합니다.
위 그림에서는 mel-spectrogram을 이용하여 WaveNet은 MOL에 사용할 paramter를 생성합니다. 생성된 paramter를 이용하여 $-2^{15}$ ~ $2^{15}+1$ 사이의 숫자가 나올 확률인 mixture of logistic distribution를 생성하고 가장 큰 확률을 갖고 있는 값을 이용하여 waveform을 생성합니다.
2.1 WaveNet Loss
WaveNet으로부터 생성된 waveform과 실제 waveform의 시점 별 Negative log-likelihood Loss를 이용하여 모델을 학습합니다.
학습 설정
타코트론2, WaveNet(MoL)을 학습할 때 teacher-forcing을 사용합니다. 타코트론2은 이전시점 생성된 mel-spectrogram과 encoder featrure를 이용하여 다음 시점 mel-spectrogram을 생성합니다. training 단계에는 input을 이전 시점 타코트론2로부터 생성된 mel-spectrogram을 사용하지 않고 ground-truth mel-spectrogram을 사용하여 학습 효율을 증가시킵니다. WaveNet을 학슬 할 때에도 input으로 WaveNet의 이전단계에서 생성된 waveform을 사용하는 것이 아닌 ground-truth waveform을 이용합니다.
평가
모델을 평가하기 위한 데이터로 24.6시간 한 사람의 음성을 담은 US English dataset을 이용합니다. 피실험자에게 음성을 들려주고 1점에서 5점까지 0.5점씩 증가하여 점수를 매기는 mean opinion score(MOS) 테스트를 진행합니다. linguastic feature를 이용하여 음성을 생성하는 WaveNet, 타코트론1, Parametric 모델, Concatenative 모델을 학습하여 비교모델로 활용합니다.
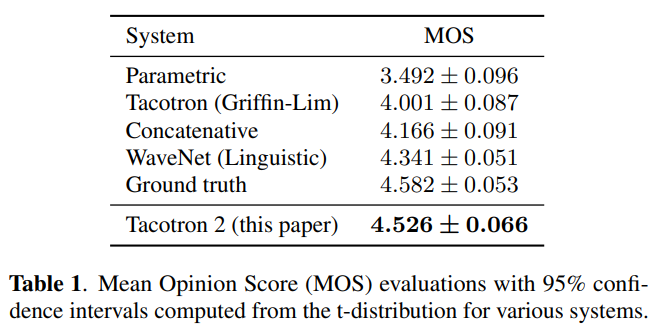
타코트론2로부터 생성된 음성이 실제 음성(ground truth)과 비슷한 평가를 받았습니다.
Ablation Studies
(1) Predicted Features versus Ground Truth
Task를 2가지로 나누어 서로다른 모델(타코트론2, WaveNet)이 따로따로 해당하는 Task에 분리되어 학습됩니다. Vocoder는 inference(synthesis) 단계에서는 타코트론2에서 생성된 mel-spectrogram(predicted)을 활용하여 waverform을 생성해야 합니다. 하지만 training 단계에서는 input으로 타코트론2로부터 생성된 mel-spectrogram(predicted) 또는 실제 mel-spectrogram(ground truth)를 사용할 수 있습니다.
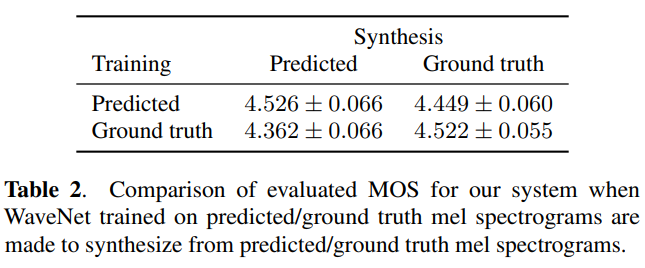
WaveNet을 training 단계에서 mel-spectrogram(ground truth)를 사용하여 학습한 후 inference 단계에서 타코트론2로부터 생성된 mel-spectrogram(predicted)을 이용하여 음성을 합성했을 때 안 좋은 성능을 보입니다. 타코트론2에서 생성된 mel-spectrogram은 ground-truth보다 smmothing되어 생성되므로 ground-truth으로 학습한 WaveNet은 smmothing mel-spectrogram으로부터 품질 좋은 음성을 생성하지 못합니다.
(2) Linear Spectrograms
mel-spectrogram 대신 linear-frequency spectrogram을 사용하여 모델을 학습했을 때 성능을 비교합니다.
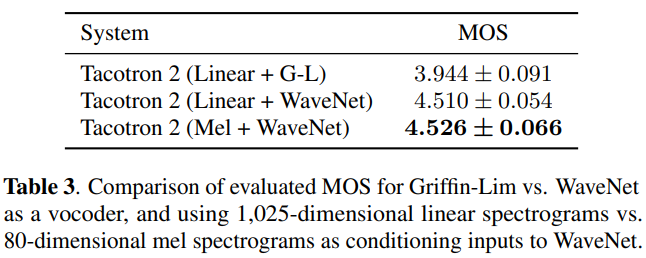
mel-spectrogram을 이용하여 학습한 모델이 가장 좋은 성능을 보입니다. 하지만 큰 성능차이를 보이지 않습니다.
(3) Simplifying WaveNet
WaveNet은 수용범위(receptive field)를 넓히기 위하여 많은 dilation conv를 쌓아서 모델을 구성합니다. 즉 dilation conv 갯수 및 cycle에 따라 수용범위가 변경됩니다. 이 실험은 Dilation Conv를 포함하고 있는 Residual Layer의 갯수와 Dilation cycle를 조절하며 음성의 품질을 평가합니다.
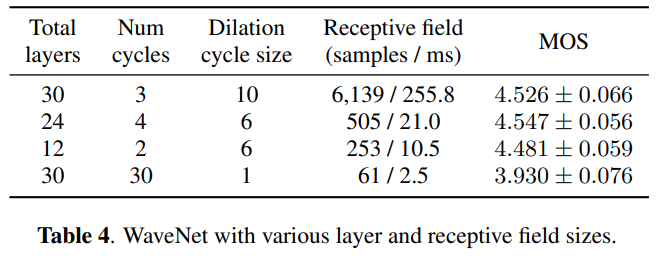
비교적 적은 Layer 개수와 수용범위(receptive field)로도 충분히 품질 좋은 음성을 생성할 수 있습니다.
결론 및 개인적인 생각
타코트론1과 매우 흡사한 구조를 갖고 있습니다.
타코트론1에서는 CBHG가 중요한 역할을 한다고 기술하였지만 타코트론2에서는 해당 구조를 사용하지 않고 더 좋은 성능을 추출하였습니다.
따라서 CBHG가 정말 음성에 적합한 구조였는지 다시한번 고민해 봐야 될것 같습니다.
성능을 향상시킨 가장 큰 요인은 텍스트로부터 mel-spectrogram을 생성하는 단계가 아니라 Vocoder(WaveNet) 에 있습니다.
즉 타코트론1+WaveNet 과 타코트론2+WaveNet은 큰 차이가 없습니다.
하지만 WaveNet으로부터 생성된 음성의 품질은 뛰어나지만 너무 느리다는 단점을 갖고 있습니다.
따라서 실시간으로 음성을 생성하기에는 보안이 필요해 보입니다.
타코트론2 세미나 영상 을 제작하였습니다. 또한 실제 목소리와 타코트론2로 생성한 목소리를 비교할 수 있도록 타코트론2로 만든 세미나 영상 도 제작하였습니다. 영상 제작으로 사용된 음성모델은 타코트론2 + WaveGlow 입니다. Pytorch Github 에서 음성모델 개발에 필요한 아키텍처를 제공하고 있습니다.
Reference
- [PAPER] Natural TTS Synthesis By Conditioning WAVENET On Mel Spectrogram Predictions, Jonathan Shen at el.
- [PAPER] Tacotron2 기반 한국어 음성 합성 모델 개발과 한국어에 맞는 Hyper-parameter 탐색
- [BLOG] Tacotron2 voice synthesis model explanation & experiments, Ellie Kang
- [BLOG] Tacotron2 Practical Use
- [BLOG] Tacotron-2 : Implementation and Experiments
- [BLOG] An Explanation of Discretized Logistic Mixture Likelihood, Hao Gao
- [BLOG] Natural TTS Synthesis Experiment, Francisco Ingham
- [BLOG] Bahdanau Attention 개념 정리
- [BLOG] Luong Attention 개념 정리
- [GITHUB] Tacotron2 Pytorch Implementation