[코드리뷰] - Unsupervised Data Augmentation for Consistency Training, NeurIPS 2020
딥러닝은 다양한 분야에서 기존 방법론 보다 좋은 성과를 보여주고 있습니다. Machine Translation, Sentiment Analysis, Question And Answering(Q&A) 등 일부 자연어처리 분야에서는 전통적인 방법론 보다 월등히 앞선 성능을 보이고 있습니다. 따라서 기업들이 앞 다투어 딥러닝을 다양한 분야에 적용하고 서비스를 출시하려고 노력하고 있습니다. 하지만 안타깝게도 딥러닝이 적용된 서비스는 생각보다 찾아보기 힘들며 그 품질 역시 소비자를 만족시키기에 부족합니다.
품질하락의 다양한 이유가 있지만 딥러닝 관점에서 이유를 찾아보면 근본적인 문제는 해당 분야에 대한 Labeled 데이터가 부족하다는 것입니다. 일반적으로 딥러닝 모델를 학습하기 위해서는 많은 Labeled 데이터가 필요합니다. 데이터의 양은 딥러닝 모델의 성능과 비례관계가 있기 때문에 얼마나 데이터를 확보했는가에 따라 딥러닝 모델의 성능이 달라집니다. 따라서 다양한 분야에 딥러닝을 적용하여도 Labeled 데이터가 부족하기 때문에 좋은 성능의 모델을 만들 수 없습니다.
이를 해결하기 위하여 다양한 Semi-supervised Learning 방법론이 연구되고 있습니다.
이 방법론은 Labeled 데이터 뿐만 아니라 Unlabeled 데이터를 활용하여 모델의 성능을 향상시키는 방법입니다.
오늘 포스팅에서는 최근 Semi-superivsed Learning 방법론 중 좋은 성능을 보이고 있는 UDA 에 대해 다루도록 하겠습니다.
이 글은 Unsupervised Data Augmentation for Consistency Training 논문을 참고하여 정리하였음을 먼저 밝힙니다.
논문을 간단하게 리뷰하고 pytorch 라이브러리를 이용하여 코드를 구현한 내용을 자세히 설명드리겠습니다.
논문 그대로를 리뷰하기보다는 생각을 정리하는 목적으로 제작하고 있기 때문에 실제 내용과 다른점이 존재할 수 있습니다.
혹시 제가 잘못 알고 있는 점이나 보안할 점이 있다면 댓글 부탁드립니다.
Short Summary
이 논문의 큰 특징 3가지는 아래와 같습니다.
- Vision, NLP 분야에서 효과적인 Data Augmenation 방법론을 제시하고 이를 Semi-superivsed Learning에 활용합니다.
- Consistency Loss와 Supervised Loss를 이용하여 모델을 학습하는 Semi-supervised Learning 방법론을 제안합니다.
- Labeled 데이터를 10% 정도 사용하여도 해당방법론이 Fully Superivsed 방법론 보다 좋은 성능을 보일 수 있다는 것을 실험적으로 증명하였습니다.
논문 리뷰
해당 논문에서는 제시한 방법론을 두가지 분야(NLP, Vision) 에 적용하고 실험결과를 제시합니다.
이 글에서는 UDA 방법론을 NLP에 적용하는 방법에 대해 자세하게 다루기 위하여 Vision에 대한 내용은 포함하고 있지 않습니다.
따라서 Vision 분야에 UDA를 적용하는 방법을 알고 싶으신 분들은 Youngerous BLOG 를 참조하시기 바랍니다.
Overview
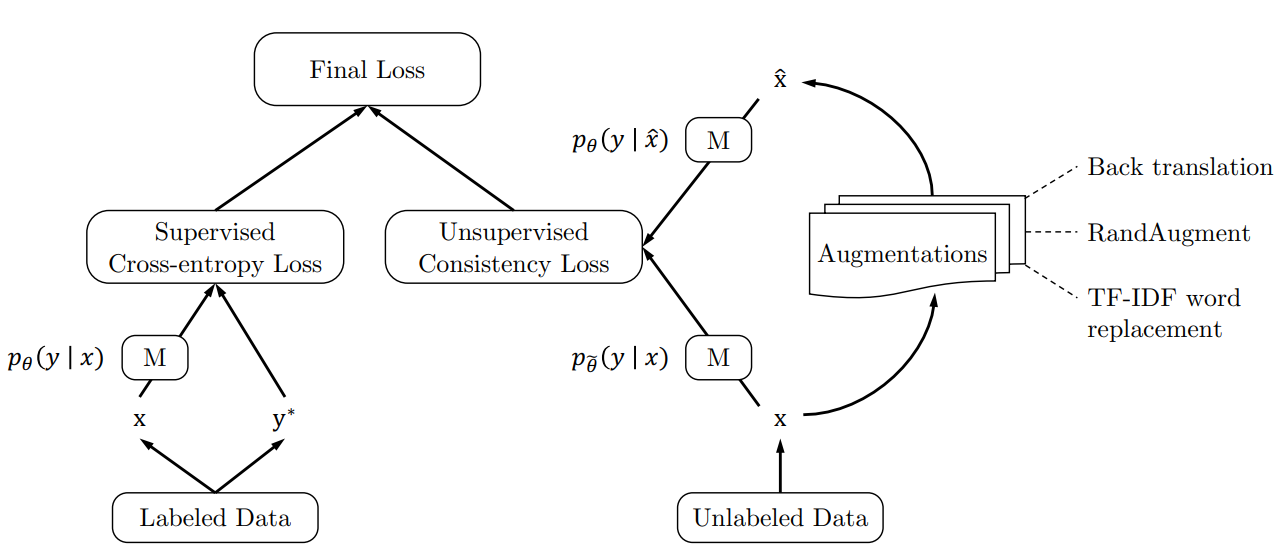
UDA는 Labeled 데이터와 Unlabeled 데이터를 함께 학습에 활용하는 Semi-supervised Learning 방법론입니다. Labeled 데이터를 활용하여 Supervised Loss를 구성하고 Unlabeled 데이터를 이용하여 Consistency Loss를 구성합니다. 이 두개의 Loss를 합쳐서 Final Loss를 구성하고 이를 학습에 활용합니다.
Supervised Loss는 일반적인 분류 학습에 활용하는 Cross_entropy Loss이므로 Labeled 데이터의 문장 $x_l$와 라벨 $y$가 있으면 쉽게 구성할 수 있습니다. 반면 Consistency Loss를 만들기 위해서는 두개의 의미가 비슷한 문장이 필요합니다. 따라서 Unlabeled 데이터의 문장 $x_u$ 뿐만 아니라 $x_u$와 비슷한 의미를 지니지만 문법적, 단어의 표현이 다른 문장 $\hat{x_u}$을 생성해야 합니다. UDA 방법론은 Back Translation, TD-IDF 등의 Data Augmentation 방법을 제시합니다.
Data Augmentation을 통해 생성된 문장을 분류모델에 넣으면 특정 라벨에 속할 확률분포를 추출할 수 있습니다.
또한 원본 문장을 분류모델에 넣으면 특정 라벨에 속할 확률분포를 추출할 수 있습니다.
이 두 분포의 차이인 KL Divergence $D( p_{\tilde{\theta}}(y|x_2)) || p_{\theta}(y|\hat{x})) )$ 를 계산하여 Consistency Loss로 활용합니다. 이 방법을 활용하면 적은 Label 데이터와 많은 Unlabeled 데이터로 좋은 성능을 도출할 수 있습니다.
[1] Consistency Loss
Consistency Loss를 자세하게 이해하기 위해서는 Unsupervised Data Augmentation과 Consistency Training에 대해 이해해야 합니다. 따라서 가볍게 관련내용을 리뷰하면서 본 논문에서 Consistency Loss를 어떻게 구성하였는지 살펴보도록 하겠습니다.
Unsupervised Data Augmentation
Data Augmenation은 원본 데이터를 이용하여 인공 데이터를 생성하는 방법을 의미합니다. 일부 단어를 변경하거나 문법 및 문장의 내용을 수정하여 데이터를 증강하는 등의 다양한 방법들이 있습니다.
일반적으로 Data Augmentation은 단순히 데이터를 증강하는 것이 아니라 원본 데이터와 표현은 다르지만 유사한 의도(label)을 갖고 있는 데이터를 생성하는 것이 목표입니다. 따라서 label을 보존하면서 데이터를 생성하는 방법에 대해 최근에 다양한 방법론들이 연구되고 있습니다.
Data Augmenation과 관련된 세미나 영상 입니다. Data Augmentation에 대해 궁금하신 분들은 참고 바랍니다.
본 논문에서는 다양한 NLP Data Augmenation 방법중에서 Back-translation을 활용합니다. Back-translation은 번역기 두개를 이용하여 인공 문장을 생성하는 방법입니다.
![]()
Back-translation을 하기 위해서는 두개의 번역기가 필요합니다. 예를들어 위 그림에서 번역기A는 언어1(한글)에서 언어2(영어)로 번역해주는 Seq2Seq 모델이고, 번역기B는 언어2(영어)에서 언어1(한글)로 번역해주는 Seq2Seq 모델입니다. Back-translation 과정은 원본문장을 번역기A에 넣고 그 번역된 문장을 번역기B에 넣어 새로운 문장을 생성하는 것을 의미합니다. 번역기의 품질이 매우 뛰어나더라도 언어간 미묘한 간극에 의하여 번역이 달라질 수 있으며 동일한 의미를 지니더라도 번역기의 학습데이터에 따라 다르게 표현될 수 있습니다. 즉 원본문장과 의미, 의도(label)는 비슷하지만 표현이 다른 인공문장을 생성할 수 있습니다.
본 논문에서는 원본문장과 인공문장의 차이(diversity)를 크게 하기 위하여 번역기B에 temperaturesSampling 방법을 적용합니다. temperature sampling 이란 번역기의 Decoder에서 생성된 단어의 생성 확률을 특정 비율(temperature)로 조정한 다음 sampling 방법을 이용하여 문장을 번역하는 것을 의미합니다.
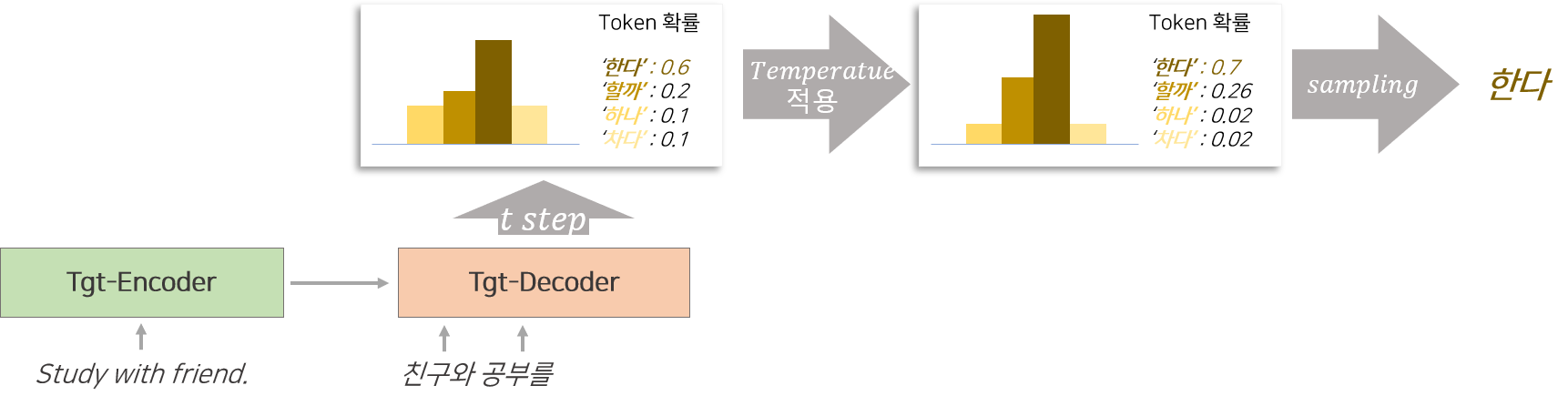
좀더 구체적으로 설명해보자면 번역기는 일반적으로 Encoder와 Deocder로 구성된 Sequence to Sequence 모델입니다. 문장을 넣으면 Encoder는 문장의 정보를 압축하고 Deocder는 autoregressive하게 매 시점 특정 token(단어)이 현 시점에서 등장할지에 대한 점수가 추출됩니다. 추출된 점수에 Softmax 함수를 적용하면 각 단어가 등장할 확률을 계산할 수 있습니다. 이때 temperature 적용하면 확률을 변화시킬 수 있습니다.
$p_i$ : 번역기 decoder에서 추출된 단어 $i$가 등장할 확률
$s_i$ : 번역기 decoder에서 추출된 단어 $i$가 등장할 확률과 관련된 점수
$\hat{p_i}$ : temperature가 적용된 단어 $i$가 등장할 확률
$\tau$ : temperature를 의미하며 사용자 설정 파라미터
temperature가 1보다 작으면 등장할 확률이 높은 단어의 확률을 높이는 역할을 하며 temperature가 1보다 크면 등장할 확률이 낮은 단어와 높은 단어의 차이를 적게 하는 역할을 합니다. 따라서 temperature를 증가시켜 sampling하면 다양한(Diversity) 문장을 생성할 수 있으며, temperatue를 감소시켜 sampling하면 문법에 비교적 맞는(robust) 문장을 생성할 수 있습니다.
본 논문에서는 temperature를 0.9로 고정하고 Back-translation을 이용하여 인공문장을 생성합니다.
Consistency Training
Consistency Training 이란 모델이 데이터의 작은 변화에 민감하지 않게(Robust) 만드는 방법입니다. 작은 변화란 사람이 봤을 때 label에 큰 영향을 주지 않을 정도의 noise를 의미합니다.
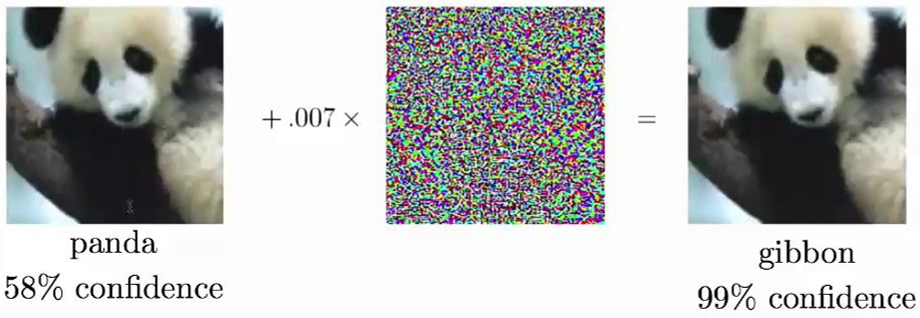
예를 들어 팬더의 그림이 있을 때 Gaussian Noise를 추가할 경우 사람이 봤을 때는 여전히 팬더라고 대부분 생각합니다. 반면 딥러닝 모델은 사람과는 다르게 이러한 미묘한 변화를 크게 받아들이며 분류 모델인 경우 팬더가 아닌 다른 것으로 예측합니다. 이를 극복하기 위하여 일반적으로 Regulization Term을 추가하거나 변형한 데이터가 원본의 Label을 예측할 수 있도록 학습하여 Consistancy Training을 적용합니다. Semi-supervised Learning에서 Consistency Tranining 은 조금 다른 뜻으로 활용됩니다. Unlabeled 데이터를 모델 학습에 활용하기 위하여 노이즈가 추가된 데이터와 추가되지 않은 데이터가 동일한 label을 갖어야 한다는 Consistaency Training의 아이디어를 활용합니다.
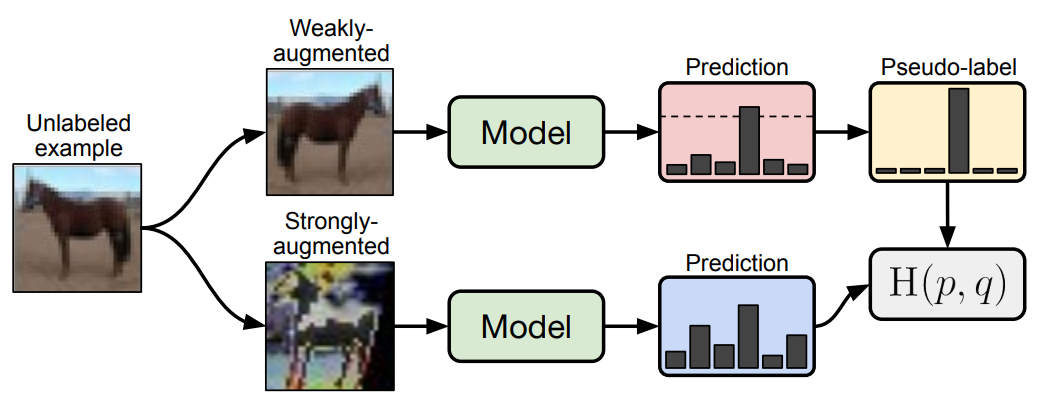
위 그림은 FixMatch의 Consistency Traning 예시입니다. Unlabeled 데이터를 이용하여 Strong Augmented 데이터와, Week Augmented 데이터를 만듭니다. 그리고 구축한 딥러닝 모델에 넣어 각 데이터가 어떤 것을 예측하였는지 확률을 추출합니다. 이 확률을 기반으로 두 augmented 데이터의 label이 같도록 학습하는 것이 semi-supervised Learning에서 Consistency Training을 활용하는 방법입니다.
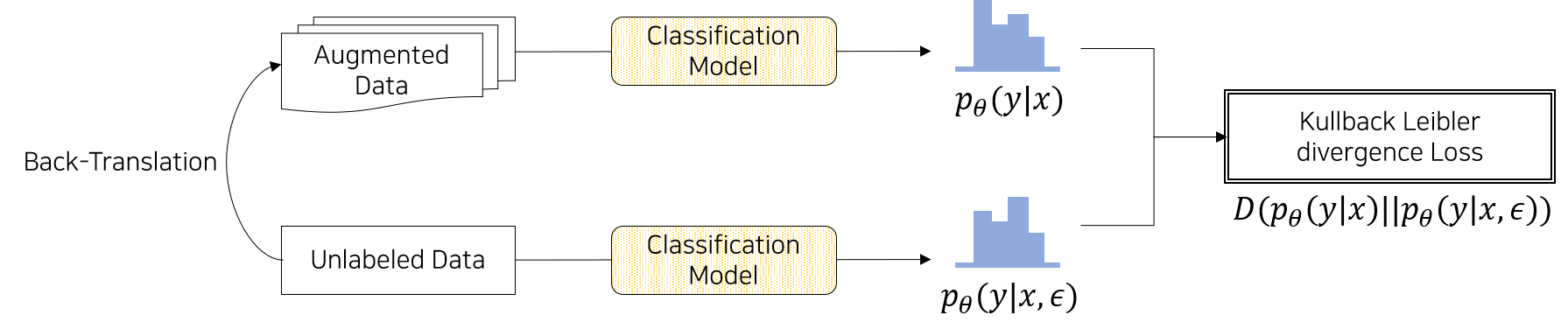
본 논문 역시 noise가 추가된 문장과 원본 문장(Raw Data)의 label이 같도록 학습하는 방식으로 Consistency Training을 적용합니다. 여기서 Noise가 추가된 문장은 Back-translation을 이용하여 원본 데이터로부터 생성된 인공문장을 의미합니다. 두 데이터를 동일한 모델에 넣고 각각 확률분포를 추출한 다음 두 분포가 일치하도록 KL-Divergence를 이용하여 Loss를 구성하고 학습합니다. 즉 두 데이터의 확률분포를 일치 시킴으로써 미세한 Noise와 관계 없이 두 데이터가 동일한 Label을 예측하도록 조정하는 것으로 생각할 수 있습니다.
Consistency Loss의 식은 아래와 같습니다.
$\epsilon$ : 인공 문장을 생성할 때 삽입된 Noise
$p_{\theta}(y|x)$ : 원본 문장의 분류 확률 분포
$p_{\theta}(y|x,e)$ : 인공 문장의 분류 확률 분포
[2] Final Loss
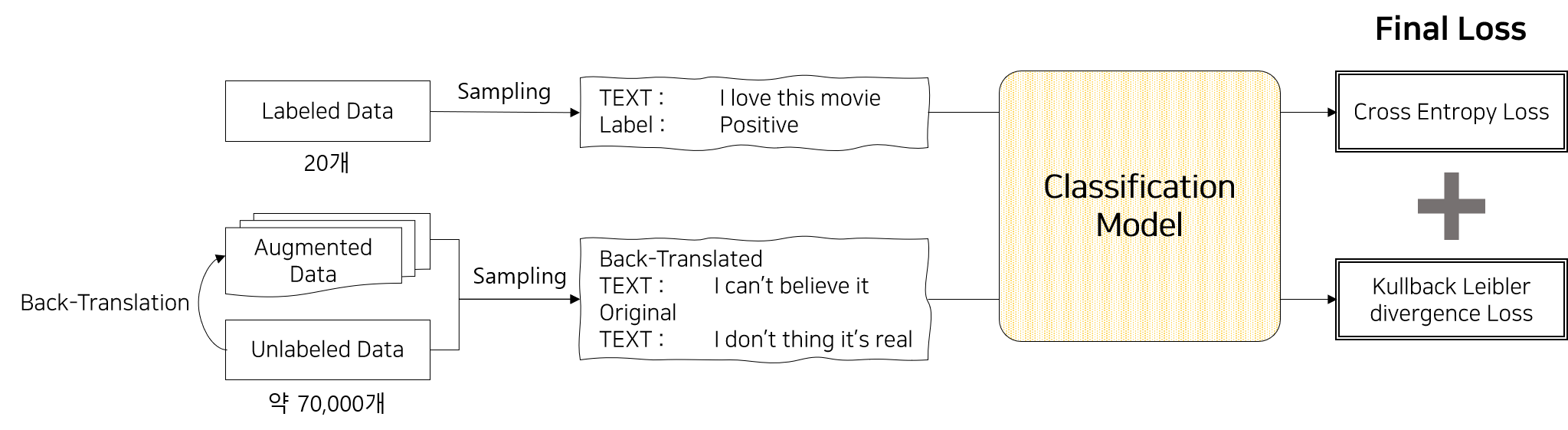
위 overview에서 설명한 내용을 구체적인 예시와 함께 리마인드 해 보도록 하겠습니다. UDA에서 제시한 방법론의 핵심은 Label 데이터로는 Supervised Loss를 구성하고 Unlabeled 데이터로는 Consistency Loss를 구성한 후 이 두개의 Loss를 합하여 모델을 학습하는 것입니다.
Label 데이터로 Supervised Loss를 만드는 방법은 일반적인 Cross-Entropy Loss를 만드는 방법과 같습니다. Label 데이터의 문장 $x_1$을 모델에 넣어 실제 라벨인 $y_1$ 에 대한 확률 $p_{\theta}(y_1|x)$를 추출하고 이를 이용하여 Cross-Entropy Loss인 $-log p_{\theta}(y_1|x_1)$ 를 구성합니다. 논문에서는 극단적으로 적은 Label 데이터를 이용하여 학습에 활용합니다. 예를들어 IMDB 데이터(Movie Sentiment Analysis)의 경우 20개만을 사용합니다. 즉 매 batch iteration 마다 전체 20개의 데이터로부터 batch sampling 하여 학습에 활용합니다.
Unlabel 데이터로 Consistency Loss를 구성하는 방법은 원본데이터와 인공데이터 사이의 KL-Divergence Loss를 계산하는 것 입니다. TD-IDF, Back Translation 등을 활용하여 Unlabel 데이터의 문장 $x_2$으로부터 인공 문장 $\hat{x}$ 을 생성합니다. 원본문장 $x_2$를 파라미터 $\tilde{\theta}$ 가 고정되어 있는 모델에 넣어 $p_{\tilde{\theta}}(y|x_2))$ 를 추출합니다. 그리고 인공문장 $\hat{x}$를 모델에 넣어 $p_{\theta}(y|\hat{x}))$ 를 추출합니다. Consistency Loss를 구성하는 이유는 인공문장으로부터 추출된 확률 분포를 원본문장에서 추출된 확률 분포와 일치시키기 위함입니다. 따라서 원본문장의 확률 분포를 고정시키기 위하여 원본문장의 분포를 추출할 때 모델의 파라미터를 고정시킵니다. 이를 통해 인공문장으로만 학습 효과(gradient)가 흐르게 함으로써 원본문장의 확률 분포는 고정시키고 인공문장의 확률 분포를 변화시킵니다.
추출된 두 분포의 차이 Metric인 KL-Divergence는 $KL( p_{\tilde{\theta}}(y|x_2)) || p_{\theta}(y|\hat{x})) )$ 를 계산하여 차이를 줄이도록 학습합니다. KL Divergence를 최소화 하는 것은 Cross Entropy를 최소화 하는것과 같으므로 해당 식은 아래와 같이 변경될 수 있습니다.
위에서 도출한 Supervised Loss와 Consistency Loss를 합한 Final Loss는 아래와 같습니다.
$\lambda$ 는 Final loss에 대한 Supervised Loss와 Consistency Loss의 기여도를 조절하는 파라미터이며 논문에서는 1로 고정하고 실험을 진행합니다.
[3] Training Techniques
Semi-superivsed Learning은 Supervised Learning 보다 학습이 매우 불안정합니다. Labeled 데이터의 개수가 매우 적기 때문에 명확한 방향을 갖고 학습할 수 없기 때문입니다. 또한 학습하는 동안에는 모델이 Unlabeled 데이터에 대해 잘 예측하지 못하므로 이를 학습에 그대로 사용하는 것은 모델이 수렴하지 못하게 하는 역할을 합니다. 따라서 몇가지 학습 테크닉이 함께 활용됩니다.
본 논문에서는 총 3가지 학습 테크닉을 제시합니다.
- Training Signal Annealing : 상대적으로 적은 Labeled 데이터에 모델이 빠르게 과적합되지 않도록 방지하는 방법
- Confidence-based masking : 모델의 예측 확률에 기반하여 확실한 Unlabeled 데이터만 이용하는 방법
- Sharpening Prediction : Unlabeled 데이터의 확률분포를 변형하여 Consistency Loss를 증가시키는 방법
A. Training Signal Annealing
일반적으로 Semi-Supervised Learning은 적은 Labeled 데이터와 많은 Unlabeled 데이터를 활용하여 학습합니다. 두 데이터를 동일하게 고려하여 학습하면 모델이 적은 Labeled 데이터를 보는 횟수가 많으므로 빠르게 Labeled 데이터에 과적합 될 것입니다. 충분하게 Unlabeled 데이터를 보지 못한 모델은 Unlabeld 데이터에는 과소적합 되어 성능의 향상의 한계가 있으므로 이를 해결하고자 본 논문에서 Training Signal Annealing 방법을 제안합니다.
Training Signal Annealing은 학습시간과 Labeled 데이터에 대한 모델의 예측 정확도를 이용하여 Labeled 데이터의 학습 양을 조절하는 방법입니다. 즉 특정 example(문장)에 대해 모델의 class 예측 성능이 놓은 경우 iteration에 따라 Update를 하지 않게 함으로써 학습초기에 Labeled 데이터에 overfitting 되지 않게 합니다.
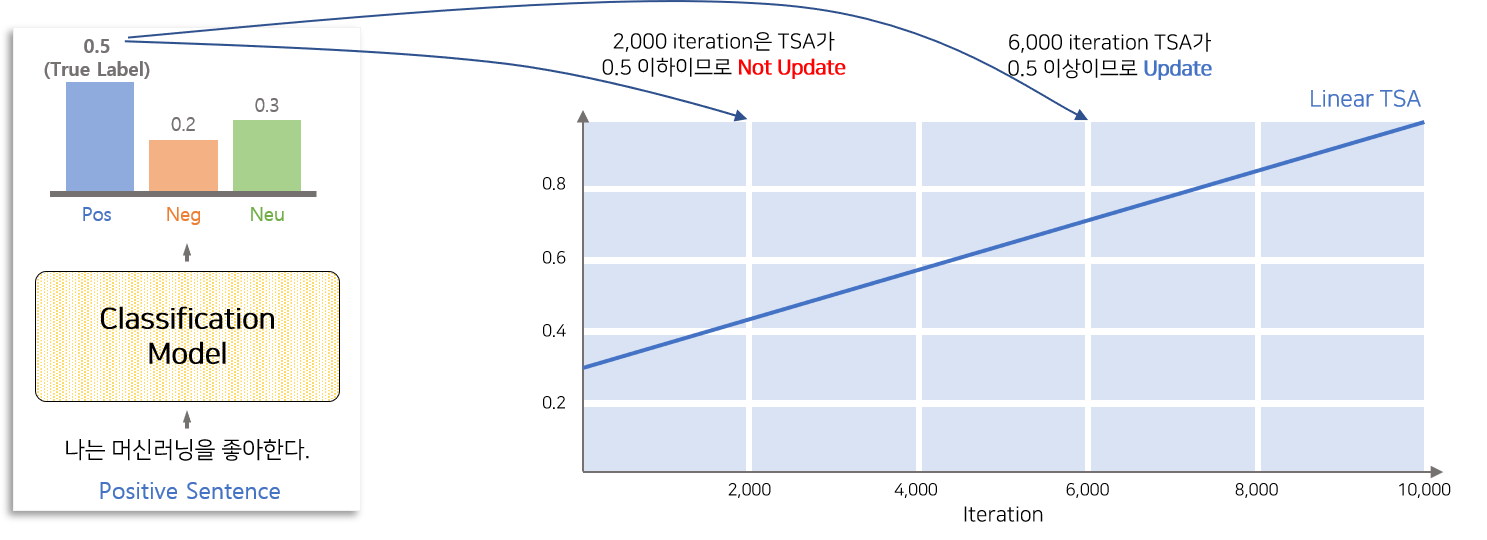
위의 예시는 Linear TSA를 이용하여 Label 데이터의 학습 양을 조절하는 방식을 설명한 그림입니다. 학습 기간동안 모델에 Labeled 데이터인 “나는 머신러닝을 좋아한다” 라는 문장을 넣어 각 Class에 대한 확률을 추출합니다. 모델의 학습 정도에 따라 각 Class에 대한 확률값이 변하게 되며 Label 데이터를 잘 학습한 모델일 수록 추출된 Class 확률에서 실제 Class에 대한 확률이 높을 것입니다.
그래프의 TSA가 의미하는 것은 모델로부터 추출된 실제 Class에 대한 확률이 TSA 선 이하이면 Update를 하고 그렇지 않으면 Update에 활용하지 않는 것입니다. 즉 2,000 Step에서는 TSA 선이 모델에서 추출된 실제 Class에 대한 확률(0.5) 보다 이하이므로 해당 문장으로 부터 발생된 Loss는 Update 하지 않습니다. 반면 6,000 Step에서는 TSA 선 상향되었으므로 해당지점에서는 Loss를 Update합니다.
직관적으로 TSA의 작동원리를 이해해보면 Label 데이터에 대해 모델이 잘 예측하지 못할 때에만 올바른 방향만 알려주어 모델의 학습이 잘 되도록 하는 장치로써 작동한다고 생각할 수 있습니다. TSA의 모양은 예제에서 설명한 선형(linear)이나 로그함수, 지수함수 형태로 구성할 수 있습니다.
B. Confidence-based masking
Consistency Training는 Unlabeled 데이터의 확률 분포와 노이즈가 포함된 Unlabeled 데이터의 확률 분포가 일치하도록 학습시키는 방법입니다. 따라서 모델로부터 추출된 Unlabeled 데이터의 확률 분포가 올바르게(실제 라벨에 맞게) 추출되어야 노이즈가 포함된 Unlabeled 데이터의 확률 분포를 올바른 방향으로 학습 시킬 수 있습니다. 일반적으로 학습 초기에는 모델의 예측 정확도가 매우 낮기 때문에 모델로부터 추출된 Unlabeled 데이터의 확률분포가 틀릴 확률이 높습니다. 또한 초기에 잘못 인도된 학습방향이 모델을 수렴하지 못하게 할 수 있습니다.
이를 방지하고자 모델이 확신을 갖고 있는 데이터에만 Consistency Training을 적용합니다. 즉 모델에 Unlabeled 데이터를 넣어 확률 분포를 추출하고 특정 Class를 높은 확률로 에측하는 데이터에 한에서 Loss를 구성하여 학습에 활용하는 것입니다. 이 방법은 모델이 애매모호하게 예측한 데이터는 신뢰성이 없다고 판단하고 배재하는 것입니다.

$Confidence_Beta$ 가 0.5 라고 하면 Unlabeled 데이터 중 모델에서 추출된 Major 확률이 0.5 이상인 것만 학습에 활용합니다. 즉 모델로부터 추출된 확률값 중 가장 큰 값이 0.5 이상인 데이터만을 이용하여 Consistency Loss를 구성합니다.
C. Sharpening Prediction
Consistency Loss는 Superivsed Loss에 비해 일반적으로 매우 작습니다. 그 이유는 모델로부터 추출한 노이즈가 포함된 Unlabeled 데이터의 확률분포와 노이즈가 없는 Unlabeled 데이터의 확률분포가 크게 차이 나지 않기 때문입니다. 이 때문에 때로는 수렴이 느리고 Loss가 Outlier에만 민감하게 반응하여 커질 수 있다는 단점을 갖고 있습니다.
따라서 Confidence가 높은 Unlabeled 데이터에 대해서는 확률분포의 차이를 크게 만들어 학습시키는 방식이 도움이 될 수 있습니다. Sharpening Prediction은 모델로부터 추출된 Logits을 Softmax 함수를 이용하여 확률분포로 변형하기 전에 $\tau$ 로 나누는 작업을 추가합니다. $\tau < 1$ 일 경우 추출된 확률분포는 $\tau$를 적용하기 전 확률분포보다 각 Class 끼리 차이가 커집니다. 반면 $\tau > 1$ 인 경우 추출된 확률 분포는 $\tau$를 적용하기 전 확률분포보다 각 Class 끼리 차이가 작아집니다.
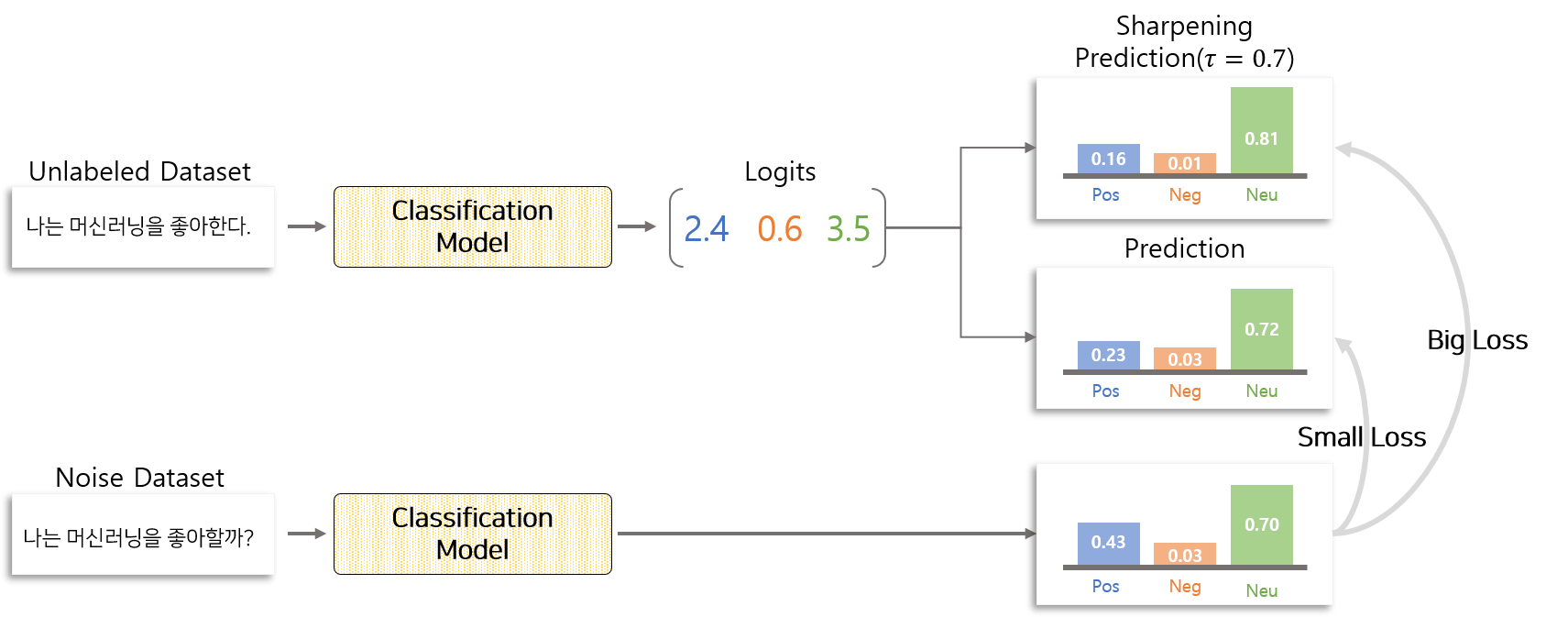
Sharpening Prediction은 $0< \tau < 1$ 사이의 $\tau$를 적용하여 각 Class 끼리의 차이가 커지게 함으로써 Consistency Loss를 증가 시킵니다.
Confidence가 높은 Unlabeled 데이터에만 적용하기 위하여 앞서 설명한 Confidence-based masking을 함께 사용하는 것이 합리적인 것 같습니다.
코드 구현
본 튜토리얼은 UDA 논문에서 제시한 방법론을 재현하는데 초점을 맞추고 있습니다. 논문에서 제시한 실험 중 일부분에 해당하는 강성분석(Sentiment Analysis Task)에서 해당 방법론이 효과가 있는지 확인하고 논문 재현이 가능한지 평가합니다.
데이터
![]()
튜토리얼에서 사용할 데이터는 IMDB Sentiment Dataset 입니다.
IMDB 데이터는 영화 감상을 나타내는 문장과 영화에 대한 평가(0 or 1)를 포함하고 있습니다.
총 100,000개의 데이터로 이루어져 있으며 50,000은 Labeled 데이터이고 50,000은 Unlabeled 데이터 입니다.
Stanford 대학 공식 홈페이지 에서 Raw 데이터를 다운로드 받을 수 있도록 제공하고 있으나 편의상 datasets 라이브러리를 활용하여 데이터를 다운받고 활용합니다.
1
2
3
import datasets
data = datasets.load_dataset('imdb')
print(data['train']['text'][0])

위와 같이 load_dataset 함수를 이용하여 imdb 데이터를 호출하면 데이터가 cache로 남아 있을 경우 재활용하고 cache를 찾을 수 없는 경우 인터넷을 통해 자동으로 다운로드 받습니다.
데이터를 load한 후 출력하여 데이터가 잘 load 되었는지 확인해 봅니다.
코드 개발 Flow
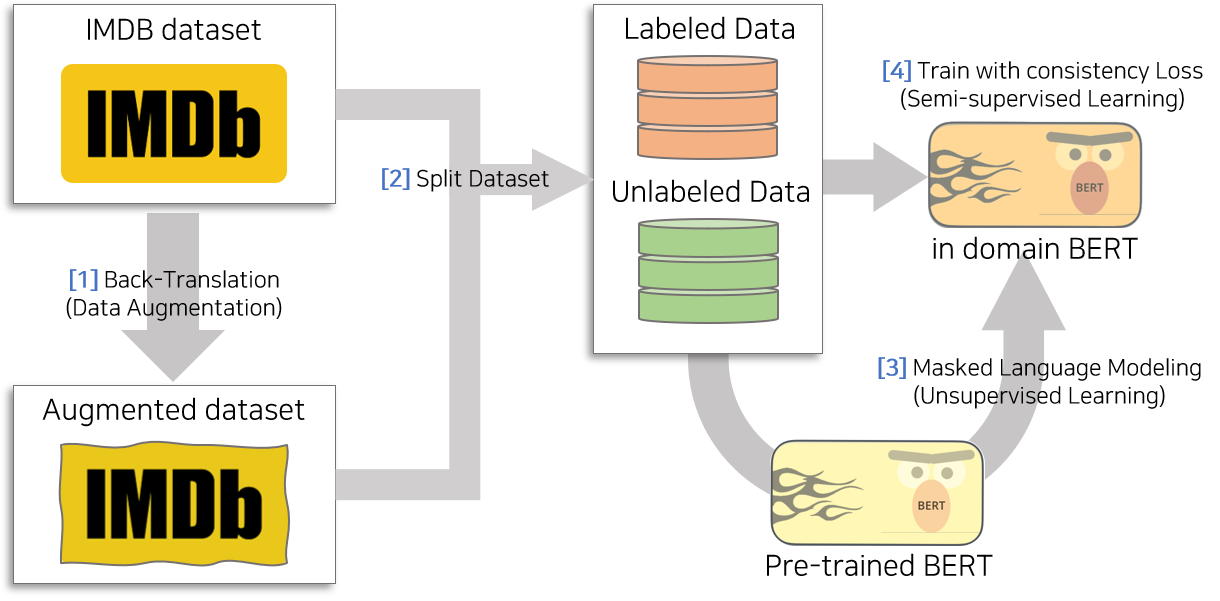
UDA 논문에서 제시한 성능을 온전히 구현하기 위해서는 총 4가지 과정이 필요합니다.
- Data Augmentation(Back-Translation)
- Data Split
- Masked Language Model Fine-tuning
- Semi-Supervised Learning(UDA)
1번 과정은 Back-Translation을 통해 인공데이터를 생성하는 단계입니다. 2번 과정은 Supervised loss를 구성할 학습용 데이터, Cosistency Loss를 구성할 학습용 데이터, 검증용 데이터를 분할하는 단계입니다. 3번 과정은 Pre-trained BERT(uncased)를 Masked Language Modeling를 이용하여 Unlabled 데이터에 학습시키고 Task에 Pre-trained 된 BERT 모델을 생성하는 단계입니다. 4번 과정은 인공데이터와 Pre-trained BERT 모델을 이용하여 Semi-superivsed Learning을 적용하는 단계입니다.
[1] Data Augmentation
UDA 방법을 적용하기 위해서는 Unlabeled 데이터의 인공데이터(augmented Data)가 필요합니다.
본 튜토리얼에서는 Back-translation을 이용하여 인공데이터를 생성하는 방법에 다룹니다.
튜토리얼의 Back-translation 에 해당하는 전체 코드는 back_translation.py 에서 참고하시기 바랍니다.
Back-translation 과정을 요약하면 다음과 같습니다.
A. 번역기 불러오기
B. IMDB 데이터 불러오기
C. IMDB 데이터 전처리
D. 문장 단위로 데이터 나누기
E. Back-Translation 데이터 생성
F. Back-Translation 데이터 저장
A. 번역기 불러오기
Back-translation을 활용하기 위하여 번역기 2개가 필요합니다. 번역기를 직접 만드는 것은 많은 자원과 시간이 필요하므로 torch hub에서 제공하는 번역기를 활용합니다. fairseq Github 에는 다양한 pytorch 구현체를 제공하고 있습니다. 이 안에는 WMT(World Machine Translation)에서 우승한 번역기의 구현체도 함께 제공하고 있습니다.
이 중에서 2019년 WMT 우승 모델 중 ‘wmt19.en-de’ 과 ‘wmt19.de-en’를 활용합니다. ‘wmt19.en-de’ 모델은 영어를 독일어로 번역해 주는 transformer 아키택처 번역기 입니다. ‘wmt19.de-en’ 모델은 독일어를 영어로 번역해 주는 transformer 아키택처 번역기 입니다. 이 두개의 모델을 이용하여 영어를 독일어로 그리고 다시 독일어를 영어로 번역하여 새로운 문장을 생성합니다. 번역기와 관련된 자세한 사항은 공식 Docs 를 참고바랍니다.
두 번역기를 불러오기 위하여 우선 기본 사항을 Setting 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
def build_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--save_dir",
default=None,
type=str,
required=True,
help="Save Directory",
)
parser.add_argument(
"--src2tgt_model",
default='transformer.wmt19.en-de.single_model',
type=str,
help="torch HUB translation Model(source->target)",
)
parser.add_argument(
"--tgt2src_model",
default='transformer.wmt19.de-en.single_model',
type=str,
help="torch HUB translation Model(target->source)",
)
parser.add_argument(
"--bpe",
default='fastbpe',
type=str,
help="torch HUB translation bpe option",
)
parser.add_argument(
"--tokenizer",
default='moses',
type=str,
help="torch HUB translation tokenizer",
)
parser.add_argument(
"--no_cuda",
action="store_true",
help="if you don't want to use CUDA"
)
parser.add_argument(
"--batch_size",
default=16,
type=int,
help="Back-translation Batch size"
)
parser.add_argument(
"--max_len",
default=300,
type=int,
help="Translation Available length"
)
parser.add_argument(
"--temperature",
default=0.9,
type=float,
help="Translation Available length"
)
args = parser.parse_args()
return args
기본사항에는 번역기로 사용할 모델의 이름(src2tgt_model, tgt2src_model)과 모델의 tokenizer(tokenizer) 등을 포함하고 있습니다.
위 setting된 정보를 토대로 torch.hub를 이용하여 번역기를 불러옵니다.
1
2
src2tgt = torch.hub.load("pytorch/fairseq", args.src2tgt_model, tokenizer=args.tokenizer, bpe=args.bpe).to(args.device).eval()
tgt2src = torch.hub.load("pytorch/fairseq", args.tgt2src_model, tokenizer=args.tokenizer, bpe=args.bpe).to(args.device).eval()
torch.hub는 pytorch에서 제공하고 있는 라이브러리로써 github와 연계하여 모델을 등록하고 등록되어 있는 구현체를 쉽게 다운로드 받을 수 있는 기능을 제공하고 있습니다.
따라서 모델의 정보(모델의 이름)와 옵션(tokenizer, bpe)을 이용하여 간단하게 번역기 모델을 불러옵니다.
번역기 모델이 Local에 저장되어 있으면 Local에서 불러오고 없으면 외부에서 다운로드 되도록 설정 되어 있기 때문에 간단한 load 명령어로 쉽게 사용할 수 있습니다.
torch.hub에 대한 글은 이곳 에서 참고 하시기 바랍니다.
B. IMDB 데이터 불러오기
1
2
3
4
5
6
data = datasets.load_dataset('imdb')
data_list = ['train', 'test', 'unsupervised']
for dataname in tqdm(data_list, desc='data name'):
temp_dataset = imdb_data[dataname]
temp_docs = temp_dataset['text']
temp_label = temp_dataset['label']
datasets 라이브러리에서 제공되는 IMDB 데이터는 ‘train’, ‘test’, ‘unsupervised’ 3가지로 나뉘어 저장되어 있습니다.
또한 각 데이터에는 ‘text’와 ‘label’을 포함하고 있습니다.
각 요소들을 불러오는 코드를 작성하여 번역할 문장(temp_docs)을 지정합니다.
C. IMDB 데이터 전처리
IMDB 데이터는 전처리 과정이 필요합니다. 그 이유는 IMDB 문장에는 HTML tag를 포함하고 있기 때문입니다. HTML tag를 삭제하지 않고 번역기에 넣으면 번역 품질이 떨어지기 때문에 전처리를 통해 문장에서 의미없는 성분을 삭제합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
## 문장 안에 있는 TAG를 삭제하는 코드
def clean_web_text(st):
"""
Adapted from UDA official code
https://github.com/google-research/uda/blob/master/text/utils/imdb_format.py
"""
st = st.replace("<br />", " ")
st = st.replace(""", '"')
st = st.replace("<p>", " ")
if "<a href=" in st:
while "<a href=" in st:
start_pos = st.find("<a href=")
end_pos = st.find(">", start_pos)
if end_pos != -1:
st = st[:start_pos] + st[end_pos + 1 :]
else:
st = st[:start_pos] + st[start_pos + len("<a href=")]
st = st.replace("</a>", "")
st = st.replace("\\n", " ")
return st
## IMDB 문장 안에 있는 TAG를 삭제
temp_docs = [clean_web_text(temp_sent) for temp_sent in temp_docs]
해당 코드는 google-research 에서 비공식으로 제공하고 있는 UDA 코드를 참고하여 개발하였습니다. 위 링크 를 통해 참고하시기 바랍니다.
D. 문장 단위로 데이터 나누기
일반적으로 근래에 개발되는 번역기는 Sequence to Sequence 구조를 갖고 있으며 auto-regressive 특징을 갖고 있습니다. 이 말은 위와 같은 번역기를 사용하면 번역을 할 때 Decoder에서 멈춤 조건이 발생하기 전 token을 한개씩 생성하는 한다는 것입니다. 만약 번역기가 충분히 학습되지 않았거나 입력으로 사용되는 문장이 문법적으로 오류가 있다면 Decoder에서 멈춤 조건이 발생하지 않을 수 있습니다. 위 원인은 번역기의 품질을 하락하게 하므로 일반적으로 번역기가 무제한의 길이로 번역문장을 생성하지 않도록 출력을 일정길이로 제한하는 post-processing 작업을 추가합니다. 이 과정 때문에 입력의 길이가 길더라도 출력의 길이가 일정 이상 늘어나지 않습니다.
IMDB는 데이터는 여려개의 문장으로 구성되어 있는 문단입니다. 따라서 데이터의 길이가 매우 길기 때문에 번역기에 넣어 번역하면 뒤에 위치한 문장은 번역이 되지 않는 현상이 있습니다. 이를 방지하기 위하여 데이터를 문장단위로 잘라서 번역한 후 번역된 문장을 다시 문단으로 합치는 작업을 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
def split_sent_by_punc(sent, punc_list, max_len):
"""
Adapted from UDA official code
https://github.com/google-research/uda/blob/master/back_translate/split_paragraphs.py
"""
if len(punc_list) == 0 or len(sent) <= max_len:
return [sent]
punc = punc_list[0]
if punc == " " or not punc:
offset = 100
else:
offset = 5
sent_list = []
start = 0
while start < len(sent):
if punc:
pos = sent.find(punc, start + offset)
else:
pos = start + offset
if pos != -1:
sent_list += [sent[start: pos + 1]]
start = pos + 1
else:
sent_list += [sent[start:]]
break
new_sent_list = []
for temp_sent in sent_list:
new_sent_list += split_sent_by_punc(temp_sent, punc_list[1:], max_len)
return new_sent_list
def split_sent(content, max_len):
"""
Adapted from UDA Official code
https://github.com/google-research/uda/blob/master/back_translate/split_paragraphs.py
"""
sent_list = sent_tokenize(content)
new_sent_list = []
split_punc_list = [".", ";", ",", " ", ""]
for sent in sent_list:
new_sent_list += split_sent_by_punc(sent, split_punc_list, max_len)
return new_sent_list, len(new_sent_list)
## IMDB 문장 안에 있는 TAG를 삭제
temp_docs = [clean_web_text(temp_sent) for temp_sent in temp_docs]
## IMDB 문장을 일정길이로 잘라 데이터를 생성
new_contents = []
new_contents_length = []
for temp_doc in temp_docs:
new_sents, new_sents_length = split_sent(temp_doc, args.max_len)
new_contents += new_sents
new_contents_length += [new_sents_length]
nltk 라이브러리에서 문단을 문장으로 잘라주는 sent_tokenize 라이브러리를 제공하고 있습니다.
따라서 sent_tokenize 함수를 이용하여 전처리된 문단을 문장으로 나눕니다.
라이브러리를 이용하여 문장으로 나누었음에도 불구하고 일부 문장은 여전히 번역하기에 긴 문제가 있습니다.
이를 해결하기 위하여 길이가 긴 일부 문장만 추출하여 특정 특수문자(“.”, “;”, “,”) 를 기준으로 다시 한번 나눕니다.
E. Back-Translation 데이터 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
backtranslated_contents = []
for contents in tqdm(batch(new_contents, args.batch_size), total=int(len(new_contents)/args.batch_size)):
with torch.no_grad():
translated_data = src2tgt.translate(
contents,
sampling=True if args.temperature is not None else False,
temperature=args.temperature,
)
back_translated_data = tgt2src.translate(
translated_data,
sampling=True if args.temperature is not None else False,
temperature=args.temperature,
)
backtranslated_contents += back_translated_data
일정 크기로 나눈 문장을 번역기의 translate 함수를 활용하여 번역합니다.
다만 다양한 문장을 생성하기 위해서 sampling과 temperature 기능을 활용합니다.
translate 함수에 옵션으로 sampling에 True와 temperature에 float type의 값을 넣으면 temperature Sampling이 가능합니다.
위 과정을 통해 인공데이터를 생성됩니다.
위 번역기를 이용하여 IMDB 데이터를 번역하는데 많은 시간이 소요됩니다. 2080ti 기준 train 데이터를 번역하는데 약 10시간이 소요됩니다.
F. Back-Translation 데이터 저장
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
merge_backtranslated_contents=[]
merge_new_contents = []
cumulate_length = 0
for temp_length in new_contents_length:
merge_backtranslated_contents += [" ".join(backtranslated_contents[cumulate_length:cumulate_length + temp_length])]
merge_new_contents += [" ".join(new_contents[cumulate_length:cumulate_length + temp_length])]
cumulate_length += temp_length
save_data = {
'raw_text' : temp_docs,
'label' : temp_label,
'clean_text' : merge_new_contents,
'backtranslated_text' : merge_backtranslated_contents,
}
save_path = os.path.join(args.save_dir, "{}.p".format(dataname))
save_pickle(save_path, save_data)
길이 정보를 이용하여 Back-translated 문장을 문단으로 합치고 저장하는 과정입니다.
.csv, .txt 포멧은 저장 용량을 많이 차지하며 쓰기, 읽기 속도가 느리다는 단점을 갖고 있습니다.
따라서 pickle을 라이브러리를 이용하여 byte 형태로 데이터를 저장합니다.
데이터는 ‘Back-translated 문장’ 뿐만 아니라 ‘라벨’, ‘원본 문장’, ‘전처리 된 원본 문장’ 을 포함하고 있습니다.

저장된 데이터를 살펴보면 ‘Back-translated 문장’과 ‘원본 문장’은 뜻은 비슷하지만 단어와 문법의 형태가 조금씩 다른 것을 확인할 수 있습니다. 이 데이터를 이용하여 이후 학습을 진행합니다.
[2] Data Split
튜토리얼의 Data Split 에 해당하는 전체 코드는 divide.py 에서 참고하시기 바랍니다.

Back-Translation을 통하여 인공데이터가 포함된 Labeled Dataset, Unlabeled Dataset, Test Dataset을 생성하고 저장하였습니다. 이 데이터를 supervised Loss 구성에 필요한 학습용 데이터, Consistency Loss 구성에 필요한 학습용 데이터, 검증용 데이터로 나누는 과정입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
def split_files(args):
assert os.path.isfile(args.label_file), 'there is no label files, --label_file [{}]'.format(args.label_file)
dirname, filename = os.path.split(args.label_file)
data = load_pickle(args.label_file)
## Split labeled data
train_idx, leftover_idx, _, leftover_label = train_test_split(list(range(len(data['label']))), data['label'],train_size=args.labeled_data_size, stratify=data['label'])
if len(leftover_idx) > args.valid_data_size:
valid_idx, unlabel_idx, _, _ = train_test_split(leftover_idx, leftover_label, train_size=args.valid_data_size, stratify=leftover_label)
else:
valid_idx = leftover_idx
unlabel_idx = []
train_data = dict((key, np.array(item)[train_idx].tolist()) for key, item in zip(data.keys(), data.values()))
valid_data = dict((key, np.array(item)[valid_idx].tolist()) for key, item in zip(data.keys(), data.values()))
unlabel_data = dict((key, np.array(item)[unlabel_idx].tolist()) for key, item in zip(data.keys(), data.values()))
## add unlabeled data
if args.unlabel_file is not None and os.path.isfile(args.unlabel_file):
additional_data = load_pickle(args.unlabel_file)
for key in unlabel_data.keys():
unlabel_data[key] += additional_data[key]
train_path = os.path.join(dirname, TRAIN_NAME.format(args.labeled_data_size, args.valid_data_size))
save_pickle(train_path, train_data)
try:
os.remove(os.path.join(dirname, "cache_" + TRAIN_NAME.format(args.labeled_data_size, args.valid_data_size)))
except:
pass
valid_path = os.path.join(dirname, VALID_NAME.format(args.labeled_data_size, args.valid_data_size))
save_pickle(valid_path, valid_data)
try:
os.remove(os.path.join(dirname, "cache_" + VALID_NAME.format(args.labeled_data_size, args.valid_data_size)))
except:
pass
augment_path = os.path.join(dirname, AUGMENT_NAME.format(args.labeled_data_size, args.valid_data_size))
save_pickle(augment_path, unlabel_data)
try:
os.remove(os.path.join(dirname, "cache_" + AUGMENT_NAME.format(args.labeled_data_size, args.valid_data_size)))
except:
pass
args.train_file = train_path
args.valid_file = valid_path
args.augment_file = augment_path
데이터를 나누는 코드는 다음과 같습니다. supervised 학습용 데이터는 label 정보가 필요합니다. 따라서 Labeled Dataset에서 일부를 sampling 하여 Supervised 학습용 데이터를 구성합니다.(IMDB는 20개를 사용) 검증용 데이터 역시 label 정보가 필요하므로 Labeled Dataset에서 3000개를 sampling하여 구성합니다.
나머지는 Consistency 학습용 데이터를 구성하는데 활용합니다. Consistency 학습용 데이터는 label 정보를 필요로 하지 않으므로 Unlabeled Dataset도 포함하여 데이터를 구성합니다.
Additional. 데이터 분할의 중요성
본 논문에서는 20 labled sample을 이용하여 좋은 성능을 낼 수 있다고 주장합니다. 개인적으로 이 주장은 반은 맞고 반은 틀리다고 생각합니다. 왜냐하면 20 labeled sample이 어떤 것이냐에 따라 성능의 차이가 커질 수 있기 때문입니다. 20개의 labeled sample은 모델 가중치에 가장 많은 영향을 미치는 데이터이며 학습 성능에 큰 영향을 끼칩니다. 따라서 초기에 좋은 20개의 sample을 선택하는 것이 중요합니다.
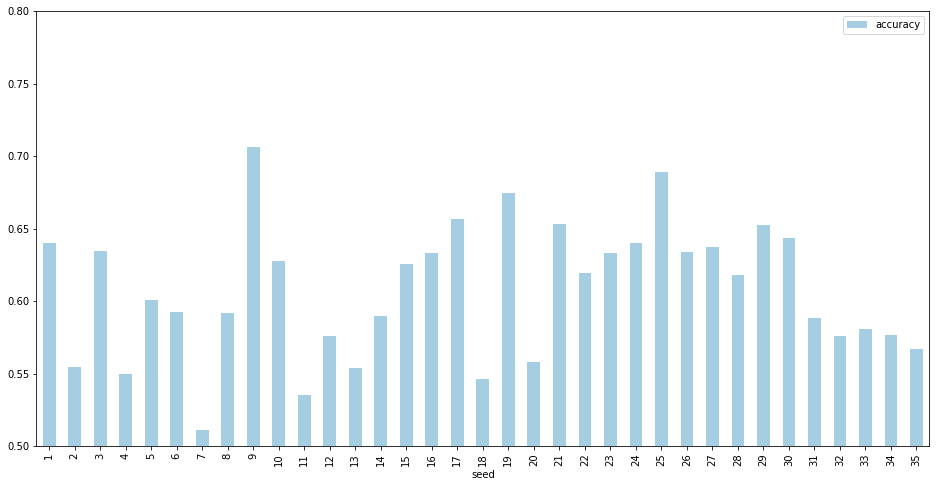
위 그림은 IMDB 20개의 labeled sample만 가지고 pre-trained BERT(bert-base-uncased)를 이용하여 학습한 결과입니다. seed의 변화에 따라 성능(Accuracy)가 크게 달라지는 것(0.511부터 0.706까지 변화)을 확인 할 수 있습니다. 즉 seed에 따라 서로 다른 20개의 sample이 추출되고 각 sample로 학습한 모델의 성능은 큰 차이를 보입니다.
UDA를 통해 학습이 잘 되지 않을 경우 seed에 따라 랜덤으로 선택된 sample이 유효한지 확인하는 과정이 필요해보입니다.
[3] Masked Language Model Fine-tuning
이 과정은 pre-trained BERT를 IMDB 데이터에 한번더 Masked Language Modeling(MLM)을 통해 학습시키는 과정입니다. BERT Paper 에 따르면 pre-tranined BERT는 다양한 도메인의 corpus로 부터 학습되었습니다. 즉 다양한 task에서 좋은 성능을 보이지만 특정 domain에 특화되어 있는 모델이 아닙니다. 따라서 pre-trained BERT를 IMDB 도메인에 unsupervised learning 방법론(MLM)으로 학습하여 domain-specific BERT 모델을 만들어 UDA에 활용합니다.
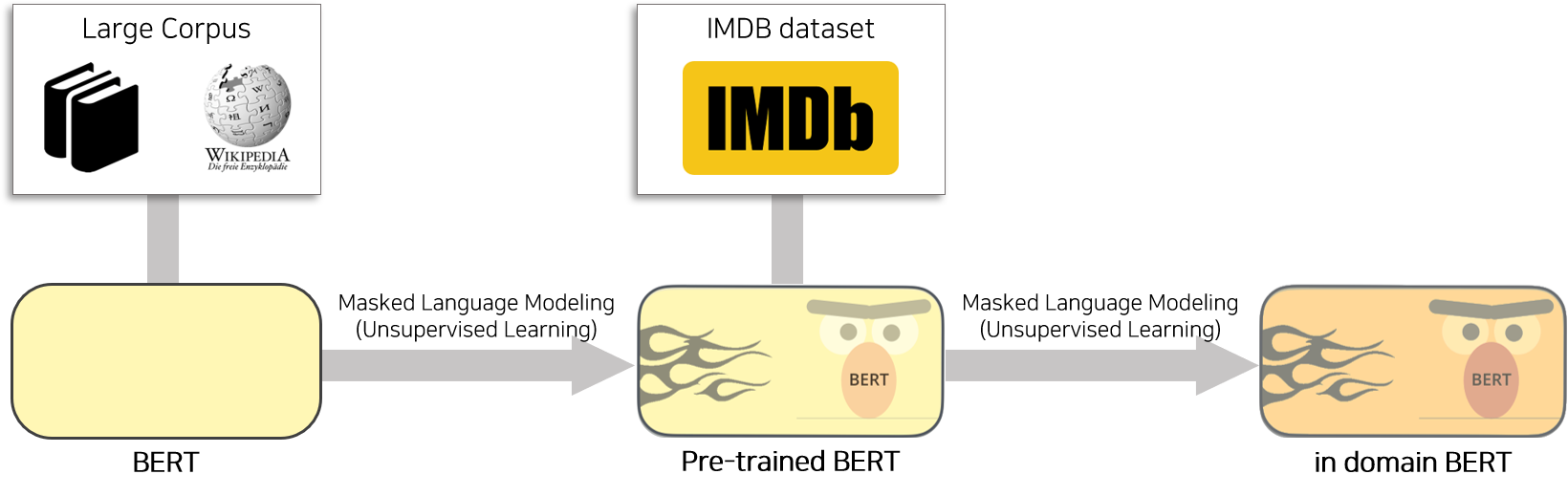
Masked Lanugage Modeling(MLM)과 관련된 코드는 huggingface Github 에서 제공하고 있습니다.
본 튜토리얼에서는 huggingface에서 제공하고 있는 example run_mlm.py 을 수정하여 제작하였습니다.
따라서 Masked Language Modeling 과 관련된 자세한 사항은 huggingface Docs 에서 확인하시기 바랍니다.
수정된 IMDB MLM에 해당하는 전체 코드는 train_mlm.py 에서 참고하시기 바랍니다.
[4] Train UDA
Back-translated 데이터를 이용하여 Supervised Loss와 Consistency Loss 구성하는 방법과 학습하는 방법에 대해 다루겠습니다.
튜토리얼의 Semi-Supervised Learning 에 해당하는 전체 코드는 train.py 에서 참고하시기 바랍니다.
Semi-Supervised Learning 과정의 중요한 부분을 요약하면 다음과 같습니다.
A. IMDB 데이터 전처리
B. Supervised Loss 구성
C. Consistency Loss 구성
D. 학습 및 결과 확인
A. IMDB 데이터 전처리
전처리 과정에는 문장을 token 형태로 자르고 one-hot encoding하는 과정을 포함하고 있습니다. token 형태로 자르기 위해서는 vocab을 포함한 tokenizer가 필요합니다. 본 튜토리얼 및 UDA 논문에서는 pre-trained BERT를 활용하므로 BERT와 함께 생성된 BertTokenizer를 이용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
class IMDBDataset(Dataset):
def __init__(self, file_path, tokenizer, max_len):
assert os.path.isfile(file_path), 'there is no file please check again. [{}]'.format(file_path)
self.max_len = max_len
dirname, filename = os.path.split(file_path)
cache_filename = "cache_{}".format(filename)
cache_path = os.path.join(dirname, cache_filename)
if os.path.isfile(cache_path):
logger.info("***** load cache dataset [{}] *****".format(cache_path))
## load cache file
label, text, augment_text = load_pickle(cache_path)
else:
logger.info("***** tokenize dataset [{}] *****".format(file_path))
data = load_pickle(file_path)
label = data['label']
text = data['clean_text']
augment_text = data['backtranslated_text']
logger.info("***** dataset size [{}] *****".format(str(len(text))))
## tokenizing
augment_text = [tokenizer.convert_tokens_to_ids(tokenizer.tokenize(t)) for t in augment_text]
augment_text = [tokenizer.build_inputs_with_special_tokens(t) for t in augment_text]
## one-hot Encoding
text = [tokenizer.convert_tokens_to_ids(tokenizer.tokenize(t)) for t in text]
text = [tokenizer.build_inputs_with_special_tokens(t) for t in text]
## save tokenized file
save_pickle(cache_path, (label, text, augment_text))
self.augment_text = augment_text
self.text = text
self.label = label
def __len__(self):
return len(self.label)
## 데이터 불러오기
def __getitem__(self, item):
## [원본문장] 길이가 길면 뒤에서부터 자르기
if len(self.text[item]) > self.max_len:
text = torch.tensor(
[self.text[item][0]]
+ self.text[item][-(self.max_len - 1): -1]
+ [self.text[item][-1]],
dtype=torch.long,
)
else:
text = torch.tensor(self.text[item], dtype=torch.long)
## [인공문장] 길이가 길면 뒤에서부터 자르기
if len(self.augment_text[item]) > self.max_len:
augment_text = torch.tensor(
[self.augment_text[item][0]]
+ self.augment_text[item][-(self.max_len - 1): -1]
+ [self.augment_text[item][-1]],
dtype=torch.long,
)
else:
augment_text = torch.tensor(self.augment_text[item], dtype=torch.long)
## label
label = torch.tensor(self.label[item], dtype=torch.long)
return text, augment_text, label
위 코드는 pytorch 라이브러리의 Dataset을 상속받아 만든 데이터셋 클래스입니다.
해당 클래스는 전처리 과정으로 tokenizing과 one-hot encoding을 포함하고 있습니다.
많은 문장을 tokenizing 하는 것은 상당히 긴 시간을 필요로 하므로 전처리 한 후 cache 형태로 저장합니다.
만일 cache 파일이 존재하면 전처리를 하지 않고 해당 파일을 읽어 시간을 단축할 수 있도록 설계하였습니다.
def __getitem__ 는 해당 클래스를 이용하여 데이터를 불러올 때 사용하는 함수입니다.
이 함수를 살펴보면 tokenizing 된 문장의 최대길이가 사용자가 지정한 수준(max_len)을 넘으면 뒤에서부터 자르도록 설정 되어 있습니다.
논문에서도 짧게 언급되었지만 IMDB의 경우 문장의 뒷부분을 이용하여 학습할 경우 성능이 더 좋기 때문에 다음과 같이 구성하였습니다.
B. Supervised Loss 구성
Semi-Supervised Learning은 학습단계에서 Supervised Loss와 Consistency Loss를 구성하여 학습합니다. Supervised Loss는 label 정보가 있는 Supervised 데이터를 이용하여 계산합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
## TSA 함수
def get_tsa_threshold(global_step, t_total, num_labels, tsa='linear'):
tsa = tsa.lower()
if tsa == 'log':
a_t = 1 - np.exp(-(global_step / t_total) * 5)
elif tsa == 'exp':
a_t = np.exp(-(1 / t_total) * 5)
else:
a_t = (global_step / t_total)
threshold=a_t * (1-(1/num_labels)) + (1/num_labels)
return threshold
## 학습 함수
def train(...):
...
## Supervised 데이터 생성
train_dataloader = DataLoader(
train_dataset, shuffle=True, batch_size=args.label_batch_size, collate_fn=collate
)
## loss function 생성
cross_entropy_fn = torch.nn.CrossEntropyLoss(reduction="none")
...
for labeled_batch in train_dataloader:
labeled_batch = tuple(t.to(args.device) for t in labeled_batch)
labeled_texts, _, labels = labeled_batch
label_outputs = model(input_ids=labeled_texts)
## get [CLS] token output
label_outputs = label_outputs[0]
## Supervised Loss 생성
cross_entropy_loss = cross_entropy_fn(label_outputs, labels)
if args.tsa is not None:
## Get tsa Threshold
tsa_threshold = get_tsa_threshold(global_step=global_step, t_total=t_total, num_labels=args.num_labels, tsa=args.tsa)
## selected Label prob
label_prob = torch.exp(-cross_entropy_loss)
## selected pro less then threshold
tsa_mask = label_prob.le(tsa_threshold)
cross_entropy_loss = cross_entropy_loss * tsa_mask
final_loss = cross_entropy_loss.mean()
...
CrossEntropyLoss 함수를 이용하여 모델에서 나온 결과와 라벨정보를 활용하여 supervised Loss를 계산할 수 있습니다.
학습 과정에서 Sueprvsied 데이터에 너무 overfitting 되지 않도록 TSA 기능을 적용하였습니다.
TSA를 적용하는 과정은 다음과 같습니다.
- 현재 iteration 기준으로 TSA threshold를 생성합니다.
- 모델로부터 추출된 정답 라벨의 확률을 계산합니다.
- 정답라벨의 확률이 threshold를 넘는 데이터에 대하여 0을 부여하고 그렇지 않으면 1을 부여하는 MASK를 생성합니다.
- MASK와 Supervised Loss를 곱하여 threshold를 넘은 데이터의 영향력을 없애줍니다.
C. Consistency Loss 구성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
def kl_divergence_fn(unlabeled_logits, augmented_logits, sharpen_ratio=1.0):
loss_fn = torch.nn.KLDivLoss(reduction="none")
return loss_fn(F.log_softmax(augmented_logits, dim=1), F.softmax(unlabeled_logits/sharpen_ratio, dim=1)).sum(dim=1)
## 학습 함수
def train(...):
...
## UnSupervised 데이터
unlabeled_dataloader = DataLoader(
unlabeled_dataset, shuffle=True, batch_size=args.unlabel_batch_size, collate_fn=collate
)
unlabeled_iter = iter(unlabeled_dataloader)
...
for labeled_batch in train_dataloader:
...
final_loss = cross_entropy_loss.mean()
...
## Unsupervised 데이터 불러오기
unlabeled_batch = next(unlabeled_iter)
unlabeled_batch = tuple(t.to(args.device) for t in unlabeled_batch)
unlabeled_texts, augmented_texts, _ = unlabeled_batch
##augment 데이터 확률분포 추출
augment_outputs = model(input_ids=augmented_texts)
augment_outputs = augment_outputs[0]
##unlabled 데이터 확률분포 추출
model.eval()
with torch.no_grad():
unlabeled_outputs = model(input_ids=unlabeled_texts)
## get [CLS] token output
unlabeled_outputs = unlabeled_outputs[0]
model.train()
## KL divergence 구성
consistency_loss = kl_divergence_fn(unlabeled_outputs, augment_outputs)
## confidence beta 적용
unlabeled_prob = F.softmax(unlabeled_outputs).max(dim=1)[0]
unlabeled_mask = unlabeled_prob.ge(args.confidence_beta)
consistency_loss = consistency_loss * unlabeled_mask
final_loss += args.uda_coeff * consistency_loss.mean()
...
Consistency Loss를 구성하기 위하여 인공문장(Augmented)과 원본문장(Unlabeled)이 필요합니다.
데이터 분할 과정에서 만든 Consistency 학습용 데이터로부터 인공문장과 원본문장을 불러온 후 모델에 넣습니다.
원본문장의 경우 모델에 Loss가 전파되지 않게 모델을 고정시켜야 합니다.
따라서 model.eval() 명령어와 with torch.no_grad(): 를 활용하여 해당 구간에서는 backpropagation이 되지 않도록 조치합니다.
모델을 활용하여 두 문장으로부터 추출된 확률분포를 kl_divergence_fn 함수를 넣으면 두 분포의 차이인 Consistency Loss를 계산할 수 있습니다.
계산한 Consistency Loss를 Final Loss에 바로 더하지 않고 Confidence를 확인합니다. 모델의 예측 실뢰도가 높은 데이터에 한에서 Loss를 구성하는 방식입니다.
기존 Supervised Loss에 Consistency Loss를 더하여 Final Loss를 구성합니다.
Cosistency Loss에 상수(uda_coeff)를 곱하여 전체 Loss에서 Supervised Loss와 Cosistency Loss의 비율을 조정합니다.
D. 학습 및 결과 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
## 학습하기
def run(...):
...
if args.do_train:
train_dataset = IMDBDataset(args.train_file, tokenizer, args.train_max_len)
valid_dataset = IMDBDataset(args.valid_file, tokenizer, args.train_max_len)
unlabeled_dataset = None
if args.do_uda:
unlabeled_dataset = IMDBDataset(args.augment_file, tokenizer, args.train_max_len)
train_results = train(
args, train_dataset, valid_dataset, unlabeled_dataset, model, tokenizer
)
results.update(**train_results)
...
앞서 자세히 설명한 조건에 따라 학습하면 다음과 같은 결과를 도출할 수 있습니다.
| Model | Number of labeled examples | Error rate (Paper) | Error rate (this implementation) |
|---|---|---|---|
| BERT | 25,000 | 4.51 | 5.69 |
| BERT | 20 | 11.72 | 29.22 |
| UDA | 20 | 4.78 | 9.98 |
| BERT (task adapted) | 20 | 6.50 | 8.79 |
| UDA (task adapted) | 20 | 4.20 | 8.09 |
이 결과는 논문과는 다르게 batch size를 32로 max token length를 128로 줄여서 실험한 결과입니다. 논문에서는 큰 batch size와 긴 Sequence Length를 하이퍼파라미터로 세팅하고 실험을 진행하였기 때문에 본 실험결과보다 더 좋은 성능을 도출할 수 있었습니다.
결과를 살펴보면 비록 작은 테스트이지만 UDA 방법론을 이용하여 학습했을 때 월등하게 성능이 향상되는 것을 확인할 수 있습니다. 독특하게도 IMDB에 대해 한번 더 pre-training하는 task adapted 모델의 경우 20개의 sample Fully Supervised Learning을 진행했을 때 눈에 띄는 성능 향상이 있다는 것을 확인할 수 있습니다.
개인적으로 여러번 실험을 반복한 결과 IMDB 데이터에 한번더 pre-training한 task-adapted 모델은 다양한 하이퍼파라미터에서 비슷한 결과과 도출됩니다. 반면 task adapted를 하지 않은 모델(bert-base-uncased)은 파라미터에 큰 영향을 받는 것을 확인할 수 있습니다. 즉 UDA 방법론을 안정적이게 활용하기 위해서는 task adapted pre-training은 필수적이라고 보여집니다.
결론
UDA 방법론은 unlabeled 데이터를 함께 사용한다는 점에서 매우 유용합니다. 하지만 대부분의 Semi-supervised Learning이 그렇듯 하이퍼파라미터에 매우 민감합니다. 학습이 매우 불안정하여 학습 도중에 발산하기도 하고 동일한 파라미터이더로 학습하더라도 seed에 따라 성능이 매우 다릅니다. 초기 20개의 sample에 따라 모델의 성능차이도 존재합니다. 따라서 이 방법론을 유용하게 사용하기 위해서는 하이퍼파라미터 탐색에 많은 시간을 투자해야 할 것 같습니다.
[UDA Pytorch] 에서 튜토리얼에서 구현한 전체 파일을 제공하고 있습니다. 해당 Github를 방문하시어 구현물 전체 모습을 확인바랍니다.
Reference
- [BLOG] Maximum Likelihood Decoding with RNNs - the good, the bad, and the ugly
- [BLOG] 정보이론(information theory) 관점의 cross-entropy
- [PAPER] Unsupervised Data Augmentation for Consistency Training, Qizhe at el, NIPS 2019
- [GITHUB] Unsupervised Data Augmentation Tensorflow Implementation